Initialize Clustering Model (K-Means) VI
- Updated2023-02-21
- 5 minute(s) read
Initialize Clustering Model (K-Means) VI
Owning Palette: Clustering VIs
Requires: Analytics and Machine Learning Toolkit
Initializes the hyperparameters of the K-Means algorithm. You can either directly set the hyperparameters or specify multiple values for each hyperparameter. If you specify multiple values for each hyperparameter, the Train Clustering Model VI uses grid search to find the optimal set of hyperparameters.
Set Parameters

 |
initial centroids specifies the initial centroids. This input is valid only if initial method is Custom. | ||||||||||||||
 |
hyperparameters specifies the hyperparameters for the K-Means model.
| ||||||||||||||
 |
error in describes error conditions that occur before this node runs. This input provides standard error in functionality. | ||||||||||||||
 |
untrained K-Means model returns the initialized K-Means model for training. | ||||||||||||||
 |
error out contains error information. This output provides standard error out functionality. |


Search Parameters
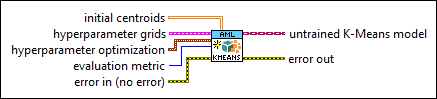
|
initial centroids specifies the initial centroids. This input is valid only if initial method is Custom. | ||||||||||||||||
 |
hyperparameter grids specifies multiple values for each hyperparameter.
| ||||||||||||||||
|
hyperparameter optimization specifies the method of optimization to determine the optimal hyperparameter settings.
| ||||||||||||||||
 |
evaluation metric specifies the criterion to evaluate the trained clustering model.
|
||||||||||||||||
|
error in describes error conditions that occur before this node runs. This input provides standard error in functionality. | ||||||||||||||||
|
untrained K-Means model returns the initialized K-Means model for training. | ||||||||||||||||
|
error out contains error information. This output provides standard error out functionality. |




Examples
Refer to the following VIs for examples of using the Initialize Clustering Model (K-Means) VI:
- Clustering (Set Parameters, Training) VI: labview\examples\AML\Clustering
- Clustering (Search Parameters, Training) VI: labview\examples\AML\Clustering