管理性とは
概要
「RASM」とは、機能システムの4つの関連特性、Reliability (信頼性)、Availability (可用性)、Serviceability (保守性)、Manageability (管理性) の頭文字をとったものです。初期のコンピュータ業界で、製品の堅牢性を表すのに、「RAS」 (Reliability (信頼性)、Availability (可用性)、Serviceability (保守性)) という頭字語を初めて使用した企業の1つが、IBM社であると一般的に考えられています[1]。「Manageability (管理性)」の「M」は、信頼性、可用性、保守性を多角的に促進することでシステムの堅牢性を支援する役割があるとして、最近追加されました[7]。例えば管理機能により、予防保守や修理保守の時期を決定しやすくなります。そして、システムの機能停止を突然の予期せぬものから計画的で管理可能なものへと効果的に転換することができるため、より円滑な修理保守の提供やビジネスの継続性、可用性の向上が図れます。一般に、管理性とはシステムの検出、構成、変更、実装、制御、監視のし易さ、応答速度、能力をサポートする基準および一連の機能を示すものです。
ある目的に使用されるシステムの数が増えると、保有資産や設置場所、状態を把握するだけでも、企業や組織の効率に直接的に影響を及ぼします。特にBig Analog DataTM [5]ソリューションが普及するようになると、ネットワーク接続された多くのシステムは、適切なタイミングでエラーを起こさずにアップデートやメンテナンスを実施することが難しくなります。また、例えばシステムがトンネル内や構造物の高い場所など遠隔地にある場合は、設置場所に移動するだけでも労力とコストがかかるため、ビジネスにマイナスの影響を与えます。そのような状況でも、管理性が考慮されていれば、効率性を向上でき、所有コストとシステム運用コストを抑えることができます。
内容
管理機能
システムの主要管理機能は、図1に示すように、4つの大きなカテゴリに分類することができます。管理コンソールを用い、ソフトウェア的にAPI経由で、また物理的に管理ネットワーク経由で管理対象システムに接続し制御します。
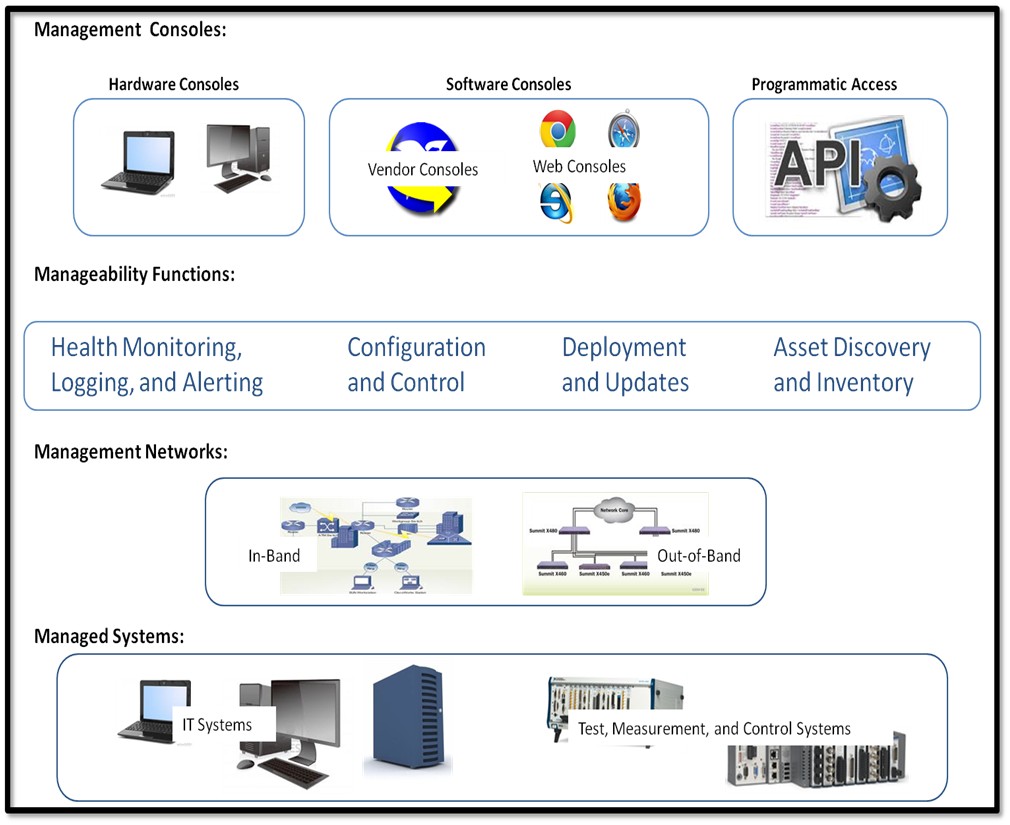
図1.システム管理インフラストラクチャ
管理機能は4つの大きなカテゴリに分類されます。
- ヘルスモニタリング、ロギング、アラート―これらの機能は、システムが本来の機能を実行する能力を追跡します。ロギングにより活動の履歴が記録されますので、故障に関する貴重な情報が得られます。アラートスキームは、診断やインターロックに基づく予知警告から、故障の発生時や監視パラメータ (電圧や温度など) がしきい値を超えた際の警報音まで、さまざまなものがあります。また、システムが障害を起こしたりハッカーやマルウェア、ウイルスなどの攻撃を受けた場合にアラートを設定することもできます。
- 構成と制御―システムを正しくセットアップし構成することは、最大限の性能と可用性を実現する上で重要です。システムによっては定期的な制御やリアルタイム制御が必要なため、適切な「ノブ」やアクチュエータが利用できることが基本要件です。主要なセットアップ/制御アクティビティにより、システムのセキュリティが設定されますので、権限のあるアクセスのみに限定し悪意のあるアクティビティから保護することができます。
