NI does not actively maintain this document.
This content provides support for older products and technology, so you may notice outdated links or obsolete information about operating systems or other relevant products.
この技術資料では、マルチコアプログラミングの難題について解説します。具体的には、ソフトウェアアーキテクチャに適用可能な各種マルチコアプログラミングパターンについて説明します。
プログラミングパターンに関しては複数の書籍で解説されていますので、本ドキュメントでは下記の概念について紹介するとともに、それらがLabVIEWにどのように適用されるかを説明します。
ソフトウェアアーキテクチャの視点で、アプリケーションの問題に最適な並列パターンを組み込むようにします。適切なパターンを選ぶには、アプリケーションの特性とハードウェアアーキテクチャについて検討する必要があります。
さらに、上記のパターンに関連して、通常のWhileループ、フィードバックノード、シフトレジスタ、タイミングループ、並列ForループなどさまざまなLabVIEWストラクチャについても紹介します。
タスクの並列処理とは、最もシンプルな形の並列プログラミング方法で、アプリケーションを互いに依存せず異なるプロセッサ上で実行可能な固有のタスクに分割するものです。ループAが信号処理ルーチンを、ループBがユーザインタフェースの更新を実行するという、2つのループを持つプログラムについて考えてみます。これは、マルチスレッドアプリケーションが複数のCPUを利用して、2つのループを別々のスレッドで実行するタスクの並列処理であると言えます。
LabVIEWでタスクの並列処理を行うには、ブロックダイアグラム上にコードの並列部分を作成します。LabVIEWで並列処理を行う場合、コードの並列部分が視覚的に表示され、個々のタスクを簡単に切り離すことができるというメリットがあります。また、LabVIEWではアプリケーションが自動でマルチスレッド化されるため、スレッド管理やスレッド間の同期について気にする必要がありません。
大量のデータセットに対しデータの並列処理を行う場合は、大きな配列やマトリクスをサブセットに分割し、操作を行って、結果を統合します。
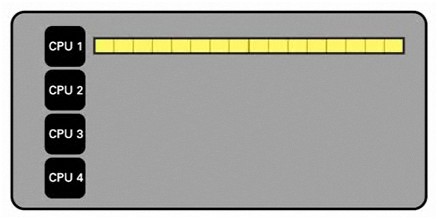
まず、1つのCPUが全てのデータセットの処理を試みる逐次処理について考えてみます。
図1. 1つのCPUによる処理
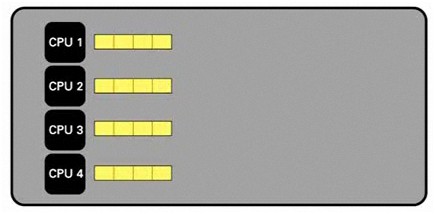
次の例では、同じデータセットが4つの部分に分割されています。このデータセットを使用可能なコア間で分けることで、速度を大幅に向上せさることができます。
図2. 複数のCPUによる処理
制御システムといったリアルタイムのハイパフォーマンスコンピューティング(HPC)アプリケーションでは、かなりサイズの大きい行列ベクトル積を並列実行するのが効率の良い一般的な方法です。一般に、マトリクスは固定されていますので、前もって分解しておくことができます。センサによって集められた計測結果は、ループごとのベクトルを提供します。例えば、行列ベクトルの結果によって、アクチュエータを制御することができます。
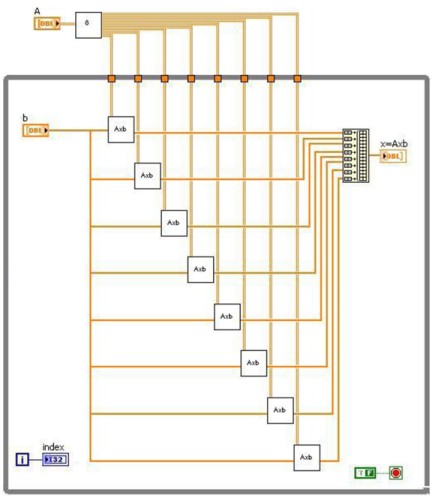
以下のブロックダイアグラムは、8つのコアに分散された行列ベクトル積を示しています。
図3. LabVIEWにおける行列ベクトル積
このブロックダイアグラムは左から右に実行するようになっており、下記の手順を実行します。
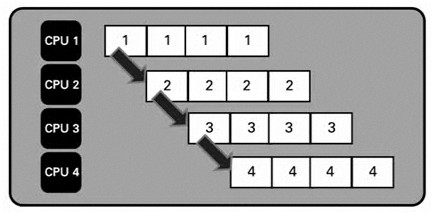
パイプライン処理は、アセンブリラインに似ています。ストリーミングアプリケーションや、演算負荷の高いアルゴリズムを逐次的に変更する場合など、個々の手順に多くの時間がかかるアプリケーションでの処理について考えてみます。
図4. アルゴリズムの逐次的ステージ
アセンブリラインと同様、各ステージで1単位の作業を行います。それぞれの結果は次のステージに送られ、最後のステージまでそれを繰り返します。
