ni.com is currently experiencing issues.
Support teams are actively working on the resolution.
ni.com is currently experiencing issues.
Support teams are actively working on the resolution.

Bei der Programmierung von Multicore-Anwendungen müssen besondere Überlegungen angestellt werden, um die Leistung heutiger Prozessoren nutzen zu können. In diesem Artikel geht es um Pipelining, ein Verfahren, mit dem bei der Ausführung eines an sich seriellen Tasks eine Leistungsverbesserung (auf einer Multicore-CPU) erzielt werden kann.
In der heutigen Welt der Multicore-Prozessoren und Multithread-Anwendungen müssen Programmierer ständig darüber nachdenken, wie sie bei der Entwicklung ihrer Anwendungen die Leistung modernster CPUs am besten nutzen können. Obwohl es schwierig sein kann, parallelen Programmcode in traditionellen befehlsorientierten Programmiersprachen zu erstellen und zu visualisieren, ermöglichen grafische Entwicklungsumgebungen wie NI LabVIEW Ingenieuren und Wissenschaftlern zunehmend, ihre Entwicklungszeiten zu verkürzen und ihre Ideen schnell umzusetzen.
Da NI LabVIEW an sich parallel ist (basierend auf dem Datenfluss), können Multithread-Anwendungen in der Regel sehr einfach programmiert werden. Unabhängige Tasks im Blockdiagramm werden automatisch parallel ausgeführt, ohne dass dabei für den Programmierer zusätzliche Arbeit anfällt. Aber was ist mit Teilen des Programmcodes, die nicht unabhängig sind? Wie muss bei der Implementierung von an sich seriellen Anwendungen vorgegangen werden, um die Leistung von Multicore-CPUs zu nutzen?
Eine weit verbreitete Methode zur Verbesserung der Leistung von seriellen Software-Tasks ist Pipelining. Einfach ausgedrückt ist Pipelining der Prozess, bei dem eine serielle Aufgabe in konkrete Stufen unterteilt wird, die wie an einem Fließband ausgeführt werden können.
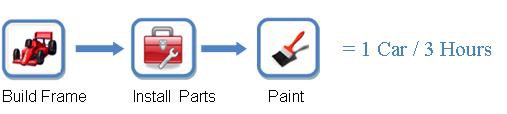
Stellen Sie sich das folgende Beispiel vor: Angenommen, Sie fertigen Autos an einem automatisierten Fließband. Ihre Endaufgabe ist der Bau eines kompletten Autos, doch Sie können diese Aufgabe in drei konkrete Stufen unterteilen: den Bau des Fahrgestells, das Einsetzen der Bauteile (z. B. des Motors) und die Lackierung des Autos, wenn es fertig ist.
Angenommen, der Bau des Fahrgestells, das Einsetzen der Bauteile und die Lackierung dauern jeweils eine Stunde. Wenn Sie also immer nur ein Auto bauen würden, fielen pro Auto jeweils drei Stunden für die Fertigstellung an (siehe Abbildung 1 unten).
Abbildung 1: In diesem Beispiel (ohne Pipelining) dauert der Bau eines Autos 3 Stunden.
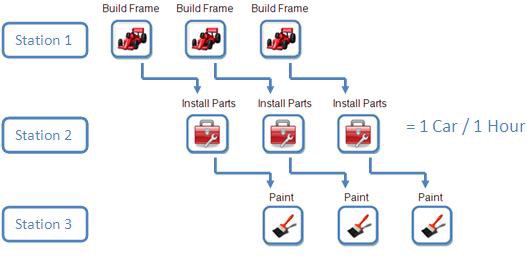
Wie kann dieser Prozess verbessert werden? Was wäre, wenn wir eine Station für den Fahrgestellbau, eine weitere für das Einsetzen der Bauteile und eine dritte für die Lackierung einrichten würden? Während ein Auto lackiert wird, können in ein zweites Auto Bauteile eingesetzt werden und für ein drittes Auto kann das Fahrgestell gebaut werden.
Zwar werden mit unserem neuen Verfahren für die Fertigstellung der einzelnen Autos noch immer drei Stunden benötigt, doch wir können jetzt ein Auto pro Stunde statt eines alle drei Stunden fertigen – das entspricht einer Verdreifachung des Durchsatzes im Fahrzeugfertigungsprozess. Beachten Sie, dass dieses Beispiel zur Veranschaulichung vereinfacht wurde. Weitere Informationen zum Pipelining finden Sie im Abschnitt „Wichtige Bedenken“ unten.
Abbildung 2: Pipelining kann den Durchsatz Ihrer Anwendung beträchtlich erhöhen.