- 実装とアップデート―ソフトウェアスタックなどのシステムリソースを効率的に自動で実装できれば、特に多くのシステムを管理する必要がある場合に有益です。システムを初めて設置する際に実行されるほか、システムの耐用年数の中でパッチ、性能、機能アップデート時にも実行されます。
- 資産の検出とインベントリ―多くのシステムがネットワーク上や遠隔地にある場合、(通常、最初のインストール時、またはソフトウェアやファームウェアの更新時に) 正確かつタイムリーに検出することがさらに重要です。また、精度の高い自動インベントリ管理システムも、資産管理、経費管理、システム交換には不可欠です。
テスト、計測、制御用途では、高速・高品質の計測と解析を実現するためにPXIシステム[8]を実装することができます。そのため管理機能によってアップタイム、テスト速度、保守性を最大に高めることができます。同様に、組込システム[9]は、データ収集/組込制御アプリケーションに使用できますが、管理機能を利用することによって、それらのシステムのヘルスとステータスをリモートで監視・制御することが可能となります。
管理性の操作モード
管理機能は、インバンド管理とアウトオブバンド管理の2つのモードで動作します。インバンド管理とは、システムの主目的に使用されるメインのOSに関連し、OSによって認識され、OSに依存する運用範囲のことです。つまり、管理機能は「完全オン」のシステム状態で動作します。アウトオブバンド管理は、メインOSやシステムの主目的に使用される他のコンポーネントとは無関係な運用範囲のことです。そのためアウトオブバンド管理は、低電力状態などさまざまなシステム状態で実施することができます。厳密なアウトオブバンド管理では、図1に示す専用管理ネットワークが使用されます。
インバンド管理では、メインのシステムコントローラまたはCPUコンプレックスとオペレーティングシステム (OS) を使用して、システムを管理します。メインOSは、ベースとなる管理インフラ、管理ソフトウェア、デバイスドライバ、構成フレームワークなどのランタイム環境を提供します。インバンド管理ではOSがフルに利用できるため、一般に比較的低コストで充実した管理機能のセットを提供することができます。インバンド管理によってさまざまな機能が利用できますが、主電源が入っていなかったり、メインOSやCPUコンプレックスが稼働していない場合は、システムを管理することができません。そのような場合、より厳密なシステム管理環境を提供するアウトオブバンド管理が必要となります。
アウトオブバンド管理では、システムのメインCPUコンプレックスとOSに依存しない専用の管理/サービスプロセッサを使用します。一般に、アウトオブバンド管理の場合、外部管理コンソール (ワークステーション) が管理プロセッサまたはサービスプロセッサに設置されたネットワークインタフェース経由でシステムをリモート管理します。管理/サービスプロセッサは、低電力 (「オフ」) システム状態を含むあらゆるシステム電源状態で利用することができます。またメインコントローラとOSの状態に関わらず、システムを管理できます。インバンド管理に必要なメインシステムのCPUコンプレックスに頼る必要がないため、アウトオブバンド管理ならメインのCPUコンプレックスをシステム内の管理対象の1つとみなすことが可能です。それによりインバンド管理にまつわる「キツネに鶏小屋の番をさせる」ような状況を避けることができます。さらに、アウトオブバンド管理では管理機能がメインのCPUコンプレックスの外で行われるため、CPUは管理タスクに煩わされずにシステムの主目的のためだけに稼働させることができます。これはリアルタイムの高速高精度の計測・制御アプリケーションで特に効果があります。
