Optimierung automatisierter Testanwendungen für Multicore-Prozessoren mit LabVIEW von NI
Überblick
Whitepaper-Serie „Grundlagen der Multicore-Programmierung“

Whitepaper-Serie „Grundlagen der Multicore-Programmierung“
LabVIEW bietet eine einzigartige und benutzerfreundliche grafische Programmierumgebung für automatisierte Testanwendungen. Es ist jedoch seine Fähigkeit, verschiedenen CPU-Kernen dynamisch Programmcode zuzuweisen, was die Ausführungsgeschwindigkeit auf Multicore-Prozessoren verbessert. Erfahren Sie, wie LabVIEW-Anwendungen optimiert werden können, um die Vorteile paralleler Programmierverfahren zu nutzen.
Inhalt
- Die Herausforderung der Multithread-Programmierung
- Implementieren paralleler Testalgorithmen
- Konfigurieren benutzerdefinierter paralleler Testalgorithmen
- Optimieren von Hardware-in-the-Loop-Anwendungen
- Fazit
- Weitere Ressourcen zur Multicore-Programmierung
Die Herausforderung der Multithread-Programmierung
Bis vor kurzem führten Innovationen in der Prozessortechnologie zu Computern mit CPUs, die mit höheren Taktraten arbeiteten. Da sich die Taktraten inzwischen allerdings ihrer theoretischen Obergrenze nähern, werden neue Prozessoren entwickelt, die mehrere Verarbeitungskerne enthalten. Mit diesen neuen Multicore-Prozessoren können Ingenieure, die automatisierte Testanwendungen entwickeln, durch den Einsatz paralleler Programmierverfahren die beste Leistung und den höchsten Durchsatz erzielen. Dr. Edward Lee, Professor der Elektrotechnik und technischen Informatik an der University of California, Berkeley, beschreibt die Vorteile der parallelen Verarbeitung wie folgt:
„Viele Experten prophezeien, dass auf das Ende der Gültigkeit des Moore'schen Gesetzes zunehmend parallele Computerarchitekturen folgen werden. Wollen wir auch künftig Leistungssteigerungen in der Computertechnologie erzielen, müssen Programme in der Lage sein, aus dieser Parallelität Nutzen zu ziehen.“
Darüber hinaus erkennen Branchenexperten, dass es für die Programmierung von Anwendungen eine erhebliche Herausforderung darstellt, Multicore-Prozessoren wirklich auszunutzen. Bill Gates, Gründer von Microsoft, Inc., erklärt diese Problematik folgendermaßen:
„Um die Leistung von parallel arbeitenden Prozessoren voll auszuschöpfen, ... muss die Software erst einmal mit der Gleichzeitigkeit von Abläufen fertig werden. Jedoch wird jeder Entwickler, der schon einmal multithreading-fähigen Programmcode geschrieben hat, bestätigen, dass dies eine der schwierigsten Aufgaben in der Programmierung überhaupt darstellt.“
Glücklicherweise bietet die LabVIEW-Software von NI eine ideale Programmierumgebung für Multicore-Prozessoren mit einer intuitiven API zur Erstellung paralleler Algorithmen, die einer Anwendung dynamisch mehrere Threads zuweisen können. Sie können automatisierte Testanwendungen mit Multicore-Prozessoren optimieren, um die beste Leistung zu erzielen.
Bei modularen Messgeräten nach dem Standard PXI Express wird dieser Vorteil zudem noch verstärkt, da über den PCI Express-Bus hohe Datenübertragungsraten möglich sind. Zwei spezifische Anwendungen, die von Multicore-Prozessoren und PXI-Express-Messgeräten profitieren, sind die Signalanalyse mit mehreren Kanälen und die Inline-Verarbeitung (Hardware-in-the-Loop). In diesem Whitepaper werden verschiedene parallele Programmierverfahren bewertet und deren Leistungsvorteile beschrieben.
