Reliability(信頼性)とは?
内容

概要
「RASM」とは、機能システムの4つの関連特性、Reliability(信頼性)、Availability(可用性)、Serviceability(保守性)、Manageability(管理性)の頭文字をとったものです。初期のコンピュータ業界で、製品の堅牢性を表すのに、「RAS」(Reliability、Availability、Serviceability)という頭字語を初めて使用した企業の1つが、IBM社であると一般的に考えられています[1]。「Manageability(管理性)」は、信頼性、可用性、保守性を多角的に促進することでシステムの堅牢性を支援する役割があるとして、最近追加されました。RASMの特性は、テスト、計測、制御、実験用のシステムの目的や、関連するビジネス目標に大きな影響をもたらす可能性があります。
信頼性は、信用に関わるもので、我々の生活において極めて重要な部分です。何かを使用する時、本当に想定通りに機能すると信用できますか?自分の車を信用できなければ、途中で故障する可能性を恐れて長距離運転はしないでしょう。別の信頼できる車を使うか、他の交通手段を選ぶはずです。信頼性がない製品は人々に信用されず、信用できるものが代わりに使われます。航空機や自動車のブレーキ装置、加熱・冷却装置といった命に関わる可能性のあるものはもちろんですが、重要性の低いシンプルな製品でも、我々は同じことを考えます。2回に1回しか動かないパワードリルや、時折停止する携帯電話を使い続けられるでしょうか。さらにそのような製品は、最も必要な時に限って故障する印象があります。信頼性は全ての人にとって重要なのです。
工学分野における信頼性の本質は、複雑な機械システムが不可欠となった第二次世界大戦時の米軍にまでさかのぼります。信頼性に関するリスクをよく理解し、リスクを減らすためのプランニングを慎重に行うことが目的達成の鍵となります。つまり、信頼性とはリスク管理が全てです。
信頼性工学では、確率と統計学の知識を活用して、一定の環境条件下にある製品の信頼性を評価し予測することができます。産業界で実施されている継続的改善プロセスを導入して製品の信頼性を高めるとともに、実用性のある昔ながらのテクニックを開発や製造に適用することで、信頼性の向上を実現しています。
「信頼性とは、結局のところ、最も実用的な形のエンジニアリングである。」
元米国防長官 - ジェームズ・R・シュレシンジャー
信頼性の定義
信頼性
信頼性の定義は、一般向けのものから科学的なものまで様々です。科学的定義には、3つの基本要素があります。それは、一定の時間、一定のサイクル数、または特定の環境での成功確率です。
このホワイトペーパーでは、「デバイスまたはシステムがある環境で特定の期間故障することなく期待通りに機能する確率」という定義に基づいて考察します。
ライフサイクルの各段階における信頼性