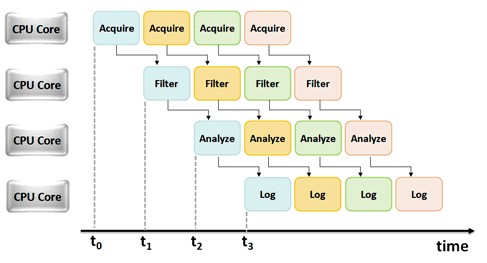
Das gleiche Pipelining-Konzept, das im Beispiel mit dem Auto veranschaulicht wurde, kann auf jede LabVIEW-Anwendung angewendet werden, in der Sie einen seriellen Task ausführen. Grundsätzlich können Sie mit Hilfe von LabVIEW-Schieberegistern und Rückkopplungsknoten aus jedem Programm ein „Fließband“ erstellen. Die folgende konzeptionelle Abbildung zeigt, wie eine Beispielanwendung mit Pipelining auf mehreren CPU-Kernen ausgeführt werden kann:
Abbildung 3. Diagramm zur Zeitsteuerung für eine Pipeline-Anwendung, die auf mehreren CPU-Kernen ausgeführt wird.
Bei der Entwicklung realer Multicore-Anwendungen mit Pipelining muss ein Programmierer mehrere wichtige Aspekte beachten. Insbesondere der Ausgleich von Pipeline-Stufen und die Minimierung der Speicherübertragung zwischen Kernen sind entscheidend für die Realisierung von Leistungsverbesserungen mit Pipelining.
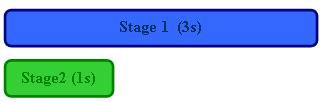
Sowohl in der Automobilfertigung als auch bei den obigen Beispielen für LabVIEW wurde davon ausgegangen, dass jede Pipeline-Stufe gleich viel Zeit in Anspruch nimmt. Wir können davon ausgehen, dass diese beispielhaften Pipeline-Stufen ausgeglichen waren. In realen Anwendungen ist dies jedoch selten der Fall. Betrachten Sie das folgende Diagramm: Wenn Stufe 1 dreimal so lange dauert wie Stufe 2, führt das Pipelining der beiden Stufen nur zu einer minimalen Leistungsverbesserung.
Ohne Pipeline (Gesamtzeit = 4 s):
Mit Pipeline (Gesamtzeit = 3 s):
Hinweis: Leistungsverbesserung = 1,33-fach (kein idealer Fall für Pipelining)
Um hier Abhilfe zu schaffen, muss der Programmierer Tasks von Stufe 1 in Stufe 2 verschieben, bis beide Stufen etwa die gleiche Ausführungszeit aufweisen. Bei einer großen Anzahl von Pipeline-Stufen kann dies eine schwierige Aufgabe sein.
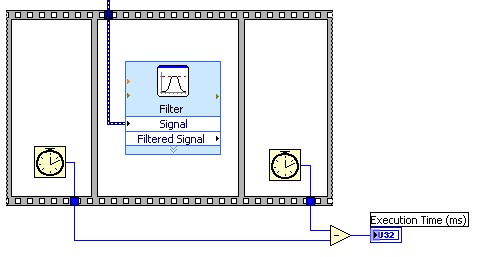
In LabVIEW ist es hilfreich, jede Ihrer Pipeline-Stufen zu benchmarken, um sicherzustellen, dass die Pipeline ausgeglichen ist. Dies lässt sich am einfachsten mit einer flachen Sequenzstruktur in Verbindung mit der Funktion „Timer-Wert (ms)“ gemäß Abbildung 4 erreichen.
Abbildung 4. Benchmarken Sie Ihre Pipeline-Stufen, um sicherzustellen, dass eine ausgeglichene Pipeline vorliegt.
Die Übertragung großer Datenmengen zwischen Pipeline-Stufen sollte nach Möglichkeit vermieden werden. Da die Stufen einer bestimmten Pipeline auf separaten Prozessorkernen ausgeführt werden können, kann jede Datenübertragung zwischen den einzelnen Stufen zu einer Speicherübertragung zwischen physischen Prozessorkernen führen. Wenn sich zwei Prozessorkerne keinen gemeinsamen Cache teilen (oder die Speicherübertragungsgröße die Cachegröße überschreitet), kann das Pipelining beim Endnutzer weniger effektiv sein.
Zusammenfassend lässt sich sagen, dass Pipelining ein Verfahren ist, mit dem Programmierer die Leistung von an sich seriellen Anwendungen (auf Multicore-Computern) verbessern können. Der Trend der CPU-Industrie, die Anzahl der Kerne pro Chip zu erhöhen, bedeutet, dass Strategien wie Pipelining in naher Zukunft für die Anwendungsentwicklung unerlässlich sein werden.
Um größtmögliche Leistungsverbesserungen durch Pipelining zu erzielen, müssen einzelne Stufen sorgfältig ausgeglichen werden. So wird vermieden, dass keine Stufe wesentlich länger dauert als die anderen Stufen. Darüber hinaus sollte die Datenübertragung zwischen Pipeline-Stufen minimiert werden, um eine Leistungsminderung aufgrund des Speicherzugriffs von mehreren Kernen zu vermeiden.