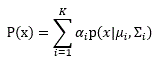|
initial parameters specifies the initial parameters to train the GMM model.
 |
auto initialization specifies whether this VI automatically calculates the values in initial parameters using K-Means algorithm. The default is TRUE, which specifies that this VI automatically sets the values in initial parameters using K-Means algorithm.
If you do not specify values for the arrays in initial parameters and auto initialization is FALSE, this VI randomly calculates the values in initial parameters.
|
 |
initial mean values specifies the initial mean values of all Gaussian distributions in the GMM model.
|
 |
initial covariance values specifies the initial covariance values of all Gaussian distributions in the GMM model.
|
initial covariance matrix specifies the initial covariance matrix of each Gaussian distribution in the GMM model.
|
|
 |
initial weights specifies the initial weights of all Gaussian distributions in the GMM model.
|
|
|
hyperparameter grids specifies multiple values for each hyperparameter of the GMM model.
 |
number of clusters specifies the number of Gaussian distributions in the trained GMM model.
|
|
regulator specifies the value that this VI adds to covariance to prevent the covariance matrix from converging to 0.
|
|
tolerance specifies the tolerance for the stopping criteria.
|
|
max iteration specifies the maximum number of optimization iterations for the stopping criteria. The model fitting stops if the number of optimization iterations reaches max iteration.
|
|
attempts specifies the number of times that the Train Clustering Model VI trains the model with different hyperparameter combinations.
|
|
 |
hyperparameter optimization specifies the method of optimization to determine the optimal hyperparameter settings.
 |
hyperparameter search method specifies the method to search for the optimal set of hyperparameters.
| 0 | Exhaustive search (default)—Tests all possible hyperparameter combinations in the training process. This method is reliable but time-consuming. | | 1 | Random search—Tests a random subset of the hyperparameter combinations in the training process. This method is faster. |
|
 |
number of searchings specifies the number of hyperparameter combinations that this VI selects to train the model. The default is 1. This input is valid only if hyperparameter search method is Random search.
|
|
|
evaluation metric specifies the criterion to evaluate the trained clustering model.
| 0 | Davies Bouldin Index—Evaluates the clustering model using the Davies Bouldin Index metric. The lower the value of metric, the better the compactness and separation of the clustering model. | | 1 | Dunn Index—Evaluates the clustering model using the Dunn Index metric. The higher the value of metric, the better
the compactness and separation of the clustering model. | | 2 | Jaccard Index—Evaluates the clustering model using the Jaccard Index metric. The lower the value of metric, the better the
separation of the clustering model. | | 3 | Rand Index—Evaluates the clustering model using the Rand Index metric. The lower the value of metric, the better the separation of the clustering model. | | 4 | AIC (default)—Evaluates the GMM model using the Akaike Information Criterion (AIC) metric. The lower the value of metric, the better the GMM model is. | | 5 | BIC—Evaluates the GMM model using the Bayesian Information Criterion (BIC) metric. The lower the value of metric, the better the GMM model is. |
|
 |
error in describes error conditions that occur before this node runs. This input provides standard error in functionality.
|
 |
untrained GMM model returns the initialized GMM model for training.
|
 |
error out contains error information. This output provides standard error out functionality.
|