ライフサイクルの各段階における管理性
図2に示すバスタブ曲線について考えてみます。この曲線は、その形状から名付けられており、システムまたは製品の経時的な故障率を示しています。製品寿命は4つの期間、つまり準備期、初期故障期、偶発故障期、摩耗故障期に分けることができます。システムを管理し、故障を防止するとともに対処し、必要に応じてシステムを交換するには、段階ごとに異なる点に配慮する必要があります。
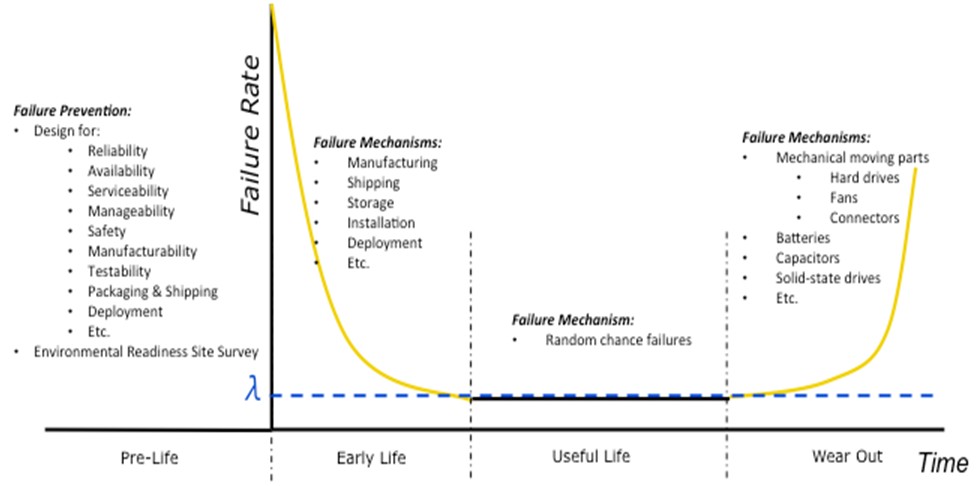
図2.バスタブ曲線
第1段階:準備期
「計画のない目標は、ただの願い事にすぎない」
―アントワーヌ・ド・サン=テグジュペリ
準備期で重視されるのは、計画と設計です。システム設計とアクセス性は、システムの所有と管理のしやすさおよびコストに大きな影響をもたらします。適切な設計を行うには、以下に示すようなシステムの使用モデルの主要事項について理解しておく必要があります。このリストは包括的ではありませんが、より一般的な考慮事項が含まれています。
- 最も起こりやすい故障モードと必要なシステム可用性
- インバンド対アウトオブバンドの管理に対して、管理タスクがシステムの目的遂行に干渉する量
- システムの目的遂行に必要なリアルタイムシステムの制御と自動操作のレベル
- ネットワーク接続するシステムの数とネットワークトポロジ
- ソフトウェアの種類と数およびアップグレードの頻度
- システムの更新/交換戦略
- 管理コンソールとユーザインタフェースの要件
- システムの物理的位置と周辺環境要因
システムが稼働する環境も、管理性には大きな影響をもたらします。例えば、電子機器に適さない環境にシステムを設置する場合、温度、湿度、電力計測などの必要な環境パラメータを全て正確に捉え監視するのは難しいかもしれません。あるいは、診断と監視は極めて手間のかかる作業で、システムの目的遂行や人件費に悪影響があるかもしれません。システムの設置と実装の前にEnvironmental Readiness Site Survey (ERSS) の調査を行っておくと、そのような要素を効果的に評価できるほか、求められる管理性を実現するのに環境がどのように影響するかを理解することができます。
第2段階:初期故障期
初期故障期における管理性には、システムの設置、実装、極力短期間での安定運用への移行などが含まれます。システムが物理的に設置され接続されると、検出、構成、ソフトウェアの実装、校正、資産インベントリのセットアップ、監視といった管理タスクが実施されます。
初期故障期の故障率は一般に偶発故障期に比べ高いため、システムの機能や環境要因のテストとモニタリングを重視する必要があります。製造に移行する前に、システムの本来の目的に関連した機能とモニタリング/管理対象としての基本機能の両方について、徹底したエンドツーエンドテストを実施することが不可欠です。リモートアクセスやエラーログといった優れた計画/管理ツールを使用することで、完全かつ効率的なテストが可能となります。それによりソリューションの「統合リスク」を減らしシステムの価値を高めることができます。 どちらのメリットも完成したシステムの満足度に大きく貢献するものです。