Implementieren paralleler Testalgorithmen
Eine gängige automatisierte Testanwendung, die von der parallelen Verarbeitung profitiert, ist die Signalanalyse mit mehreren Kanälen. Da die Frequenzanalyse die Prozessorleistung stark beansprucht, lässt sich die Ausführungsgeschwindigkeit durch paralleles Ausführen des Testcodes erhöhen, sodass die Signalverarbeitung von den einzelnen Kanälen auf mehrere Prozessorkerne verteilt werden kann. Aus Programmierersicht ist die einzige Änderung, die Sie vornehmen müssen, um diesen Vorteil zu erzielen, eine geringfügige Umstrukturierung des Testalgorithmus.
Um dies zu verdeutlichen, wird im Folgenden die Ausführungsdauer zweier Algorithmen für die Frequenzanalyse (Fast-Fourier-Transform, FFT) auf zwei Kanälen eines Hochgeschwindigkeitsdigitalisierers verglichen. Der 14-Bit-Hochgeschwindigkeitsdigitalisierer NI PXIe-5122 verwendet zwei Kanäle, um Signale mit der maximalen Sample-Rate (100 MS/s) zu erfassen. Hier ist zunächst das traditionelle sequenzielle Programmiermodell für diese Operation in LabVIEW.
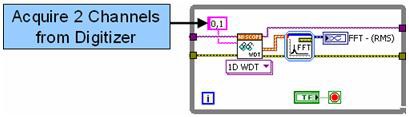
Abbildung 1: LabVIEW-Code mit sequenzieller Ausführung.
In Abbildung 1 wird die Frequenzanalyse beider Kanäle in einem FFT-Express-VI durchgeführt, das jeden Kanal nacheinander analysiert. Der oben gezeigte Algorithmus kann zwar weiterhin effizient auf Multicore-Prozessoren ausgeführt werden, jedoch lässt sich die Ausführungsgeschwindigkeit des Algorithmus durch parallele Verarbeitung der Kanäle steigern.
Bei genauerer Untersuchung des Algorithmus ist zu erkennen, dass die FFT-Analyse wesentlich länger dauert als die Erfassung mit dem Hochgeschwindigkeitsdigitalisierer. Wird jeder Kanal einzeln abgefragt und zwei FFT-Analysen parallel durchgeführt, lässt sich die Verarbeitungszeit erheblich verkürzen. In Abbildung 2 ist ein neues LabVIEW-Blockdiagramm mit parallelem Ansatz dargestellt.
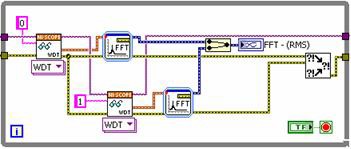
Abbildung 2: LabVIEW-Code mit paralleler Ausführung.
Jeder Kanal wird vom Digitalisierer sequenziell abgefragt. Beachten Sie, dass Sie diese Operationen auch vollständig parallel ausführen können, wenn beide Abrufe von unterschiedlichen Messgeräten erfolgen. Da eine FFT jedoch den Prozessor stark beansprucht, lässt sich die Leistung einfach steigern, wenn die Signalverarbeitung parallel stattfindet. Dadurch wird die Gesamtausführungsdauer verkürzt. In Abbildung 3 ist die Ausführungsdauer beider Implementierungen dargestellt.
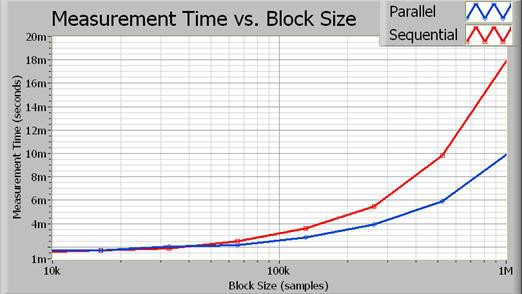
Abbildung 3: Mit zunehmender Blockgröße wird die durch die parallele Ausführung eingesparte Verarbeitungszeit deutlicher.
Tatsächlich führt der parallele Algorithmus bei größeren Blockgrößen fast zu einer Verdoppelung der Leistung. Abbildung 4 zeigt die genaue prozentuale Leistungssteigerung als Funktion der Erfassungsgröße (in Samples).
