マルチコアプロセッサ対応の自動テストアプリケーションをNI LabVIEWで最適化
概要
マルチコアプログラミングの基礎ホワイトペーパーシリーズの一環です

マルチコアプログラミングの基礎ホワイトペーパーシリーズ
LabVIEWは、自動テストアプリケーション用の使いやすいグラフィカルプログラミング環境であると同時に、さまざまなCPUコアにコードを動的に割り当てる機能を備えているため、マルチコアプロセッサ上での実行速度を高めることが可能な性質を持っています。並列プログラミングテクニックを最大限に活用したLabVIEWアプリケーションを作成する方法を説明します。
内容
- マルチスレッドプログラミングの課題
- 並列テストアルゴリズムの実装
- カスタム並列テストアルゴリズムの構成
- HIL (Hardware-In-the-Loop) アプリケーションの最適化
- まとめ
- マルチコアプログラミングに関連するその他のリソース
マルチスレッドプログラミングの課題
プロセッサテクノロジにおけるイノベーションとは、つい最近までクロックレートの高いCPUを採用することでした。ただしクロックレートが理論上の物理的限界に近づくと、複数のプロセッサコアを搭載した新しいプロセッサが開発されるようになりました。そのような新しいマルチコアプロセッサを使用すると、並列プログラミングテクニックを使って自動テストアプリケーションの開発を行うことで最高の性能とスループットを実現できます。カリフォルニア大学バークレー校の電気/コンピュータ工学教授、Edward Lee博士は、並列処理の利点について次のように述べています。
「これから並列コンピュータアーキテクチャに移り変わっていくことによって、ムーアの法則は終わりを告げるであろうと、多くの技術者は予想しています。今後もコンピュータの性能を高めていきたいのなら、並列処理を採用したプログラムが必要です」
さらに、プログラミングアプリケーションでマルチコアプロセッサのメリットを活用するのは極めて難易度が高いと、専門家も認識しています。マイクロソフト社のビル・ゲイツ氏も、次のように述べています。
「並列で処理するプロセッサのパワーを存分に活用するには、ソフトウェアの方で同時並行性の問題に対処しなくてはなりません。ただしマルチスレッドコードを書いたことのある開発者なら、それが如何に難しいタスクかよくわかっているはずです」
NI LabVIEWソフトウェアは、複数のスレッドを特定のアプリケーションにダイナミックに割り当てることが可能な並列アルゴリズムを作成できる直観的なAPIを備えた、理想的なマルチコアプロセッサプログラミング環境です。実際に、マルチコアプロセッサを利用した自動テストアプリケーションで、最高性能を実現することができます。
さらに、PCI Expressバスの高データ転送レートを利用したPXI Expressモジュール式計測器を使用すれば、そのようなメリットをさらに強化することが可能です。マルチコアプロセッサとPXI Express計測器のメリットを活用したアプリケーションの例として、マルチチャンネル信号解析とインライン処理 (HIL: hardware in the loop) があります。このホワイトペーパーでは、様々な並列プログラミングテクニックを紹介するとともに、それぞれのテクニックの性能上のメリットについて解説します。
並列テストアルゴリズムの実装
並列処理のメリットを引き出せる一般的な自動テストアプリケーションの1つに、マルチチャンネル信号解析があります。周波数解析はプロセッサ負荷の大きい操作であるため、テストコードを並列で実行して各チャンネルの信号処理を複数のプロセッサコアに分散することで、実行速度を向上させることができます。プログラマが唯一行わなくてはならない変更は、テストアルゴリズムの簡単な再構成のみです。
ここで、高速デジタイザの2チャンネル上でマルチチャンネル周波数解析 (高速フーリエ変換: FFT) を行う2つのアルゴリズムの実行時間を比較してみます。NI PXIe-5122 14ビット高速デジタイザは、2つのチャンネルを使用して最大サンプリングレート (100 MS/s) で信号を集録します。まず、LabVIEWを使って従来の逐次型プログラミングモデルでこの操作を行うことを考えてみます。
