保守性とは
概要
「RASM」とは、機能システムの4つの関連特性、Reliability (信頼性)、Availability (可用性)、Serviceability (保守性)、Manageability (管理性) の頭文字をとったものです。初期のコンピュータ業界で、製品の堅牢性を表すのに、「RAS」 (Reliability (信頼性)、Availability (可用性)、Serviceability (保守性)) という頭字語を初めて使用した企業の1つが、IBM社であると一般的に考えられています[1]。「Manageability (管理性)」の「M」は、信頼性、可用性、保守性を多角的に促進することでシステムの堅牢性を支援する役割があるとして、最近追加されました。RASM機能は、テスト、計測、制御、実験およびそれらに関連するビジネス目標に大きく貢献します。
故障せずにパッチやアップグレードも必要ないのが理想ですが、現実ではどのようなシステムもいずれは保守が必要となります。したがって、システムの「保守性」は、事後および予防保全をいかに効率的に実施できるかに影響するものであり、システムの必要な可用性を実現するための鍵となります。システムを極力早く稼働させるための保守は「時は金なり」です。
システムの保守のしやすさは、予防保全のしやすさ、スピード、頻度に影響します。たとえば、農場で育った少年として私は、適切に「グリース」を塗っていなかったために故障した機械を修理しなければなりませんでした。適切な予防保全がなかったということです。故障した部品を見たときの、近所の農家の人のコメントを今でも覚えています。「グリスワームがグリスを完全に食べてしまったようだね。」 さて「グリスワーム」って何のことかわからない。 隣人は怪訝そうな私の顔を見て、「もっと頻繁にグリスを塗っていたら、もっと長持ちしたのに」と、笑いながら言いました。 そこで私は、スパナを探して他の部品を全部外してからでないとお目当ての部品にたどり着けないので、グリス塗りは本当に大変な作業なのだと説明しました。つまり、グリスアップ (保守サービス) が十分でなかったのです。
保守性はシステムの信頼性と可用性に大きく影響し、管理性は保守性に大きく影響します。保守性に与える管理性の影響は、システムの検出とデプロイメント、アップグレード、ヘルスモニタリングとエラーロギング、診断および障害分離などのシステム管理機能で明らかになります。
内容
保守性の定義
保守性とは、システムに対する事後保全や予防保全のしやすさやスピードに関わる一連の機能のことであり、基準となるものです。
事後保全 (Corrective Maintenance: CM) には、故障したシステムを修理し運用/可用状態に戻すのに関わるすべてのアクションが含まれます。故障は予測できるものとできないものがありますが、意図しない故障がほとんどです。CMの実行に必要な時間を定量化する基準となる平均復旧時間 (MTTR) は、システムの可用性の特定にも使用されています。
予防保全 (Preventive Maintenance: PM) に含まれるのは、システムを交換、修理、アップグレード、またはパッチを適用してシステムの運用/可用状態を維持し、システム故障を防ぐために実施されるすべてのアクションです。PMの実行に必要な時間を定量化するために一般的に使用される基準である平均予防保全時間 (MPMT) は、システムの可用性を特定する際にも使用されます。
ライフサイクルの各段階における保守性
図1に示すバスタブ曲線について考えてみます。この曲線は、その形状から名付けられており、システムまたは製品の経時的な故障率を示しています。製品寿命は4つの期間、つまり準備期、初期故障期、偶発故障期、摩耗故障期に分けることができます。故障の理由とメカニズムは期間によって異なります。予期せぬタイミングでの故障を防ぐため、それぞれの期間で異なる点について考慮する必要があります。図1は、これらの故障メカニズムを示しています。
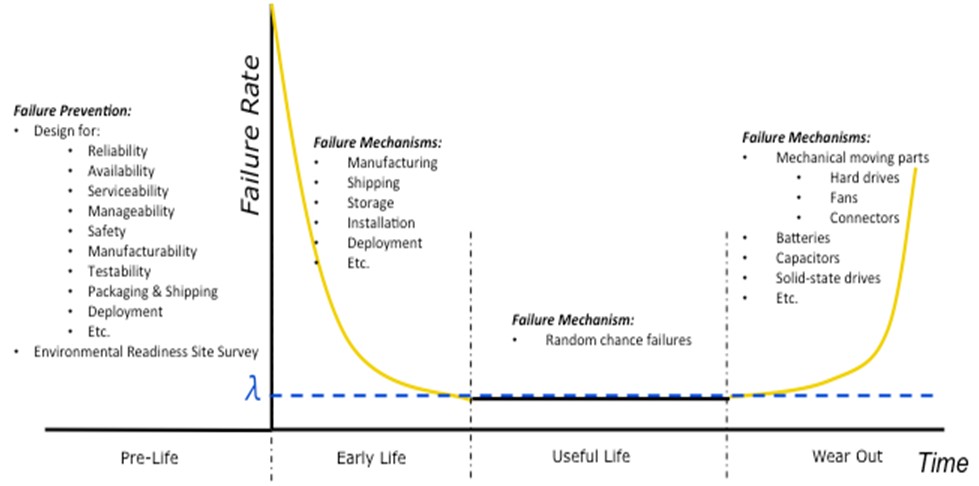
図1.バスタブ曲線
第1段階:準備期
「1オンスの予防薬は1ポンドの治療薬に値する。」
–ベンジャミン・フランクリン
準備期で重視されるのは、プランニングと設計です。システムの設計とアクセス性は、保守性に非常に大きな効果をもたらします。しかし適切な設計を行うには、システムが必要とする保守性レベルを把握する必要があります。