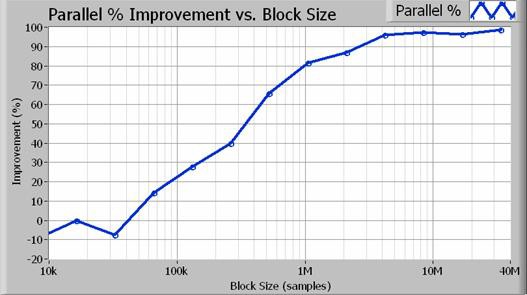
Abbildung 4: Bei Blockgrößen von mehr als 1 Million Samples (bei 100 Hz Auflösungsbandbreite) führt der parallele Ansatz zu einer Leistungssteigerung von mindestens 80 Prozent.
Eine Steigerung der Leistung automatisierter Testanwendungen ist auf Multicore-Prozessoren einfach zu erreichen, da die Threads mit LabVIEW dynamisch zugewiesen werden. Zum Aktivieren von Multithreading muss kein spezieller Programmcode erstellt werden. Stattdessen profitieren parallele Testanwendungen von Multicore-Prozessoren mit minimalen Programmieranpassungen.
Konfigurieren benutzerdefinierter paralleler Testalgorithmen
Mithilfe von Algorithmen für die parallele Signalverarbeitung kann LabVIEW die Prozessorauslastung auf mehrere Kerne aufteilen. In Abbildung 5 ist die Reihenfolge dargestellt, in der die CPU die einzelnen Teile des Algorithmus verarbeitet.
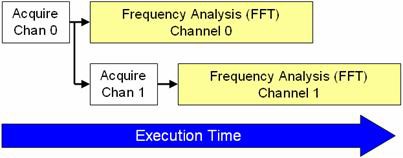
Abbildung 5: LabVIEW kann einen Großteil der erfassten Daten parallel verarbeiten, wodurch sich die Ausführungsdauer verkürzt.
Die parallele Verarbeitung erfordert, dass LabVIEW eine Kopie (bzw. einen Klon) von jedem Unterprogramm der Signalverarbeitung erstellt. Standardmäßig werden viele LabVIEW-Signalverarbeitungsalgorithmen für eine „ablaufinvariante Ausführung“ konfiguriert. Das bedeutet, dass LabVIEW dynamisch eine eindeutige Instanz jedes Unterprogramms zuweist, einschließlich separater Threads und Speicherplatz. Daher müssen benutzerdefinierte Unterprogramme für eine ablaufinvariante Ausführung konfiguriert werden. Dies kann mit einem einfachen Konfigurationsschritt in LabVIEW erfolgen. Zum Festlegen dieser Eigenschaft wählen Sie „File >> VI Properties“ (Datei >> VI-Einstellungen) und dann die Kategorie „Execution“ (Ausführung) aus. Aktivieren Sie dann das Kontrollkästchen „Reentrant execution“ (Ablaufinvariante Ausführung) wie in Abbildung 6 dargestellt.
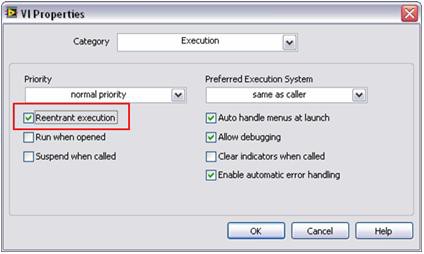
Abbildung 6: Mit diesem einfachen Schritt können Sie wie bei Standardanalysefunktionen in LabVIEW mehrere benutzerdefinierte Unterprogramme parallel ausführen.
So ermöglichen einfache Programmierverfahren eine erhebliche Leistungssteigerung von automatisierten Testanwendungen auf Multicore-Prozessoren.