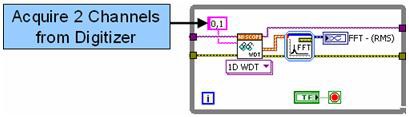
図1.逐次実行型のLabVIEWコード。
図1では、どちらのチャンネルの周波数解析も、各チャンネルを順次解析するFFT Express VIで実行されています。上記のアルゴリズムもマルチコアプロセッサで効果的に実行することは可能ですが、各チャンネルを並列で処理することでアルゴリズムの性能は向上します。
アルゴリズムのプロファイリングを行う際、FFTでは高速デジタイザからの集録に比べ大幅に時間がかかります。各チャンネルを一度に1つずつフェッチして2つのFFTを並列で実行することで、処理時間を大幅に短縮することが可能です。図2は、並列方式を採用した新しいLabVIEWブロックダイアグラムを示しています。
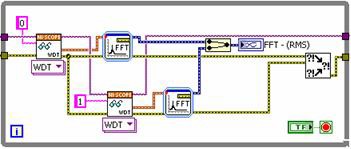
図2.並列実行型のLabVIEWコード。
各チャンネルは、デジタイザから逐次的にフェッチされます。いずれのチャンネルも別個の計測器からフェッチすれば、それらの操作を完全に並列で行うことが可能な点にご注意ください。ただし、FFTはプロセッサに負荷がかかるため、信号処理を単に並列で行うだけで、性能の向上につながります。その結果、総実行時間が短縮されます。図3は両実装形式の実行時間を比較したものです。
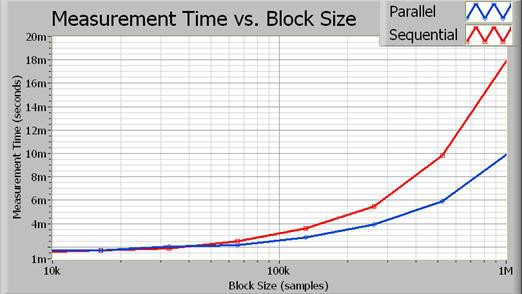
図3.ブロックサイズが大きくなると、並列実行による実行時間の短縮がより顕著になる。
並列アルゴリズムの場合大きなブロックサイズでは性能が倍近くに向上していることがわかります。図4は、集録サイズ (単位: サンプル数) に応じた性能の向上を%で表したものです。
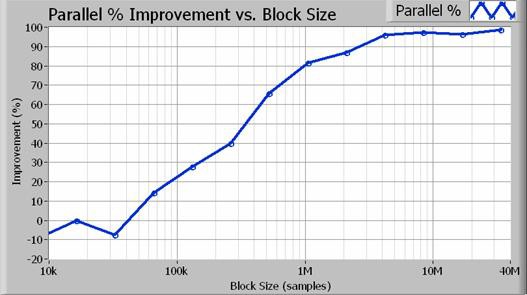
図4.ブロックサイズが100万サンプルより大きい (100 Hzの分解能帯域幅) 場合、並列処理では80%以上の性能向上が見られる。
LabVIEWを使って各スレッドをダイナミックに割り当てるため、マルチコアプロセッサでは自動テストアプリケーションの性能を簡単に高めることができます。実際、マルチスレッドを有効にするための特別なコードを作成する必要もありません。代わりに、並列テストアプリケーションでは、最小限のプログラミング修正でマルチコアプロセッサのメリットを最大限に活用することができます。
カスタム並列テストアルゴリズムの構成
並列信号処理アルゴリズムを利用すると、LabVIEWはプロセッサを複数のコア間で分割して使用することができます。図5は、CPUがアルゴリズムの各部分を処理する順序を示しています。
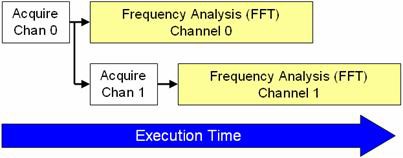
図5.LabVIEWは多くの集録データを並列で処理することで実行時間の短縮が可能。
並列処理を行う場合は、LabVIEWで各信号処理サブルーチンのコピー (クローン) を作成する必要があります。多くのLabVIEW信号処理アルゴリズムは、デフォルトで「再入可能実行」として構成されています。 つまり、LabVIEWは個々のスレッドやメモリスペースなど、各サブルーチンの特定のインスタンスをダイナミックに割り当てるということです。そのため、再入可能形式で動作するようカスタムサブルーチンを構成することが必要となります。これは、LabVIEWで簡単な構成手順で行うことができます。このプロパティを設定するには、ファイル→VIプロパティを選択して、「実行」カテゴリを選択します。次に、図6に示すように「再入可能実行」フラグを選択します。
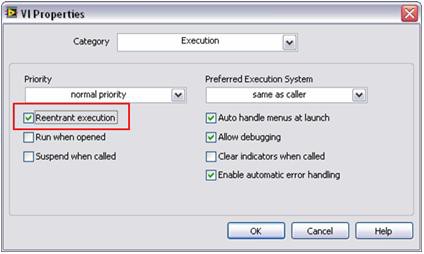
図6.標準のLabVIEW解析関数のような簡単な手順で複数のカスタムサブルーチンを並列で実行可能。
このように簡単なプログラミングテクニックを使用して、マルチコアプロセッサで自動テストアプリケーションの性能を向上できます。
HIL (Hardware-In-the-Loop) アプリケーションの最適化
