Werden meine LabVIEW-Programme schneller ausgeführt, wenn ich auf einen Multicore-Computer umsteige?
Überblick
Whitepaper-Serie „Grundlagen der Multicore-Programmierung“

Whitepaper-Serie „Grundlagen der Multicore-Programmierung“
Ob sich die Leistung eines NI LabVIEW-Programms auf einem Multicore-System (z. B. Dual-Core- und Quad-Core-Computer) verbessert, hängt von mehreren Faktoren ab. Dazu gehören die Besonderheiten der neuen Hardware, der Aufbau der LabVIEW-Anwendung und die Systemsoftware. Tests mit gängigen LabVIEW-Programmstrukturen zeigen aufgrund der natürlichen Parallelität in den meisten LabVIEW-Programmcodes eine durchschnittliche Verbesserung der Ausführungszeit um 25 bis 35 Prozent. Die Art der einzelnen Programme kann diese Schätzung jedoch erheblich beeinflussen. Durch die Optimierung eines LabVIEW-Programms für eine Multicore-Computerumgebung kann die Ausführungszeit durch ein Upgrade auf ein Multicore-Computersystem erheblich verkürzt werden. In diesem Whitepaper werden die wichtigsten Faktoren behandelt, die die Ausführungsgeschwindigkeit von LabVIEW-Programmen auf Multicore-Systemen beeinflussen.
Inhalt
- Leistungsmetriken
- Berücksichtigung von Taktrate und Prozessoranzahl
- Kommunikationsaufkommen
- Programm- und Softwareprobleme
- Fazit
- Weitere Ressourcen zur Multicore-Programmierung
Leistungsmetriken
Bei der Bewertung der Leistung eines LabVIEW-Programms sind Speicherauslastung und Ausführungszeit die wichtigsten Parameter. Die Ausführungszeit ist die Zeit, die zur Verarbeitung einer Gruppe von Anweisungen benötigt wird (in der Regel gemessen in Sekunden). Die Speicherauslastung ist der Speicherplatz, der für die Verarbeitung einer Gruppe von Anweisungen benötigt wird (in der Regel gemessen in Byte). Diese Messwerte sind gute Indikatoren für die individuelle Programmleistung, wobei die Ausführungszeit entscheidend ist. Eine weitere Leistungsverbesserung bei Multicore-Systemen ist die Reaktionszeit. Bei der Reaktionszeit – also wie schnell ein Programm oder System auf Eingaben reagiert – wird die Zeit, die zur Ausführung einer gewünschten Aktion benötigt wird, nicht berücksichtigt. Multicore-Systeme weisen dank Multitasking mit mehreren verfügbaren Kernen eine kürzere Reaktionszeit auf. Dies stellt zwar eine Leistungsverbesserung dar, ist aber nicht unbedingt ein Hinweis auf eine Verbesserung der Ausführungszeit.
Berücksichtigung von Taktrate und Prozessoranzahl
LabVIEW skaliert Programme automatisch, um die Vorteile mehrerer Prozessoren auf High-End-Computersystemen zu nutzen, indem es die Anzahl der verfügbaren Kerne bestimmt und Sie dabei unterstützt, eine größere Anzahl von Threads zu entwickeln. Beispielsweise erstellt LabVIEW acht Threads für die Programmausführung auf einem Octa-Core-Computer.
Mehr Prozessoren, gleiche Taktrate
Wenn ein Single-Core-Computersystem durch ein Multicore-System ersetzt wird, das Prozessoreinheiten mit der gleichen Taktrate wie das Single-Core-System verwendet, wird die Ausführungszeit von LabVIEW-Programmen verkürzt. Im Idealfall erhöht sich die Programmausführungsgeschwindigkeit um einen Faktor, der der Anzahl der Kerne auf dem Multicore-Computersystem entspricht (z. B. eine Vervierfachung der Geschwindigkeit auf einem Quad-Core-System). Das Kommunikationsaufkommen zwischen Threads und Kernen verhindert jedoch diese ideale Verbesserung der Ausführungszeit. Wenn das betreffende LabVIEW-Programm vollständig sequenziell ist und auf einem einzelnen Prozessor ausgeführt wird, benötigt es weniger gemeinsame Prozessorzeit mit anderer Software, was zu einer kürzeren Programmausführungszeit führt. Wenn das betreffende Programm vollständig parallel ist und aus Tasks gleicher Größe ohne Datenabhängigkeit besteht, können Sie eine nahezu ideale Verbesserung der Ausführungszeit erzielen.