Optimieren von Hardware-in-the-Loop-Anwendungen
Eine zweite Anwendung, die von parallelen Signalverarbeitungstechniken profitiert, ist die Nutzung mehrerer Messgeräte für gleichzeitige Ein- und Ausgabe. Im Allgemeinen werden diese als Hardware-in-the-Loop- (HIL) oder Inline-Verarbeitungs-Anwendungen bezeichnet. Die Signalerfassung erfolgt entweder mit einem Hochgeschwindigkeitsdigitalisierer oder einem Hochgeschwindigkeits-Digital-I/O-Modul. In Ihrer Software wird ein Algorithmus zur digitalen Signalverarbeitung ausgeführt. Das Ergebnis wird schließlich von einem anderen modularen Messgerät erzeugt. Ein typisches Blockdiagramm ist in Abbildung 7 dargestellt.

Abbildung 7: Dieses Diagramm zeigt die Schritte in einer typischen Hardware-in-the-Loop-Anwendung (HIL).
Zu den gängigen HIL-Anwendungen gehören die digitale Inline-Signalverarbeitung (wie Filterung und Interpolation), Sensorsimulation und benutzerdefinierte Komponentenemulation. Mithilfe verschiedener Verfahren lässt sich der beste Durchsatz bei Anwendungen zur digitalen Inline-Signalverarbeitung erzielen.
In der Regel können Sie zwei grundlegende Programmierstrukturen verwenden: die Single-Loop-Struktur und die Pipeline-Struktur (Multiloop) mit Warteschleifen. Die Single-Loop-Struktur ist einfach zu implementieren und bietet niedrige Latenz für kleine Blockgrößen. Im Gegensatz dazu sind Multiloop-Architekturen in der Lage, einen viel höheren Durchsatz zu erzielen, da sie Multicore-Prozessoren besser nutzen.
Bei der herkömmlichen Single-Loop-Methode sind eine Hochgeschwindigkeitsdigitalisierer-Lesefunktion, ein Signalverarbeitungsalgorithmus und eine Hochgeschwindigkeits-Digital-I/O-Schreibfunktion sequenziell angeordnet. Wie im Blockdiagramm in Abbildung 8 dargestellt, muss jedes dieser Unterprogramme nacheinander ausgeführt werden, wie dies durch das LabVIEW-Programmiermodell festgelegt ist.
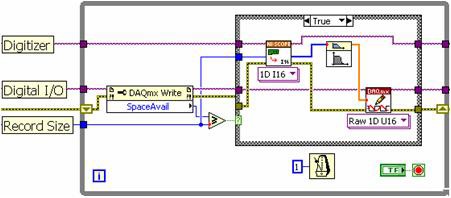
Abbildung 8: Bei der Single-Loop-Methode in LabVIEW werden alle Unterprogramme nacheinander ausgeführt.
Die Single-Loop-Struktur unterliegt verschiedenen Einschränkungen. Da ein Schritt nach dem anderen ausgeführt wird, kann der Prozessor während der Verarbeitung der Daten nur eingeschränkt Instrumenten-I/O durchführen. Mit diesem Ansatz kann eine Multicore-CPU nicht effizient genutzt werden, da der Prozessor jeweils nur eine Funktion ausführt. Während die Single-Loop-Struktur für niedrigere Erfassungsraten ausreicht, ist für einen höheren Datendurchsatz ein Multiloop-Ansatz erforderlich.
Die Multiloop-Architektur verwendet Warteschleifen-Strukturen, um Daten zwischen den einzelnen While-Schleifen auszutauschen. In Abbildung 9 ist diese Programmierung zwischen While-Schleifen mit einer Warteschleifen-Struktur dargestellt.
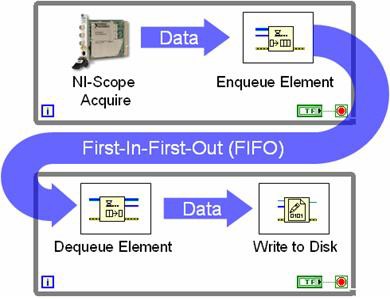
Abbildung 9: Mit Warteschleifen-Strukturen können mehrere Schleifen Daten gemeinsam nutzen.