並列信号処理テクニックのメリットを活用できる2つ目のアプリケーションは、複数の計測器を使用した同時入出力です。一般にHIL (Hardware-In-the-Loop) またはインライン処理アプリケーションと呼ばれるものです。ここでは、高速デジタイザまたは高速デジタルI/Oモジュールを使用して、信号を集録するアプリケーションです。ソフトウェアでは、デジタル信号処理アルゴリズムを実行します。そして、結果は別のモジュール式計測器によって生成されます。一般的なブロックダイアグラムを図7に示します。

図7.一般的なHIL (Hardware-In-the-Loop) アプリケーションの手順。
一般的なHILアプリケーションには、インラインデジタル信号処理 (フィルタ処理や補間)、センサシミュレーション、カスタムコンポーネントのエミュレーションなどがあります。複数のテクニックを使用することで、インラインデジタル信号処理アプリケーションで最高のスループットを実現することができます。
一般には、シングルループストラクチャとキューを使用したパイプライン型マルチループストラクチャの2種類の基本プログラミングストラクチャを使用することができます。シングルループストラクチャは簡単に実装でき、ブロックサイズが小さくても短い遅延時間を実現できます。一方マルチループアーキテクチャでは、マルチコアプロセッサを効率的に利用するため、さらに高スループットの実現が可能です。
従来のシングルループ方式では、高速デジタイザ読み取り関数、信号処理アルゴリズム、高速デジタルI/O書き込み関数を順番に配置します。図8のブロックダイアグラムが示すように、各サブルーチンはLabVIEWのプログラミングモデルで決められたとおりの順序で実行することが必要です。
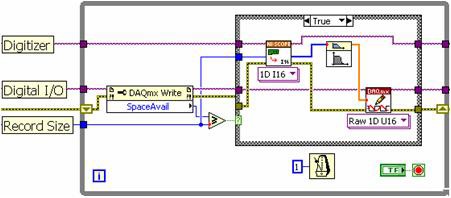
図8.LabVIEWシングルループ方式では各サブルーチンは順次実行する必要がある。
シングルループストラクチャには、いくつかの制約があります。各段階が順次実行されるため、データの処理中はプロセッサが計測器I/Oを行うことが制限されます。この方式の場合、プロセッサは一度に1つの関数しか実行できないため、マルチコアCPUを効率的に使用することができません。集録レートが低い場合はシングルループストラクチャでも十分ですが、高データスループットにはマルチループストラクチャが必要です。
マルチループアーキテクチャでは、キューストラクチャを使用して、各Whileループ間でデータを渡します。図9は、キューストラクチャを使用したWhileループ間でのプログラミングを示しています。
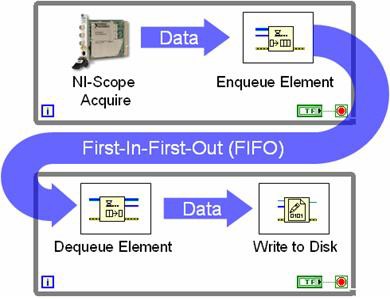
図9.キューストラクチャを使用して複数のループがデータを共有可能。
図9は、一般に生産者/消費者ループストラクチャと呼ばれるものです。この図では、高速デジタイザが1つのループでデータを集録し、各反復で新しいデータセットをFIFOに渡します。消費者ループは単にキューの状態を監視し、各データセットが利用可能になるとそのデータをディスクに書き込みます。キューを使用することで、両ループが互いに依存せずに実行することができます。この例では、高速デジタイザはディスクへの書き込みに遅延が生じていてもデータの集録を続けます。余分なサンプルデータは、その間にFIFOに保存されます。一般にパイプライン型の生産者/消費者方式では、より効率良くプロセッサを使用でき、データスループットも向上します。LabVIEWではプロセッサスレッドを各コアに動的に割り当てるため、上記のようなメリットはマルチコアプロセッサではさらに顕著です。
インライン信号処理アプリケーションでは、3つの独立したWhileループと2つのキューストラクチャを使用して、データの受け渡しが行えます。この場合、1つのループが計測器からデータを集録し、別のループが専用の信号処理を実行し、3番目のループがデータを2つ目の計測器に書き込みます。
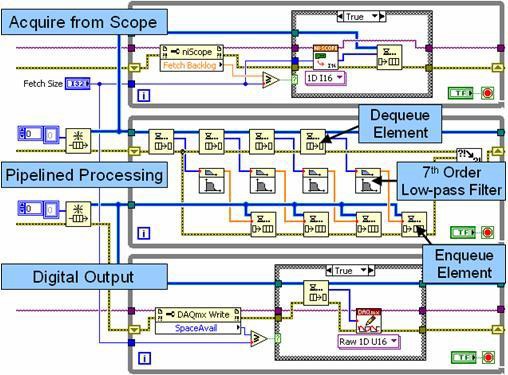