Mehr Prozessoren, langsamere Taktrate
Wenn Sie ein Single-Core-Computersystem durch ein Multicore-System ersetzen, das Prozessoren mit langsameren Taktraten verwendet, erstellen Sie ein unklares Szenario für die Bestimmung von Änderungen in der Ausführungszeit von LabVIEW-Programmen. Wenn das betreffende LabVIEW-Programm vollständig sequenziell ist und exklusiven Zugriff auf einen einzelnen Kern des Multicore-Systems hat, wird die Auswirkung auf die Ausführungszeit wahrscheinlich durch die relativen Taktraten des Systems und durch die Planung der Tasks bestimmt. Auch die Ausführungszeit eines vollständig parallelen LabVIEW-Programms, das aus gleich großen Tasks ohne Datenabhängigkeit besteht und dem Zugriff auf alle verfügbaren Kerne des Multicore-Rechners gewährt wird, ist von relativen Taktraten und der Planung der Tasks abhängig.
Kommunikationsaufkommen
Speicherschemata
Die Speicherorganisation in Multicore-Computersystemen beeinflusst das Kommunikationsaufkommen und die Ausführungsgeschwindigkeit von LabVIEW-Programmen. Gängige Speicherarchitekturen sind gemeinsam genutzter Speicher, verteilter Speicher und hybrider, verteilter gemeinsamer Speicher. Systeme mit gemeinsam genutztem Speicher verwenden einen großen globalen Speicherbereich, auf den alle Prozessoren zugreifen können, um eine schnelle Kommunikation zu ermöglichen. Wenn jedoch mehr Prozessoren mit demselben Speicher verbunden werden, kommt es zu einem Kommunikationsengpass zwischen den Prozessoren und dem Speicher. Verteilte Speichersysteme verwenden lokalen Speicherplatz für jeden Prozessor und die Kommunikation zwischen Prozessoren erfolgt über ein Kommunikationsnetzwerk. Dies führt dazu, dass die Kommunikation zwischen Prozessoren langsamer ist als mit gemeinsam genutzten Speichersystemen. Darüber hinaus wird auf einigen Systemen eine verteilte gemeinsame Speicherarchitektur verwendet, um die Vorteile beider Architekturen zu nutzen. Speicherschemata haben einen erheblichen Einfluss auf das Kommunikationsaufkommen und damit auf die Programmausführungsgeschwindigkeit in jeder Programmiersprache (LabVIEW, C, Visual Basic usw.).
Kommunikation zwischen Prozessoren
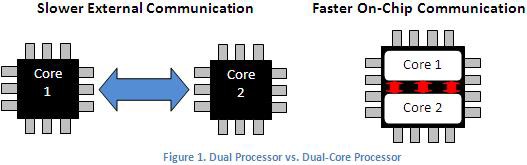
Physische Abstände zwischen Prozessoren und die Qualität der Verbindungen zwischen Prozessoren beeinflussen aufgrund des Kommunikationsaufkommens die Ausführungsgeschwindigkeit von LabVIEW-Programmen. Mehrere Prozessoren auf separaten ICs weisen eine höhere Kommunikationslatenz zwischen Prozessoren auf als Prozessoren auf einem einzelnen IC. Dies führt zu Beeinträchtigungen durch einen höheren Kommunikationsaufwand und zu einer langsameren Ausführung von LabVIEW-Programmen. In Abbildung 1 hat beispielsweise das Dual-Prozessor-System (zwei Sockets) auf der linken Seite eine höhere Latenz als der Dual-Core-Prozessor mit einem Chip auf der rechten Seite.
Programm- und Softwareprobleme
Organisation von Programmcode
Die Ausführungsdauer von LabVIEW-Programmen hängt auf einem Multicore-Computer gleichermaßen vom Programm wie vom Computer ab, auf dem es ausgeführt wird. Das Programm muss so geschrieben sein, dass es von der einzigartigen Umgebung auf Multicore-Systemen profitieren kann. Der Grad der Programmparallelität hat einen großen Einfluss auf die Ausführungszeit des Programms, ebenso wie Granularität (das Verhältnis von Rechenleistung zu Kommunikation) und Lastverteilung. Ein großer Teil des vorhandenen G-Codes wird für die sequenzielle Ausführung geschrieben. Diese Art von Code hat jedoch wahrscheinlich eine gewisse inhärente Parallelität aufgrund der Natur der Datenflussprogrammierung. Wie bereits erwähnt, zeigen Tests gängiger LabVIEW-Programmstrukturen beim Übergang von einem Single-Core-System zu einem Multicore-System eine durchschnittliche Verbesserung der Ausführungszeit um 25 bis 35 Prozent. Die Art der einzelnen Programme beeinflusst diese Schätzung jedoch erheblich. Die Optimierung eines LabVIEW-Programms für eine Multicore-Computerumgebung kann beim Upgrade auf ein Multicore-Computersystem zu erheblichen Zeiteinsparungen führen.