第3段階:偶発故障期
偶発故障期の安定的な通常運転に入ると、ヘルスモニタリングやエラーロギング、インベントリ/ステータス管理といった主要管理機能が日常的な作業となります。また、必ず必要となるソフトウェアやハードウェアのアップグレードも管理する必要があります。そしてそれは保守機能によって実行されます。
偶発故障期における故障は「ランダムな偶発故障」と考えられており、一定の故障率があるので、管理機能はそれらに合わせて調整できます。つまり、診断および予防保全スケジュールは、故障率、故障モード、交換計画に基づいて作成されるということです。
堅牢な管理ツールには、「ウォッチドッグ」関数、厳密なセルフテスト、予測ツールを利用して、ヘルスモニタリングに連動する故障アラート機能も搭載されています。
また管理ソリューションには、定期ソフトウェアアップデートを実行するメカニズムも必要です。ターゲットは現場に設置され、初期故障期終了後に見つかった問題に対応したり、現行のセキュリティアップデートを提供します。 さらに、偶発故障期ではマイナーアップデートを実施して、システムの機能や効率性を高めることもできます。 ソフトウェアアップデートメカニズムでは、アップデートをターゲットに適用する前に、ターゲットの状態とアップデートの重要度を考慮する必要があります。 重要なアップデートは、現在の運転を中断してでも直ちに適用する必要がありますが、マイナーアップデートは計画的ダウンタイムやメンテナンス期間のみで行って、可用性を最大限に高める方がよいでしょう。 さらにアップデートメカニズムは、ターゲットの既存の構成を維持する設計にする必要があります。そうすれば、システムの再設定に手間がかかりません。
システムには、タスクの稼働中に実行する制御関数やハードウェア校正が必要となることがあります。例えば、テストシステムでは計測のタイミングを調整したり、特定のテストを繰り返したり停止したりすることが必要になる場合があります。偶発故障期に実行されるそのような制御ルーチンは、手動、自動、または両方の組み合わせのものがあります。それらの制御アクション自体もモニタリングして、正しく機能していることと、意図する結果が生成されていることを確認する必要があります。
第4段階:摩耗故障期
摩耗故障期は、システムの故障率が偶発故障期の「基準」を上回るようになる頃が始まりです。この故障率の上昇は、基本的に部品の摩耗 (老化) が原因と推測されます。ファン、ハードドライブ、スイッチ、リレー、頻繁に使用するコネクタなどの機械的回転部品が通常最初に故障します。ただし、バッテリやコンデンサ、ソリッドステートドライブといった電気部品が最初に故障する場合もあります。ほとんどの集積回路 (IC) や電子部品は、仕様内での通常使用なら約20年[6]稼働します。
摩耗故障期では、大きな負荷となるのが管理性と保守性です。そのためこの段階では、一般的に保守と修理が増え、システムが正式に交換されることになります。システムの交換が必要となると、ここで重要になるのは、移行に向けて旧システムの状態を維持し、資産インベントリからシステムを削除して、新システム (資産) を追加するという管理機能です。さらに、初期故障期と偶発故障期におけるシステムのエラー、故障、保守の履歴を優れた管理ツールで特定し残しておくと、次世代システムの管理計画を立てる際に貴重な情報となります。
まとめ
