Architecture producteur/consommateur dans LabVIEW
Aperçu
Le modèle de conception producteur/consommateur est basé sur le modèle maître/esclave et cherche à améliorer le partage de données entre plusieurs boucles fonctionnant à des vitesses différentes. Le modèle producteur/consommateur sert à séparer les processus qui produisent et consomment des données à des vitesses différentes. Les boucles parallèles du modèle producteur/consommateur sont réparties en deux catégories : celles qui produisent des données et celles qui consomment les données produites.
Cet article traite des cas d'utilisation courants et des avantages de l'architecture producteur/consommateur et désigne les ressources permettant d'utiliser cette technique dans LabVIEW. Pour procéder à un examen plus approfondi du partage d'informations entre les boucles ou obtenir un guide étape par étape et des exercices permettant de créer une boucle productrice et consommatrice dans LabVIEW, envisagez de suivre notre cours LabVIEW Fondamental 2.
Contenu
- Pourquoi utiliser le modèle producteur/consommateur ?
- Construire un modèle producteur/consommateur
- Informations importantes
- Ressources supplémentaires
Pourquoi utiliser le modèle producteur/consommateur ?
Le modèle producteur/consommateur vous donne la possibilité de gérer facilement plusieurs processus en même temps tout en itérant à des vitesses différentes.
Communication avec buffer
Lorsque plusieurs processus s'exécutent à des vitesses différentes, la communication avec buffer entre les processus est extrêmement efficace. Avec une mémoire avec buffer suffisamment grande, la boucle productrice peut fonctionner à des vitesses beaucoup plus élevées que la boucle consommatrice sans perte de données.
Prenons par exemple une application qui a deux processus : le premier processus effectue l'acquisition de données et le second processus prend ces données et les place sur un réseau. Le premier processus fonctionne à trois fois la vitesse du deuxième processus. Si le modèle de conception producteur/consommateur est utilisé pour implémenter cette application, le processus d'acquisition de données agira en tant que producteur et le réseau traitera le consommateur. Avec une file d'attente de communication (buffer) suffisamment grande, le processus réseau aura accès à une grande quantité de données acquises par la boucle d'acquisition de données. Cette capacité à buffériser les données minimisera la perte de données.
Pour visualiser la communication avec buffer qui se produit lors de l'utilisation des fonctions File d'attente, consultez l'exemple de programme Déplacer la fenêtre LabVIEW à l'aide des boucles productrices et consommatrices
Acquisition de données et traitement
Le modèle producteur/consommateur est couramment utilisé lors de l'acquisition de plusieurs ensembles de données à traiter dans l'ordre.
Supposons que vous souhaitiez écrire une application qui accepte les données tout en les traitant dans l'ordre de réception. Étant donné que la mise en file d'attente (production) de ces données est beaucoup plus rapide que le traitement réel (consommation), le modèle de conception producteur/consommateur est le mieux adapté pour cette application. Cela permettra à la boucle consommatrice de traiter les données à son propre rythme, tout en permettant à la boucle productrice de mettre en file d'attente des données supplémentaires en même temps.
Pensez-y : si le producteur et le consommateur sont dans la même boucle pour cette application, la vitesse d'acquisition de données ralentit pour correspondre à la vitesse de traitement des données. C'est la raison pour laquelle il est avantageux de décomposer votre code par processus, acquisition de données (producteur) et traitement (consommateur).
Communication réseau
La communication réseau nécessite deux processus pour fonctionner en même temps et à des vitesses différentes : le premier processus interrogerait constamment la ligne réseau et récupérerait les paquets, et le second processus prendrait ces paquets récupérés par le premier processus et les analyserait. Dans cet exemple, le premier processus agira en tant que producteur, car il fournit des données au deuxième processus qui agira en tant que consommateur. Cette application bénéficierait de l'utilisation du modèle de conception producteur/consommateur. Les boucles productrice et consommatrice parallèles géreront la récupération et l'analyse des données hors du réseau, et la communication en file d'attente entre les deux permettra la bufférisation des paquets réseau récupérés. Cette bufférisation deviendra très importante lorsque la communication réseau sera occupée. Avec la bufférisation, les paquets peuvent être récupérés et communiqués plus rapidement que leur analyse.
Gestion de messages dans une file d’attente
L’architecture du Gestionnaire de messages dans une file d'attente est une version spécialisée de l’architecture producteur/consommateur. Les files d'attente de données sont utilisées pour communiquer des données entre les boucles dans le modèle de conception producteur/consommateur. Ces files d'attente offrent l'avantage de la bufférisation des données entre les boucles productrice et consommatrice.
Construire un modèle producteur/consommateur
La conception producteur/consommateur se compose de boucles parallèles qui sont divisées en deux catégories : producteurs et consommateurs. La communication entre les boucles productrice et consommatrice se fait à l'aide de files d'attente ou de fils de liaison de voie.