保守性の要件を特定する際に検討すべき主な要素を以下に説明します。しかしこれらがすべてではありません。
ダウンタイムのコスト: 検討すべき要素としてはこれが最も根本的なものです。この情報から、システムをどの程度使用するか、あるいはどの程度の保守性が必要なのかがわかります。ダウンタイムのコストには、生産/販売ができなかった分のコストや、従業員/顧客が職務を行えなかったコストが含まれます。
予防保守: PMを実施する必要がある頻度と平均予防保全時間 (MPMT) として表されるPMの実施にかかる平均時間は、システムの可用性に影響を与えます。
予備部品戦略: 故障した部品をすぐに交換できるように予備部品を近くに置いておくことも、MTTRの削減になり、さらには保守性の向上になります。予備部品もソリューションのコストに加算されますが、部品故障の際に交換部品を注文して届くのを待つ期間は、システムが使えなくなります。それがダウンタイムのコストとなり、予備部品を在庫として保持するコストを上回る可能性があります。
診断ツール要件: 故障した部品を特定することは、修理する上で非常に重要です。そのため、故障をすばやく正確に診断し、さらには予知することが望まれます。それは、効果的な管理機能によって実現できます。優れた管理性は保守性の向上につながり、結果的に可用性が高まります。管理性、保守性、可用性はこのように関係しています。
運用/サービススキル: 予備部品の準備と同様に、CMの診断と修理の技術を持つ人員がいると可用性が向上します。さらに、PMを実施する技術のある人員がいると保守性と可用性が向上します。
環境要因: システムが稼働する環境も、保守性には大きな影響をもたらします。たとえば、混雑した場所や遠隔地、過酷な環境でシステムを使用する場合、周囲の危険が取り除かれるまで、技術者がそのような場所に行くことは危険性が高く困難です。そしてそのような状況はMTTRの大幅な遅延につながります。システムの設置と実装の前にEnvironmental Readiness Site Survey (ERSS) の調査を行っておくと、そのような要素を効果的に評価できるほか、求められる保守性を実現するのに環境がどのように影響するかを理解することができます。
第2段階:初期故障期
初期故障期は、一般に偶発故障期に比べ高い故障率が特徴です。このような故障は、一般に「初期死亡率」と呼ばれます。 このような初期故障は、システムを最大負担の状態で長時間テストすることによって顕在化させることができます。これは通常システムの実装前に行われます。多くの場合、製造欠陥や製造テスト時に検出されなかった不良部品、出荷・保管・設置時の損傷が原因とされます。これらの問題が解決されると、故障率は急激に低下します。
製品のライフサイクルの中でもこの期間は特に故障が多く、CMイベント数が増えるため、予備部品を多めに用意しておく必要があります。この段階を利用して、システムのCMとPMにかかる時間を推定することができます。
CMの実施に必要な時間は、以下のようにMTTRによって算出します。
[2]
PMの実施に必要な時間は、以下のようにMPMTによって算出します。
第3段階:偶発故障期
偶発故障期とは、システムの初期問題が解決され、通常操作が安定的に行えると信頼される期間です。この期間では、RASM工学の厳密な科学/数学的概念が数多く適用されます。偶発故障期では、故障は「ランダムな偶発故障」と考えられており、一定の故障率があります。故障率が一定していれば、故障の予知に関連する数式もシンプルになります。
偶発故障期では、以下のように一定の故障率、「λ」を使用して平均故障間隔 (MTBF) を計算することができます。
故障率λ、つまりMTBFは一定とみなします。すると次のようになります。
[3]
数字上、保守性 (S) を算出するには、以下の式から平均保守時間 (MMT) を計算します。
[4]
一連の機能で考えると、保守性がいかに堅牢かは主要機能によって特性付けることができます。
- モジュール式アーキテクチャ: モジュール式アーキテクチャなので、相互接続された個別のコンポーネントやサブシステムを使ってシステムを完成させることができます。例としては、ブレードサーバ[5]やPXIテストシステムがあります。モジュール式システムと異なり、単体計測器の統合システムは、拡張性、アップグレード性、保守性に限界があります。モジュール式アーキテクチャなら、交換可能な部品や交換可能ユニット (FRU) に故障を隔離することができます。そのためMTTRが大幅に短縮でき、短期間でシステムを再稼働させることができます。モジュール式アーキテクチャのシステムなら、故障した、あるいは故障しそうなモジュール/コンポーネントのみの交換が簡単にできます。またシステムのデバッグの際にも、故障したコンポーネントの診断と分離が簡単にすばやくできます。