In Abbildung 9 ist eine sogenannte Erzeuger-Verbraucher-Schleifenstruktur dargestellt. In diesem Fall erfasst ein Hochgeschwindigkeitsdigitalisierer Daten in einer Schleife und übermittelt während jeder Iteration einen neuen Datensatz an den FIFO. Die Verbraucherschleife überwacht einfach den Warteschleifen-Status und schreibt alle Datensätze auf den Datenträger, sobald diese verfügbar sind. Der Vorteil der Verwendung von Warteschleifen besteht darin, dass beide Schleifen unabhängig voneinander ausgeführt werden. Im obigen Beispiel fährt der Hochgeschwindigkeitsdigitalisierer mit der Erfassung von Daten fort, selbst wenn es beim Schreiben der Daten auf den Datenträger eine Verzögerung gibt. Die zusätzlichen Samples werden in der Zwischenzeit einfach im FIFO gespeichert. Im Allgemeinen ermöglicht der Pipeline-Ansatz mit Erzeuger-Verbraucher einen höheren Datendurchsatz bei effizienterer Prozessorauslastung. Dieser Vorteil wird bei Multicore-Prozessoren noch deutlicher, da LabVIEW jedem Kern dynamisch Prozessor-Threads zuweist.
Für eine Inline-Signalverarbeitungsanwendung können drei unabhängige While-Schleifen und zwei Warteschleifen-Strukturen zum Austauschen von Daten verwendet werden. In diesem Szenario erfasst eine Schleife Daten von einem Messgerät, eine weitere führt die Signalverarbeitung durch und die dritte schreibt Daten an ein zweites Messgerät.
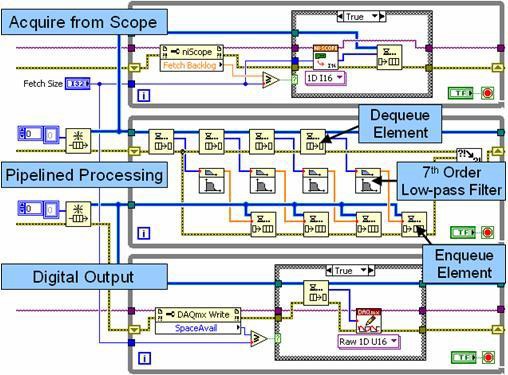
Abbildung 10: Dieses Blockdiagramm veranschaulicht die Pipeline-Signalverarbeitung mit mehreren Schleifen und Warteschleifen-Strukturen.
Die obere Schleife in Abbildung 10 ist eine Erzeugerschleife, die Daten von einem Hochgeschwindigkeitsdigitalisierer erfasst und sie an die erste Warteschleifen-Struktur (FIFO) weitergibt. Die mittlere Schleife fungiert sowohl als Erzeuger als auch als Verbraucher. Während jeder Iteration entnimmt sie mehrere Datensätze aus der Warteschleifen-Struktur und verarbeitet diese unabhängig voneinander in einer Pipeline. Dieser Pipeline-Ansatz verbessert die Leistung in Multicore-Prozessoren, indem bis zu vier Datensätze unabhängig voneinander verarbeitet werden. Beachten Sie, dass die mittlere Schleife auch als Erzeuger fungiert, indem die verarbeiteten Daten in die zweite Warteschleifen-Struktur geleitet werden. Schließlich schreibt die untere Schleife die verarbeiteten Daten an ein Hochgeschwindigkeits-Digital-I/O-Modul.
Parallele Verarbeitungsalgorithmen verbessern die Prozessorauslastung auf Multicore-CPUs. Tatsächlich hängt der Gesamtdurchsatz von zwei Faktoren ab: Prozessorauslastung und Busübertragungsgeschwindigkeiten. Im Allgemeinen arbeiten CPU und Datenbus am effizientesten, wenn große Datenblöcke verarbeitet werden. Darüber hinaus können Sie mit PXI-Express-Messgeräten, die schnellere Übertragungsraten ermöglichen, Datenübertragungszeiten noch weiter verkürzen.