図1に示すバスタブ曲線について考えてみます。この曲線は、システムまたは製品の稼働時間に対する故障率を示しています。製品のライフサイクルは、Pre-Life(準備期)、初期故障期、偶発故障期、摩耗故障期の4つの期間に分けることができます。故障の理由とメカニズムは期間によって異なります。予期せぬタイミングでの故障を防ぐため、それぞれの期間で異なる点について考慮する必要があります。故障メカニズムの例を図1に示します。
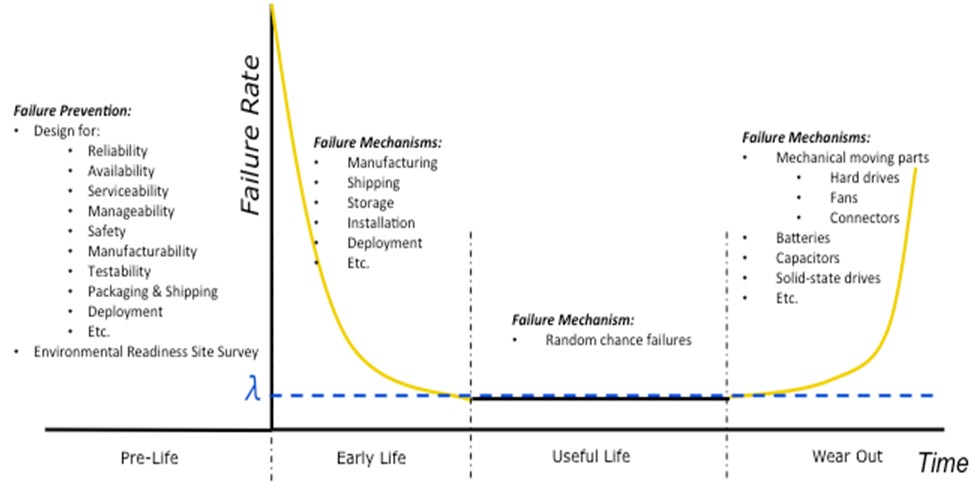
図1. バスタブ曲線
第1段階:Pre-Life
人々は失敗を計画するのではなく、計画をしないから失敗するのだ。
- ベンジャミン・フランクリン
Pre-Lifeで重視されるのは、プランニングと設計です。システムの設計は信頼性に最も大きく影響します。しかし適切な設計を行うには、システムが必要とする信頼性のレベルを把握する必要があります。
どの程度の信頼性が必要かを特定するには、包括的ではありませんが主なものを以下に列記しています。
故障のコスト
検討すべき要素としてはこれが最も根本的なものです。しかし、システムの故障によるコストが十分に理解されていないことも少なくありません。この情報により、システムの開発にどの程度の時間を費やせるか、どの程度の信頼性が必要で、どの程度の信頼性を妥協するかを判断することができます。故障のコストを評価するには、以下について考慮します。
故障のコスト = 修理コスト + ダウンタイムのコスト + 損害のコスト
- 修理コストには、修理自体のコスト、部品交換のコスト、および人件費が含まれます。
- ダウンタイムのコストには、生産/販売ができなかった分のコストや、従業員/顧客が職務を行えなかったコストが含まれます。
- 損害のコストには、人体や環境、他の機器や製品などへの二次的被害に関連する全てのコストが含まれます。
環境
環境は、システムの信頼性に多大な影響を与えます。以下の環境要因について考えてみます。
- システムの電源の品質
-
- 接地の不良
- 浮動中性点
- 電圧サージ/スパイク
- 一時的な電力不足
- 電圧低下
- 停電
-
- 温度レベル/サイクル
- 衝撃/振動パターン
- 汚れ/ほこり
- 湿度
- 配線
-
- 常時接続されますか? それとも頻繁に切断/再接続を行いますか?
- 固定されていますか?
-
- 人的要因と使いやすさ
-
- マンマシンインタフェース(MMI)は信頼性と安全性に多大な影響を与えます。
- システムは人の多いエリアで使用されますか?
- システムの設置場所は誤ってぶつかったり蹴られたりしやすいですか?
- オペレータはシステムをどのように操作しますか? ローカル、リモート、それとも両方ですか?
- オペレータは高い技術を持つ人ですか?それとも技術的に未熟で訓練を受けていない人ですか?