- PM不要: 事実上システムのMPMTをゼロにすることができます。たとえば、自動車の密封軸受はPMにかかる時間のコスト削減につながり、それは長期間持続します。実際に、他の多くの自動車部品に比べ長く持つのがこの部品です。そのため、多くの場合軸受が故障するまで交換の必要がなく、この部品に関してはPMが必要ありません。集積回路 (IC) も、定期的な校正が必要なアナログ回路を除き、しばしばPM不要のカテゴリに分類されます。計測精度が低下したシステムは、期待通りに動作していることにならないため、校正はPMと考えることができます。ただし現在、多くのシステムには清掃が必要なファンやフィルタ、校正が必要なアナログコンポーネントがありません。そのため実用目的ではPMは必要ないのです。
- システムのヘルスモニタリングと故障アラームシステム (ウォッチドッグシステム/システム予測ツールとも呼ばれます): システムの故障に早く気付けば、その分早く対応できるため、システムのMTTRを短縮することができます。ヘルスモニタリングを行えば、実際にシステムが故障し、さらに損害が広がる前に、問題の兆候を捉えることができるので、予期せぬ故障を計画的な機能停止に (CMイベントをPMイベントに) 変えることで、コストを節約することもできます。したがって、都合のいい時にシステムを停止させ、問題のコンポーネントを故障前に交換することが可能です。システム予測とBig Analog Data™の開発
ソリューションによって、データ収集業界におけるコンピュータベースのソフトウェアシステムの能力を高め、発生前にシステムの故障を予測することができるようになります。そうすることで、PMの頻度を下げることができ、コストの削減につながります。ほとんどのPMプログラムでは、システムコンポーネントの修理や交換を定期的スケジュールで実施しています。それは、部品は消耗するものであり、新たに設置する部品より信頼性が低いということを前提にしており、そのために予期せぬ故障を回避することができます。ただしそれが常に最も効率的な方法とは限りません。「壊れていないものを修理するな」と言う人もいます。しばらくの間使用しているコンポーネントは、初期故障 (初期死亡率) の可能性がある新規部品に比べ、信頼性が劣ることはないかもしれません。そのためコンポーネントを極力長期間使用し、故障しそうな時期まで待って交換するようにすれば、不要な予備部品や不要なPMにかかるコストを節約することができます。そうすることで不必要な初期故障のリスクを減らし、システムのMPMTを短縮することが可能となります。
- システムのセルフテスト/診断機能: システム内の故障部品を早く見つけることができれば、システムを修理し、稼働状態に戻すのも短期間で可能となります。それによって、システムのMTTRを短縮できます。
- システムの複製とソフトウェアの配布: ソフトウェアが故障したり破損した場合は、ソフトウェアを早く復旧させることでシステムのMTTRを短縮できます。パッチをインストールして問題を修正したり、ソフトウェアをアップグレードする必要がある場合、短時間で行えばそれだけシステムのMPMTは短縮されます。
- ツール不要: システムの保守 (モジュール/コンポーネントの交換) にツールは必要ありません。特殊なツールを探す必要がなければ、時間の節約になります。またコストも節約することができます。
- 冗長化: 冗長化は、通常システムの信頼性と可用性に最も大きな利益をもたらします。冗長コンポーネントがあれば、故障したコンポーネントを即座に交換できるため、その故障を修理するためのMTTRは実質ゼロになります。システム全体を冗長にする必要はありません。最も重要なコンポーネントや、故障しやすいコンポーネントのみを用意しておけば十分です。たとえば、電源とファンは冗長が必要かもしれませんが、システムのその他の部分は故障の確率が極めて低い (MTBFが非常に低い) ため、それらのコンポーネントの予備を用意する必要はありません。