Hardwarespezifische Optimierung
Das Organisieren von G-Code zur Erhöhung der Ausführungsgeschwindigkeit ist kompliziert, wenn Sie die Hardware nicht kennen, auf der Sie das Programm ausführen. Ein umfassendes Wissen zum System, auf dem ein Multicore-Programm ausgeführt wird, ist entscheidend, um die maximale Ausführungsgeschwindigkeit zu erzielen. Multicore-Programmiertechniken erfordern einen allgemeineren Ansatz für Systeme mit einer unbekannten Anzahl von Kernen. Diese Vorgehensweise trägt dazu bei, die Ausführungszeit auf den meisten Multicore-Computern zu verkürzen, kann aber die maximale Ausführungsgeschwindigkeit auf einem bestimmten System beeinträchtigen. Die hardwarespezifische Optimierung von LabVIEW-Programmen kann zeitaufwändig sein und ist nicht immer erforderlich. Sie kann jedoch notwendig sein, wenn Sie auf einer bestimmten Hardware auf maximale Ausführungsgeschwindigkeit angewiesen sind. Um beispielsweise das Potenzial eines Octa-Core-Computersystems voll auszuschöpfen, können Sie fortgeschrittene Techniken für die parallele Programmierung verwenden, z. B. Datenparallelität oder Pipelining. Darüber hinaus können Sie die Anzahl der Kerne eines Systems, das Kern-Layout (zwei Dual-Cores oder ein Quad-Core), das Verbindungsschema, das Speicherschema und Informationen zu bekannten Fehlern nutzen, um die Programmausführungszeiten auf Multicore-Systemen zu minimieren.
Weitere Informationen zu Strategien für die parallele Programmierung finden Sie unter:
Leistungsfähigkeit des Softwarestapels
Engpässe bei der Parallelität können auf mehreren Ebenen des Softwarestapels auftreten. In traditionellen Sprachen wie C ist die Vermeidung dieses Problems eine Herausforderung. Ein Vorteil der LabVIEW-Programmierung ist der Multicore-fähige Softwarestapel, der diese Engpässe im Vorfeld beseitigt. Der Softwarestapel besteht aus vier Schichten, die Sie zur Bestimmung der Multicore-Bereitschaft bewerten müssen, um die mit Multicore-Hardware möglichen Leistungsverbesserungen zu erzielen: Entwicklungswerkzeug, Bibliotheken, Gerätetreiber und Betriebssystem. Wenn diese Schichten nicht für die Multicore-Verarbeitung ausgelegt sind, gelten Leistungsverbesserungen als unwahrscheinlich und es kann stattdessen zu Leistungseinbußen kommen. Tabelle 1 zeigt, wie LabVIEW einen Multicore-fähigen Softwarestapel gewährleistet.
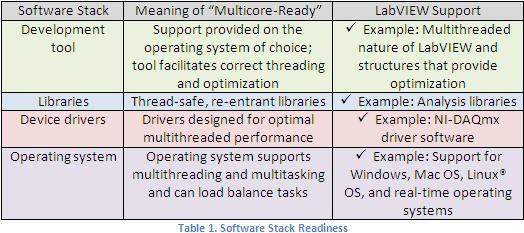
Multicore-Systeme mit Bibliotheken und Treibern, die nicht für die Multicore-Verarbeitung geeignet sind, oder Betriebssysteme, die Tasks nicht auf mehrere Kerne verteilen können, führen parallele LabVIEW-Programme nicht schneller aus.
Fazit
Beim Bestimmen der erwarteten Ausführungszeit von LabVIEW-Programmen auf Multicore-Systemen müssen Sie verschiedene Faktoren berücksichtigen. Beim Upgrade auf ein Multicore-System, das nicht ordnungsgemäß konfiguriert ist, können Hardware- und Softwareprobleme außerhalb von LabVIEW eine Verbesserung der Ausführungszeit verhindern. Darüber hinaus ist die Struktur eines LabVIEW-Programms oft das Hauptproblem, wenn es um die Multicore-Leistung geht. LabVIEW unterstützt die Minimierung der Faktoren, die Sie beim Upgrade auf Multicore-Computersysteme beachten müssen, da es Multicore-fähig ist und einfache sowie intuitive Multicore-Programmierfunktionen und -Beispiele bereitstellt.
Weitere Ressourcen zur Multicore-Programmierung
Whitepaper-Serie „Grundlagen der Multicore-Programmierung“
- Multithread-Funktionen von LabVIEW-Funktionen und -Treibern
- Optimierung automatisierter Prüfanwendungen mit LabVIEW für Multicore-Prozessoren
- Erfahren Sie mehr über NI LabVIEW
Linux® ist in den USA und anderen Ländern die eingetragene Marke von Linus Torvalds.