マルチコアプロセッシングのプログラミング手法: データの並列処理
概要

内容
マルチコアプロセッサによって演算能力の向上を目指すハードウェアが増えつつある現在、ソフトウェアプログラマは並列演算を生かすための新しいプログラミング手法を模索する必要があります。マルチコアプロセッサの能力を生かす手法の1つに、データの並列処理が挙げられます。
データの並列処理
データの並列処理とは、大きなデータセットを小さく分割して並列処理するプログラミング手法です。処理したデータは、1つのデータセットに統合されます。この手法により、既存のプロセスをマルチコア処理能力を活用するように変更することができます。
図1の例は、大規模データをシングルプロセッサで処理する様子を示しています。この例の場合、最初のプロセッサにデータセット全体の処理負荷が掛かっている一方、他の使用可能な3つのCPUコアはアイドル状態となっています。
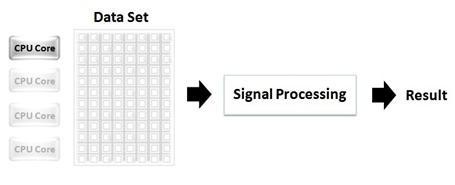
図1. 1つのCPUコアで大規模なデータセットを処理しその他のCPUコアがアイドル状態になっている従来型のプログラミング手法
図2では、データの並列処理を実装することで、クアッドコアプロセッサの処理能力が最大限に活かされています。この例では、大規模データセットが4つのサブセットに分割されています。各サブセットは、個々のコアに割り当てられ、処理されます。処理が完了すると、これらのサブセットは1つの完全なデータセットに統合されます。
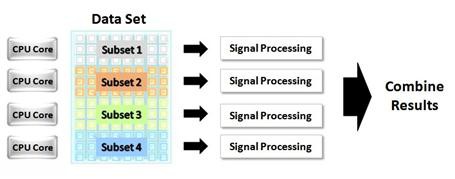
図2. データ並列処理のプログラミング手法により大規模データセットを複数のCPUコアで並列化
NI LabVIEWのグラフィカルプログラミングパラダイムは、並列データアーキテクチャに最適です。マルチスレッドアプリケーションの開発に高度なプログラミング知識を必要とする従来のテキストベースの言語と対照的に、NI LabVIEWでは、直感的かつ簡単に並列処理をプログラミングできます。
LabVIEWでのデータの並列処理
図3のコードは、行列1、行列2の乗算を示しています。これは、2つの大規模な行列の乗算を行う際のLabVIEWでの標準的な実装です。
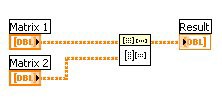
図3. データの並列処理を行わないLabVIEWにおける行列乗算の標準実装
このような演算は、データセットが大きい場合、非常に長い時間がかかる可能性があります。図3のコードで、マルチコアプロセッサの演算能力を活かすには、「行列乗算」VIがマルチスレッド化されマルチコアプロセッサ用に最適化されている必要があります。一方、図4のコードは、データの並列処理によってデュアルコアプロセッサを使用することで、図3のコードに比べて非常に高速に処理を実行できます。
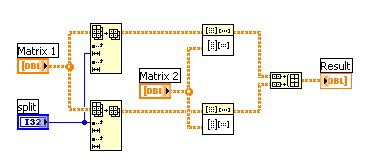
図4. 行列を2つに分割して2つのCPUコアで同時に処理することでデータの並列化を図ったLabVIEWコード
LabVIEWでこの手法を使用してマルチコアプロセッサによるパフォーマンスの向上を図る場合、「行列乗算」VIが再入可能である必要があります。「行列乗算」VIが再入可能でないと、個々のインスタンスが同時に単独で実行されません。
以下の表は、入力行列のサイズを1000 x 1000として図3と図4のLabVIEWコードによる実行時間のベンチマークを示しています。タスクがさらにマルチスレッド化されているため、データの並列化によりシングルコアプロセッサでもパフォーマンスを向上させることができます。デュアルコアプロセッサでは、データの並列化によってパフォーマンスが2倍向上することが分かります。
|
| シングルコアプロセッサでの実行時間 | デュアルコアプロセッサでの実行時間 |
| データ並列化を行わない行列乗算 | 1.195秒 | 1.159秒 |
| データ並列化による行列乗算 | 1.224秒 | 0.629秒 |
データ並列化のアプリケーション
ドイツのミュンヘンにあるMax Planck Instituteでは、ドイツで最も高度な核融合プラットフォームASDEX tokamakのプラズマ制御を行うLabVIEWプログラムにデータ並列化を適用しました。このプログラムは、オクタルコアサーバで実行され、1 msの制御ループレートを維持するために8つのCPUで演算集中型の行列演算を実行します。研究者グループのトップであるLouis Giannone氏は、「LabVIEWで開発した制御アプリケーションの最初の設計段階では、オクタルコアプロセッサマシンを使用することでシングルコアプロセッサの20倍の処理速度を実現し、また1 msの制御ループレート要件を満たすことができました。」と述べています。
プログラマは、データの並列化などの手法により、マルチコアプロセッシングの能力を存分に活用できます。もともと並列的ではないプロセスを並列的なストラクチャに変更することで、マルチコアプロセッサの可能性を最大限に引き出すことができます。LabVIEWは、コードの並列化を簡潔に表せます。