図10.複数のループとキューストラクチャを使用したパイプライン型信号処理を行うブロックダイアグラム。
図10では、上段のループが高速デジタイザからデータを集録し、最初のキューストラクチャ (FIFO) に渡す生産者ループです。中段のループは、生産者と消費者の両方の役割を果たします。このループは各反復の際、キューストラクチャからの複数のデータセットをアンロード (消費) して、パイプライン形式で別々に処理します。このパイプライン方式により、最大4つのデータセットを個別に処理することでマルチコアプロセッサでの性能を高めることができます。中段のループは、生産者として動作し、処理済みデータを2つ目のキューストラクチャに渡すこともある点にご注意ください。最後に、下段のループは処理済みのデータを高速デジタルI/Oモジュールに書き込みます。
並列処理アルゴリズムにより、マルチコアCPUでのプロセッサ使用率を向上させることができます。実際、総スループットは2つの要素―プロセッサの使用率とバス転送速度―に依存します。一般にCPUとデータバスは、大きなデータブロックを処理する際に最も効率的に動作します。また、PXI Express計測器を使用すれば、さらにデータ転送時間を短縮することができます。
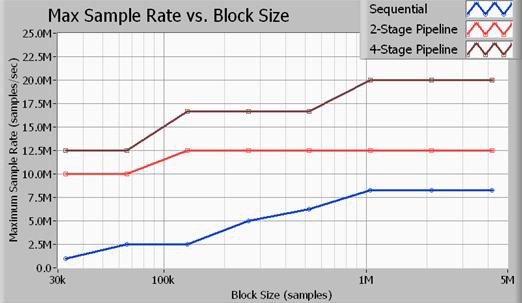
図11.マルチループストラクチャのスループットは、シングルループストラクチャよりはるかに高速である。
図11は、サンプルレートに対する最大スループットを示すもので、集録サイズをサンプル数で表しています。ここに示す全てのベンチマークは、16ビットサンプルに対して行ったものです。また、使用した信号処理アルゴリズムは7次バタワースローパスフィルタで、0.45倍サンプリングレートのカットオフとなっています。データが示すように、4ステージパイプライン型 (マルチループ) 方式を採用した場合のデータスループットが最も高くなります。2ステージ信号処理方式では、シングルループ方式 (順次) に比べれば高い性能を実現できますが、4ステージ方式の場合ほど効率的にプロセッサを使用することはできません。上記のサンプルレートは、NI PXIe-5122高速デジタイザとNI PXIe-6537高速デジタルI/Oモジュールの入力と出力両方の最大サンプルレートです。20 MS/sの場合、アプリケーションバスは入力と出力の両方において40 MB/sでデータを転送するため、全バス帯域幅は80 MB/sとなります。
また、パイプライン型処理方式において入力と出力の間で遅延は発生しないという点も重要な考慮事項です。遅延は、ブロックサイズやサンプルレートなどいくつかの要素によって決まります。以下の表1および2は、シングルループと4ステージマルチループの各アーキテクチャについて、ブロックサイズと最大サンプルレートによる遅延の計測値を比較したものです。
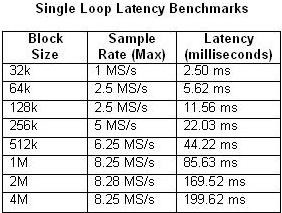
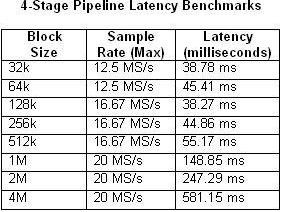
表1および2.これらの表は、単一ループおよび4ステージパイプライン型ベンチマークの遅延時間を表す。
ご想像のとおり、遅延時間は、CPUの使用率が100%に近づくにつれ長くなります。これは、20 MS/sのサンプルレートの場合の4ステージパイプライン型の例で特に顕著です。逆に、シングルループの例でCPU使用率が50%を超えることはほとんどありません。
まとめ
PXI/PXI Expressモジュール式計測器などのPCベースの計測器は、マルチコアプロセッサ技術の進化とデータバスの速度向上によって大きな恩恵がもたらされています。新しいCPUではプロセッサコアを複数搭載することによって性能を高めているため、CPU効率を上げるためには並列またはパイプライン型処理ストラクチャを用いる必要があります。幸いなことに、LabVIEWは処理タスクを個々のプロセッサコアに動的に割り当てるため、そのような難しいプログラミングにも対処できます。上述のように、並列処理の利点を引き出すようにLabVIEWアルゴリズムを構成することで、性能を大幅に向上させることが可能です。