Files d’attente
LabVIEW possède des VIs d'opération de file d'attente intégrés trouvés dans la palette Fonctions >> Communication de données >> Files d'attente.
Les files d'attente sont basées sur la théorie du premier entré/premier sorti. Dans le modèle de conception producteur/consommateur, les files d'attente peuvent être initialisées en dehors des boucles productrice et consommatrice. Puisque la boucle productrice produit des données pour la boucle consommatrice, elle ajoutera des données à la file d'attente (l'ajout de données à une file d'attente est appelé « mise en file d'attente »).
La boucle consommatrice supprimera les données de cette file d'attente (la suppression des données d'une file d'attente est appelée « retrait de la file d'attente »). Étant donné que les files d'attente fonctionnent sur le principe du premier entré/premier sorti, les données seront toujours analysées par le consommateur dans le même ordre de leur placement dans la file d'attente par le producteur. La Figure 1 illustre la manière dont le modèle de conception producteur/consommateur peut être créé dans LabVIEW.
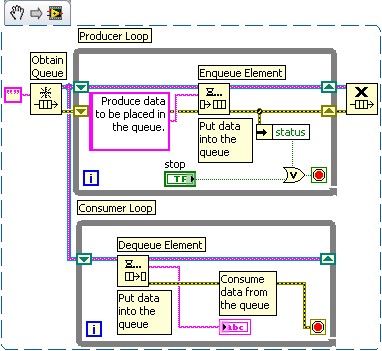
Figure 1 : Modèle de conception producteur/consommateur
Remarque : Cette image est un extrait de LabVIEW qui comprend du code LabVIEW que vous pouvez réutiliser dans votre projet. Pour utiliser un extrait, cliquez avec le bouton droit sur l'image, enregistrez-la sur votre ordinateur et faites glisser le fichier sur votre diagramme LabVIEW.
Il existe des exemples d'utilisation de files d'attente dans LabVIEW que vous pouvez utiliser comme point de départ pour votre application. Trouvez des exemples à l'aide de l'Outil de recherche d'exemples LabVIEW et recherchez File d'attente.
Voies
La fonctionnalité Fil de liaison de voie a été ajoutée dans LabVIEW 2016. Vous pouvez utiliser des fils de liaison de voie pour obtenir les mêmes fonctionnalités que les files d'attente.
Dans les files d'attente, vous configurez la référence de file d'attente (Obtenir une file d'attente), ajoutez des données (Mettre en file d'attente) et supprimez des données (Retirer d’une file d'attente) et fermez la référence de file d'attente (Libérer une file d'attente). Avec les voies, ce processus est simplifié pour ne configurer que l'enregistreur et le lecteur des données.
Pour plus d'informations sur les fils de liaison de voie et la prise en main des modèles, consultez Communication de données entre des sections de code parallèles de code avec des conduits – Aide LabVIEW
Informations importantes
Il y a quelques mises en garde à prendre en compte lors du traitement du modèle de conception producteur/consommateur, comme l'utilisation et la synchronisation de la file d'attente.
Utilisation de la file d'attente
Problème : Les files d'attente sont liées à un type de données en particulier. Par conséquent, chaque élément de données différent qui est produit dans une boucle productrice doit être placé dans différentes files d'attente. Cela pourrait constituer un problème en raison de la complication ajoutée au diagramme.
Solution : Les files d'attente peuvent accepter des types de données tels que le tableau et le cluster. Chaque élément de données peut être placé à l'intérieur d'un cluster. Cela masquera une variété de types de données derrière le type de données de cluster. La Figure 1 implémente les types de données de cluster avec la file d'attente de communication.
Synchronisation
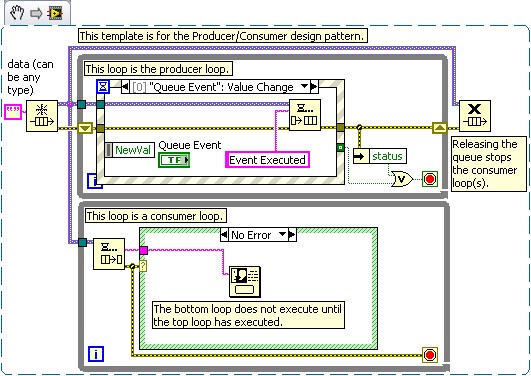
Problème : Étant donné que le modèle de conception producteur/consommateur n'est pas basé sur la synchronisation, l'exécution initiale des boucles ne suit pas un ordre particulier. Par conséquent, l'initialisation d'une boucle avant l'autre peut entraîner un problème.
Solution : L'ajout d'une structure Événement au modèle de conception producteur/consommateur peut résoudre ces types de problèmes de synchronisation. La Figure 2 illustre un modèle qui permet de réaliser cette fonctionnalité. Vous trouvez des informations supplémentaires sur les fonctions de synchronisation ci-dessous dans la section Liens associés.