- ホットスワップ可能な冗長コンポーネント: ホットスワップ可能なコンポーネントは、システムを停止したりオフラインにしなくても、故障したコンポーネントの修理/交換や冗長コンポーネントのPMが行えるというメリットがあります。したがってシステムの停止期間がなくなり、システムの可用性を限りなく100%に近づけることが可能です。
- ソフトウェアの再生: コンピュータやテストシステムにおける故障の共通原因としてソフトウェアの欠陥がありますので、ソフトウェアのRASMの意味について考える必要があります。ソフトウェアが原因のシステム故障の多くは、システムのリソース不足によるハングアップやクラッシュです。そのようなソフトウェアの欠陥に対処するには、CMまたはPMとしてソフトウェア再生[6]のようなテクニックを利用し、ソフトウェアの劣化が進行して故障のポイントまで達する前に、システムをリセットすることができます。
そのような機能は、MTTRとMPMTを短縮したり、予期せぬシステム停止を回避することができますので、システムの可用性と信頼性の向上につながります。
第4段階:摩耗故障期
摩耗故障期は、システムの故障率が偶発故障期の「基準」を上回るようになる頃が始まりです。この故障率の上昇は、基本的に部品の摩耗 (老化) が原因と推測されます。ファン、ハードドライブ、スイッチ、リレー、頻繁に使用するコネクタなどの機械的回転部品が通常最初に故障します。ただし、バッテリやコンデンサ、ソリッドステートドライブといった電気部品が最初に故障する場合もあります。ほとんどの集積回路 (IC) や電子部品は、仕様内での通常使用なら約20年[7]稼働します。
摩耗故障期では、故障率 (MTBF) が一定でないため、システムの信頼性は低下し、予測が困難になります。そのため、厳密なPM/交換計画を立てることをお勧めします。保守性を高める機能や対策により、摩耗故障期におけるシステムの交換やアップグレードに伴うコストやダウンタイムを劇的に削減することが可能となります。
まとめ
- 準備期の計画と設計は、ERSS、PM、CM、予備部品、交換戦略といった保守性問題について考える絶好の機会です。
- システムの設計とアクセス性は、保守性に非常に大きな効果をもたらします。
- ダウンタイムにおける経済面およびリソース面でのコストを把握することが重要です。
- 準備期のERSSは、保守性レベルとその障害となるものの定義に役立ちます。
- 初期故障期はテストに重点を置き、MTTRとMPMTの推定に使用できます。
- 保守性により、偶発故障期におけるシステムの信頼性と可用性を向上させることができます。
関連情報
[1] “Design and Evaluation,” 3rd ed., by Daniel P. Siewiorek and Robert S. Swarz, Reliable Computer Systems (A K Peters/CRC Press, 1998).
[2] “The Certified Reliability Engineer Handbook,” 2nd ed., by Donald W. Benbow and Hugh W. Broome, ASQ Quality Press, Milwaukee Wisconsin, 2013, ISBN 978-0-87389-837-9, Chapter 13, page 227.
[3] “Reliability Theory and Practice,” by Igor Bazovsky, Prentice-Hall, Inc., 1961, Library of Congress Catalog Card Number:61-15632, Chapter 5, page 33.
[4] “Practical Reliability Engineering” Fifth Edition, by Patrick D. O’Conner and Andre Kleyner, Wiley, ISBN 978-0-470-97981-5, Chapter 16, page 410.
[5] Blade Server, http://en.wikipedia.org/wiki/Blade_server.
[6] Software Aging, http://en.wikipedia.org/wiki/Software_aging.
[7] “Telcordia Technologies Special Report, SR-332”, Issue 1, May 2001, Section 2.4, pages 2–3.