- システムの重要部分のセキュリティとアクセス性はどの程度ですか?これには様々なレベルで賛否両論があります。例えば、アクセスしやすくセキュリティが低ければ、修理にかかる時間は少なくすみますが、技術的に未熟な人員が本来すべきでない調整や修理を行おうとする可能性があります。
-
- 腐食性薬品、塩水など
- 高度
- 高エネルギー放射
- 電磁放射
システムの設置と実装の前にEnvironmental Readiness Site Survey(ERSS)を実施すると、そのような多くの要素を効果的に評価できるため、システム全体の信頼性を高めることができます。
使用プロファイル
このプロファイルは、信頼性に大きく影響する以下の要素を評価するもので、信頼性と可用性を評価する際に考慮する必要があります。
- システムがダウンタイムにならずに稼働する必要のある時間
- 稼働中の作業負荷
- 定期メンテナンス/計画的ダウンタイム
-
- 使用頻度
- 持続期間
-
- 人間がシステムにアクセスできる場合、その頻度はどれくらいでしょうか?例えば、南極に設置されているシステムや高放射能環境では、アクセスできるとしても1年に1回程度でしょう。無人火星探査機に搭載されたシステムは全くアクセスすることができませんが、工場に設置されたテストシステムならほとんどいつでもアクセスすることができます。
その他の注意事項
製造のしやすさ—作製しやすいシステムは、一般に生産性が高く、初期故障が少なく、高い信頼性を備えています。
テストのしやすさ—テストしやすいシステムは、より徹底したテストが可能なので、初期故障期の故障が少なくなり、修理にかかる時間が短縮されるほか、偶発故障期においてより効果的なメンテナンスができます(高可用性)。
梱包—適切な梱包は出荷や保管時に生じる損害を減らすのに極めて重要です。また、初期故障も少なくすることができます。
システムの検証と妥当性確認(V&V) - 可能であれば、システムが実際に導入される環境で、実際の使用プロファイルを使用してシステムの検証と妥当性確認を実施します。実世界の周辺環境は複雑なので、完全にモデル化し予測することは不可能です。天気予報と同じように、精度は高まっているものの、予測モデルにはまだ誤差があります。システムが動作するかどうかは、実際に試すまでわからないのです。
これらの要素を全て調べることで、システムのリスクや信頼性設計要件が特定できるほか、システムに最適なコンポーネントを選ぶのにも役立ちます。
第2段階:初期故障期
初期故障期は、一般的に故障率が通常より高くなります。このような初期不良は、システムを最大負担の状態で長時間テストすることによって顕在化させることができます。これは通常システムの実装前に行われます。初期故障期の問題は、多くの場合製造欠陥や製造時に検出されなかった不良部品、出荷・保管・設置時の損傷が原因とされます。それらの問題が解決されると、初期故障率は急激に低下します。
初期故障は、無駄な時間とコストを費やすことになるため、システムの品質に対する第一印象が悪くなります。そのため実装の完了と製造システムの稼働開始の前に、意図した用途に従って実際のターゲット環境でテストする必要があります。初期テストでは、基本的に欠陥製品がないことを確認します。メーカーは各製品の最終的な検証テストを出荷前に実施しますが、出荷後の最終検証テストや製造環境でもシステム全体のテストを行うことはできません。潜在的な製造欠陥が製造テストで見逃されるだけでなく、製品は出荷、保管、設置、または実装時にも損傷することがあります。
第3段階:偶発故障期
偶発故障期とは、システムの初期問題が解決され、通常動作が安定的に行えると信頼される期間です。この期間内に起こる故障は「ランダムな偶発故障」と考えられており、一定の故障率があります。製品ライフサイクルが摩耗故障期に入るまでの期間が偶発故障期です。
偶発故障期で、信頼性、可用性、保守性、管理性(RASM)エンジニアリングの概念を適用します。故障率“λ”または平均故障間隔(MTBF)は、以下のように一定とみなします。
[2]
ハードドライブのMTBFが100万時間(100年超)でありながら、3~4年使用すると故障の可能性が出てくるのを不思議に感じたことはありませんか。MTBFとはいったい何なのでしょうか。
簡単に説明すると、MTBFは初期故障期と摩耗故障期の故障はカウントせず、偶発故障期に起こる偶発的な故障のみを考慮に入れているためです。そのため、この数字が示すのは、偶発故障期における成功の確率(信頼性)とシステムが本来の目的を達成できる確率(可用性)のみということになります。MTBFは、システムが使用できる期間(システムが摩耗故障期に入るまでの期間)の算出に使用することはできません
信頼性(R(t))とは、デバイスまたはシステムがある環境で特定の期間故障することなく期待通りに機能する確率と定義されます。期間は通常時間(Hour)で表しますが、サイクル、反復、距離(km)などで計測することもできます。故障率が一定の場合の偶発故障期における信頼性は、以下の式で求めます。
[3]
t = 稼働時間、持続時間
注:故障率が一定していない場合は、上記の式は適用できません。