マルチコアCPUで実行するアプリケーションに対しパイプライン処理を行う場合は、アルゴリズムをほぼ同じ作業単位のステップに分け、各ステップを異なるコア上で実行します。アルゴリズムは、複数のデータセットや連続的にストリーミングするデータで反復できます。
図5. パイプライン処理方式
重要なのは、それぞれのステップにかかる時間が均等になるようにアルゴリズムを分割することです。その理由は、個々の反復に最も長いステップと同じ長さの時間がかかるためです。例えば、ステップ2が実行に1分かかり、ステップ1、3、4がそれぞれ10秒かかる場合、その反復にかかる時間は1分ということになります。
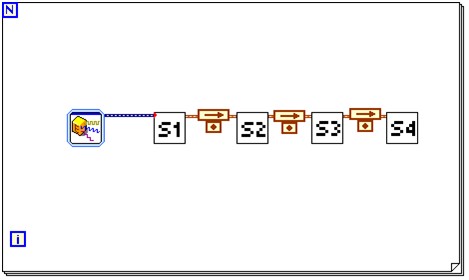
図6に示すLabVIEWブロックダイアグラムは、パイプライン処理の例を示しています。表示されるForループは黒い枠で、ステージS1、S2、S3、S4が含まれています。これは逐次的に実行するアルゴリズムの関数を示しています。LabVIEWは構造化されたデータフロー言語なので、各関数の出力はワイヤを通って次の関数の入力に渡されます。
図6. LabVIEWでのパイプライン処理
小さいドットの上に、フィードバックノードが矢印で表示されます。フィードバックノードは、関数が異なるパイプラインステージに分割されていることを意味します。同じコードをパイプライン処理しない場合、見た目は似ていますがフィードバックノードがありません。このテクニックがよく用いられる例としては、高速フーリエ変換(FFT)で一度に1ステップずつ操作が必要なストリーミングアプリケーションがあります。
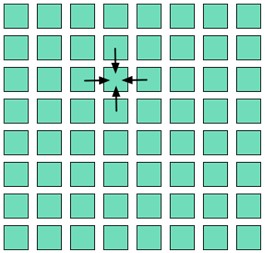
物理モデルが関係する多くの演算では、構造格子パターンを使用します。このパターンでは、各反復で2D(ND)クリッドを計算し、アップデートされた各格子値は、図8に示すようにその隣接格子の関数となります。
図7. 構造格子
構造格子の並列バージョンでは、格子をサブ格子に分割して各サブ格子を個々に実行します。ワーカー間の通信は、隣接格子の幅情報のみになります。並列処理効率は、面積の周囲の長さに対する比の関数となります。
例えば、下図のブロックダイアグラムは、境界条件が常に変化する熱伝導方程式を解くことができます。
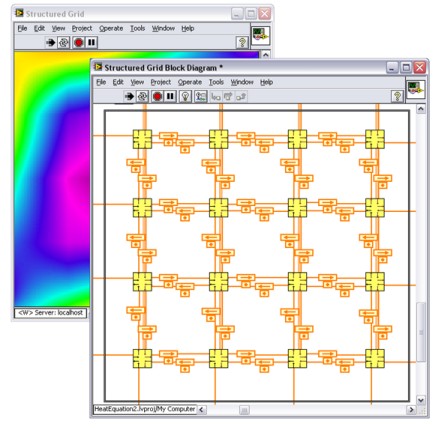
図8. LabVIEWでの構造格子
表示される16個のアイコンは、特定の格子サイズのラプラス方程式を解くことのできるタスクを表しています。ここでラプラス方程式は熱伝導方程式を解くためのものです。16個のタスクは、16個のコアにマッピングされます。それらのコアは、1回のループ反復ごとに境界条件を交換し、このプロセスによりグローバル解が得られます。小さいドットの上に矢印で表示されるフィードバックノードは、要素間のデータのやり取りを表します。また、そのようなブロックダイアグラムは、1、2、4、8個のコアを搭載したコンピュータにマッピングすることもできます。さらに多くのコアを搭載したコンピュータにも、同様の手法が利用できます。
Whileループとは、様々なプログラミングパターン(タスク並列性、データ並列性、パイプライン処理、構造グリッド)に使用できる基本ストラクチャです。パターンによっては通常のWhileループで十分ですが、状況によっては特別なタイプのWhileループ(タイミングループなど)の方が適している場合もあります。
上述のフィードバックパイプライン処理では、シフトレジスタまはたフィードバックノード(ここではどちらも同じ動作をします)を使用する必要があります。
並列Forループを使用すると、コードを実行する並列“ワーカー”の数を自動で設定して、暗黙的な並列性を実現できます。各プロセッサコア用にワーカーを作成することで、最大限の並列実行が行えます。
並列Forループは、反復間での依存性がなく、ループで何度も繰り返し実行する必要のある高負荷の操作には有効な方法です。ただし依存性がある場合は、逐次的に実行することが想定されていると考えられるため、並列Forループを使用すべきではありません。その場合は、パイプライン処理によって並列性を確保することができます。