管理性は、従来の信頼性、可用性、保守性に追加された重要な要素です。テスト、計測、制御システムに管理機能を組み込むことで、システムのライフサイクル全般にわたり多くの利点が得られます。管理性の導入にあたっては以下を考慮します。
- 準備期の計画と設計は、管理性の問題に重点的に取り組み、管理コンソールの内部システムセンサ、診断、ネットワーク接続機能を確認する絶好の機会です。
- システムとサブシステムの実装場所とアクセスレベルを把握することは極めて重要です。
- アウトオブバンド管理では管理機能がメインのOSとCPUコンプレックスの外で行われるため、管理タスクに煩わされずにCPUをシステムの主目的のためだけに稼働させることができます。
- 管理機能によって欠陥部品が特定しやすくなるため、平均復旧時間 (MTTR) と保守性が大きく改善され、最終的にはシステムの可用性にも影響を及ぼします。
- エラーログ、資産インベントリ、保守履歴を保持しておくと、交換後のシステムの管理計画を立てる際に役立ちます。
関連情報
[1] “Design and Evaluation,” 3rd ed., by Daniel P. Siewiorek and Robert S. Swarz, Reliable Computer Systems (A K Peters/CRC Press, 1998).
[2] “The Certified Reliability Engineer Handbook,” 2nd ed., by Donald W. Benbow and Hugh W. Broome, ASQ Quality Press, Milwaukee Wisconsin, 2013, ISBN 978-0-87389-837-9, Chapter 13, page 227.
[3] “Reliability Theory And Practice,” by Igor Bazovsky, Prentice-Hall, Inc.1961, Library of Congress Catalog Card Number:61-15632, Chapter 5, page 33.
[4] “Practical Reliability Engineering,” 5th ed., by Patrick D. O’Conner and Andre Kleyner, Wiley, ISBN 978-0-470-97981-5, Chapter 16, page 410.
[5] “The Moore’s Law of Big Data”, http://zone.ni.com/devzone/cda/pub/p/id/1649
[6] “Telcordia Technologies Special Report, SR-332,” Issue 1, May 2001, Section 2.4, pages 2-3.
[7] "What is RASM?", http://www.ni.com/white-paper/14410/en
[8] "What is PXI?", http://www.ni.com/pxi/whatis/
[9] "What is CompactRIO?", http://www.ni.com/compactrio/whatis/および"What is NI CompactDAQ?", http://www.ni.com/compactrio/whatis/