ある環境におけるシステムの信頼性を計算すると、非信頼性(故障する確率)を計算することができます。システムには、予測通りに動作するかしないかという2つの状態しかないので、この2つの状態は補完的です[4]。正常動作の確率“R(t)”と故障の確率“F(t)”を足すと1になります。 このトピックについては、RASMホワイトペーパーシリーズの「確率の計算」で詳しく説明しています。
[5]
したがって、以下のようになります。
例:
システムのMTBFは300,000時間です。6か月のタスクにおける信頼性予測は、以下のようになります。
6か月 = 4380時間
信頼性(正常動作の確率)は、98.55%と予測することができます。
4380時間での故障確率は、以下のように予測できます。
故障の確率は、1.45%と予測されます。
故障の確率は、故障するリスクを表すもので、必要な予備部品数の計画に役立てることができます。この情報のほか、使用プロファイルと平均復旧時間(MTTR)も理解する必要があります。予備部品とMTTRについては、他のRASMシリーズホワイトペーパーで解説しています。
偶発故障期の特性をよく理解することは、システムの「予備部品戦略」を立てる上で非常に重要です。
第4段階:摩耗故障期
摩耗故障期は、システムの故障率が「基準」を上回るようになる頃が始まりです。この故障率の上昇は、部品の摩耗(老化)が原因と推測されます。ファンなどの機械的回転部品、ハードドライブ、スイッチ、頻繁に使用するコネクタなどが通常最初に故障します。ただしバッテリやコンデンサ、ソリッドステートドライブといった電気部品が最初に故障する場合もあります。ほとんどの集積回路(IC)や電子部品は、仕様内での通常使用なら約20年[6]稼働します。
摩耗故障期では、信頼性は損なわれ、予測も難しくなります。システムが摩耗する時期を予測する方法は、多くの信頼性に関する書籍で扱われ、信頼性工学の分野として認識されていますが、一部の教科書ではこのトピックを耐久性の分野に含めています。この情報は、予防保全戦略と交換計画を作成するにあたって役立つ可能性があります。
まとめ
- 信頼性の予測はリスク管理において極めて重要なツールです。
- システムのライフサイクルは、Pre-Life、初期故障期、偶発故障期、摩耗故障期の4つの期間からなります。
- Pre-Lifeでは、主に必要な可用性レベルを把握しそれに応じて計画を立てます。
- 故障のコストを把握することが重要です。
- ERSSを実施すると、リスクと、必要な信頼性レベルを把握することができます。
- 初期故障期では、テストを実施してシステム運用の準備を整えます。
- MTBFは、製品が摩耗する時期の予測に使用するべきではありません。
- MTBFとMTTRは、偶発故障期における信頼性と可用性の予測に使用できます。また使用プロファイルと組み合わせて、必要な予備部品数を決めることもできます。
関連情報
- Byron Radle, CRE
システム信頼性研究室、シニアエンジニア
National Instruments
- Tom Bradicich, PhD
R&Dフェロー
National Instruments
- Blake Mitchell
システムエンジニア
National Instruments
RASMホワイトペーパーシリーズは、Byron Radle、CRE、およびTom Bradicich, PhDによって編集されています。今後寄稿をご希望の場合は、byron.radle@ni.comまたはtom.bradicich@ni.comまでEメールでご連絡ください。
[1] “Design and Evaluation,” 3rd ed., by Daniel P. Siewiorek and Robert S. Swarz, Reliable Computer Systems (A K Peters/CRC Press, 1998).
[2] "Reliability Theory And Practice", by Igor Bazovsky, Prentice-Hall, Inc. 1961, Library of Congress Catalog Card Number: 61-15632, Chapter 5, page 33
[3] "Reliability Theory And Practice", by Igor Bazovsky, Prentice-Hall, Inc. 1961, Library of Congress Catalog Card Number: 61-15632, Chapter 3, page 19
[4] “Certified Reliability Engineer Primer”, Quality Council of Indiana Fourth Edition, October 1, 2009, p. III-13
[5] “Practical Reliability Engineering” Fifth Edition, by Patrick D. O’Conner and Andre Kleyner, Wiley, ISBN 978-0-470-97981-5, Chapter 2, page 32
[6] “Telcordia Technologies Special Report, SR-332”, Issue 1, May 2001, Section 2.4, page 2-3