タイミングループは、マルチコアハードウェア構成に基づいてパフォーマンスを最適化するのに役立つ特殊な特性を備えたWhileループの1つです。例えば、通常のWhileループがマルチスレッドを扱うのと異なり、タイミングループ内のコードは全てシングルスレッドで実行します。これは直観に反した方法のように見えるため、マルチコアシステムでのシングルスレッドの実行が望ましい理由がわからない人も多いでしょう。具体的には、これはリアルタイムシステムの便利な特性であり、キャッシュの最適化が重要な部分です。シングルスレッドで実行する以外にも、このループではプロセッサ親和性を設定することができます。これは、スレッドを特定のCPUに割り当てる(そしてキャッシュを最適化する)ためのメカニズムです。
通常のWhileループ内で問題なく動作する並列パターン(データ並列性やパイプライン処理など)は、シングルスレッドでは並列実行ができないため、タイミングループでは動作しません。ただし、例えば複数のタイミングループならそのようなテクニックも実行できます。パイプライン処理では1つのタイミングループがパイプラインの固有のステージを表し、ループ間でFIFOによりデータ転送が行われます。
複数のループ間でデータを同期するのに重要なのが、キューです。例えば、生産者/消費者アーキテクチャの実装に使用できます。生産者/消費者アーキテクチャは並列プログラミングに固有のものではなく、むしろ一般のプログラミングアーキテクチャであるため、本ドキュメントでは特に触れていません。ただしマルチコアCPUでもCPUの消費量を減らすのに非常に役立ち、ループとキューを併せて使用することで全て可能となります。
キューを用いてループ間でデータを共有する場合、リアルタイム性がありません。リアルタイム性が要求される場合は、RT FIFOを使用してください。
LabVIEW Real-Time固有の機能として、CPUを特定のスレッドプール用に“予約”できるCPUプールVIがあります。これもキャッシュ機能を最適化するためのメカニズムです。
例えば、何度も繰り返し極力短時間で実行することを目的としたアプリケーションをクアッドコアシステムで実行することを想定してみてください。データセットがCPUキャッシュに納まるサイズであると仮定して、このような操作はキャッシュで実行するのに最適です。実際にキャッシュでの操作は、コードを並列化して4つのCPU全てを使用するよりも効果的かもしれません。そのため、4つのCPU全て(0-3)で並列タスクを実行するようOSをスケジューリングするのではなく、CPU 0と2のみというように、OSスケジューラで2つのCPUだけを予約することもできます。(クアッドコアにはたいていCPU 0と1の間に大きな共有キャッシュがあり、CPU 2と3の間にも大きな共有キャッシュがあります。)CPUを予約することで、確実にデータがキャッシュ内に残り、2つの大容量の共有キャッシュを全てその操作に使用できるようになります。
CPU情報VIは、LabVIEWアプリケーションが実行しているシステムに関する特定の情報を提供するものです。この情報は、アプリケーションが多数のコンピュータ(デュアルコア、クアッドコア、オクタルコアなど)に実装される可能性がある場合、特に便利です。
CPU情報VIを使用すると、アプリケーションは「CPUのコア数」などのCPU情報を読み取り、その結果を並列Forループに送り込みます。
例えば、デュアルコアコンピュータ上でアプリケーションが実行している場合、CPUのコア数は2となり、並列Forループの最適数も2となります。これにより、ユーザがCPUコア数を指定しなくても、自動的に使用ハードウェアに最適なコードになります。
トレースは、マルチコアアプリケーションのデバッグとして非常に有効な方法であり、デスクトップシステムでもリアルタイムシステムでも実行できます。デスクトップ実行トレースツールキットとReal-Time実行トレースツールキットの詳細については、製品マニュアルを参照してください。
プログラマは、特定のアプリケーションに適切に対応できるプログラミングパターンを採用することが重要です。本ドキュメントでは、タスク並列処理、データ並列処理、パイプライン処理、構造格子について説明しました。
それらのパターンをフルに活用するには、様々なストラクチャ、VI、デバッグツールを導入して、最適性能を実現する必要があります。