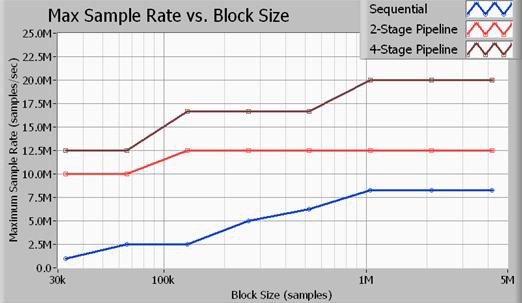
Abbildung 11: Der Durchsatz von Multiloop-Strukturen ist viel höher als der von Single-Loop-Strukturen.
Abbildung 11 zeigt den maximalen Durchsatz in Bezug auf die Sample-Rate abhängig von der Erfassungsgröße in Samples. Alle hier dargestellten Benchmarks wurden an 16-Bit-Samples durchgeführt. Darüber hinaus war der verwendete Signalverarbeitungsalgorithmus ein Butterworth-Tiefpassfilter 7. Ordnung mit einer Grenzfrequenz des 0,45-fachen der Sample-Rate. Wie die Daten zeigen, wird mit dem vierstufigen Pipeline-Ansatz (Multiloop) der größte Datendurchsatz erzielt. Eine zweistufige Signalverarbeitungsmethode ist zwar leistungsfähiger als die Single-Loop-Methode (sequenziell), aber der Prozessor wird nicht so effizient genutzt wie bei der vierstufigen Methode. Die oben aufgeführten Sample-Raten sind die maximalen Sample-Raten für Ein- und Ausgang am Hochgeschwindigkeitsdigitalisierer NI PXIe-5122 und Hochgeschwindigkeits-Digital-I/O-Modul NI PXIe-6537. Beachten Sie, dass der Anwendungsbus bei 20 MS/s Daten mit einer Rate von 40 MB/s für den Eingang und von 40 MB/s für den Ausgang überträgt, was einer Gesamtbandbreite von 80 MB/s entspricht.
Es ist auch wichtig zu berücksichtigen, dass die Pipeline-Verarbeitung eine Latenz zwischen Ein- und Ausgang verursacht. Die Latenz hängt von verschiedenen Faktoren ab, unter anderem von der Blockgröße und der Sample-Rate. In den Tabellen 1 und 2 wird die gemessene Latenz in Abhängigkeit von der Blockgröße und der maximalen Sample-Rate für die Single-Loop-Architektur und die vierstufige Multiloop-Architektur dargestellt.
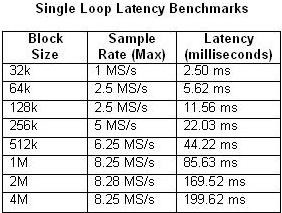
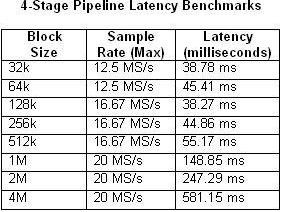
Tabellen 1 und 2: Diese Tabellen veranschaulichen die Latenz von Single-Loop- und vierstufigen Pipeline-Benchmarks.
Wie zu erwarten ist, erhöht sich die Latenz, wenn sich die CPU-Auslastung der 100-Prozent-Auslastung nähert. Dies wird besonders deutlich in dem Beispiel der vierstufigen Pipeline mit einer Sample-Rate von 20 MS/s. Im Gegensatz dazu beträgt die CPU-Auslastung bei keinem der Single-Loop-Beispiele mehr als 50 Prozent.
Fazit
PC-basierte Messgeräte wie die modularen Messgeräte PXI und PXI Express profitieren erheblich von den Fortschritten bei der Multicore-Prozessortechnologie und höheren Datenbusgeschwindigkeiten. Da neue CPUs die Leistung durch das Hinzufügen mehrerer Verarbeitungskerne verbessern, sind parallele oder Pipeline-Verarbeitungsstrukturen erforderlich, um die CPU-Effizienz zu maximieren. Glücklicherweise löst LabVIEW diese Programmierherausforderungen durch die dynamische Zuweisung von Verarbeitungsaufgaben zu den einzelnen Verarbeitungskernen. Wie Sie hier sehen, können Sie erhebliche Leistungssteigerungen erzielen, indem Sie LabVIEW-Algorithmen so strukturieren, dass die Vorteile der parallelen Verarbeitung genutzt werden.