データフロープログラミング言語が並列ハードウェアのプログラミングに最適な理由
概要

この技術資料では、データフロープログラミング言語が並列ハードウェアのプログラミングに最適な理由について説明します。
内容
データフロープログラミングの概要
データフロープログラミングモデルは、Cなどの言語で実装されている制御フローモデルと異なります。
C言語で作成されたアプリケーションは、トップダウン逐次プログラミング方式であるため、並列ハードウェアへのマッピングに制約があります。それに対し、データフローモデルでは、複数のブロックダイアグラムにより論理実行フローを表現できるため、並列処理を簡単に表すことができます。ブロックダイアグラムのノードが必要なすべての入力を受け取ると、出力データが生成され、そのデータはデータフローの次のノードに渡されます。ノードを介したデータの移動は、ブロックダイアグラム上の関数の実行順序を決定します。
LabVIEWにおける並列タスクの作成例
LabVIEWでプログラムを作成すると、タスクの並列化を簡単に行うことができます。LabVIEWのマルチスレッド実行システムの利点を生かした例を以下に示します。この例には、イベント駆動型UIタスクと周辺デバイスから集録を行うタスクの2つの並列タスクがあります。LabVIEWは2つのループを個別に実行可能であり、多くの場合マルチプロセスまたはハイパースレッドの動作環境で同時実行できます。
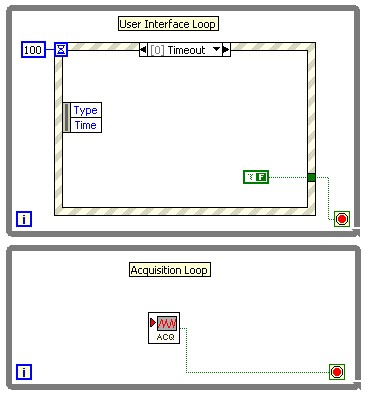
図1. LabVIEWにおける暗示的な並列化
上記の例には、明示的なスレッド管理のためのコードは含まれていません。LabVIEWのデータフロープログラミングのパラダイムにより、実行システムは2つのループを異なるスレッドで実行することができます。テキストベースのプログラミング言語の多くは、スレッドを明示的に作成して処理する必要があります。
LabVIEWはまた、明示的なスレッド処理を行うために並列ハードウェアリソースにコードをマップする特殊なストラクチャを提供します。たとえば、このようなストラクチャの1つにタイミングループがあります。タイミングループに含まれるコードがデュアルコアまたはマルチコアシステムで実行されると、固有のスレッドが作成されます。以下の図2は、2つのタイミングループがマルチコアシステムにおいて2つの異なるコア間で平衡状態を保つことができる2つの固有スレッドを作成する方法を示します。
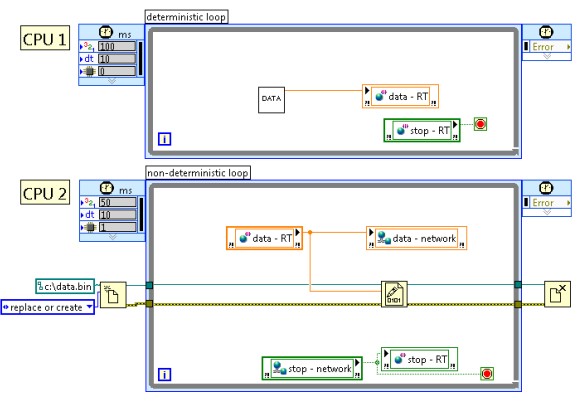
図2. LabVIEWにおける明示的な並列化
FPGAではスレッドの概念が存在しないため、ループストラクチャが代わりにFPGAの構成で領域を予約し、固有なプロセッサコアとして実行されます。
つまり、データフロープログラミング言語は本質的に並列であるため、暗示的に並列なアプリケーションを作成できます。このような特性により、マルチコアプロセッサやFPGAなどの並列ハードウェアにおける低レベルプログラミングに時間をかけることなく、LabVIEWコードを並列化でき、パフォーマンスを向上させることができます。