Stratégies de programmation pour le traitement multicœur : Utilisation de pipeline
Aperçu
série de livres blancs sur les principes fondamentaux de la programmation multicœur

Série de livres blancs sur les principes fondamentaux de la programmation multicœur
Lors de la programmation d’applications multicœurs, il convient de tenir compte de considérations particulières afin d’exploiter la puissance des processeurs actuels. Cet article présente l’utilisation de pipeline, une technique qui permet d’améliorer les performances (sur un processeur multicœur) lors de l’exécution d’une tâche série intrinsèque.
Contenu
- Résumé
- Introduction à l’utilisation de pipeline
- Comment le pipeline améliore-t-il les performances ?
- Utilisation de pipeline de base dans LabVIEW
- Questions importantes
- Conclusion
- Ressources supplémentaires sur la programmation multicœur
Résumé
Dans le monde actuel des processeurs multicœurs et des applications multithread, les programmeurs doivent sans cesse se demander comment exploiter au mieux la puissance des processeurs de pointe lorsqu’ils développent leurs applications. Bien que la structuration du code parallèle dans les langages textuels traditionnels puisse être difficile à programmer et à visualiser, les environnements de développement graphique tels que NI LabVIEW permettent de plus en plus aux ingénieurs et aux scientifiques de réduire leurs temps de développement et de mettre rapidement en œuvre leurs idées.
NI LabVIEW étant intrinsèquement parallèle (basé sur le flux de données), la programmation d’applications multithread s’avère généralement très simple. Les tâches indépendantes du schéma fonctionnel s’exécutent automatiquement en parallèle, sans que le programmeur n’ait rien à faire de plus. Mais qu’en est-il des éléments de code qui ne sont pas indépendants ? Lors de la mise en œuvre d’applications en série par nature, que peut-on faire pour exploiter la puissance des processeurs multicœurs ?
Introduction à l’utilisation de pipeline
L’utilisation de pipeline est une technique largement acceptée pour améliorer les performances des tâches logicielles en série. En termes simples, l’utilisation de pipeline consiste à diviser une tâche en série en étapes concrètes qui peuvent être exécutées à la chaîne.
Prenons l’exemple suivant : imaginons que vous fabriquiez des voitures sur une chaîne de montage automatisée. Votre tâche finale consiste à construire une voiture complète, mais vous pouvez la diviser en trois étapes concrètes : la construction du châssis, l’installation des pièces à l’intérieur (comme le moteur) et la peinture de la voiture lorsqu’elle est terminée.
Supposons que la construction du châssis, l’installation des pièces et la peinture prennent une heure chacune. Si vous ne construisez qu’une seule voiture à la fois, il vous faudra donc trois heures pour la terminer (voir la figure 1 ci-dessous).
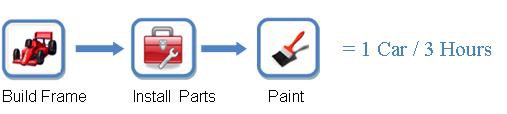
Figure 1. Dans cet exemple (sans utilisation de pipeline), la construction d’une voiture prend 3 heures.
Comment améliorer ce processus ? Et si nous installions une station pour la construction du châssis, une autre pour l’installation des pièces et une troisième pour la peinture ? Ainsi, lors de la peinture d’une voiture, il serait possible d’installer des pièces sur une deuxième voiture et de construire le châssis d’une troisième.
Comment le pipeline améliore-t-il les performances ?
Bien qu’il faille encore trois heures pour terminer chaque voiture avec notre nouveau processus, nous sommes désormais en mesure de produire une voiture toutes les heures au lieu d’une toutes les trois heures, ce qui multiplie par trois le débit du processus de fabrication des voitures. Notez que cet exemple a été simplifié à des fins de démonstration ; voir la section « Questions importantes » ci-dessous pour en savoir plus sur l’« utilisation de pipeline ».
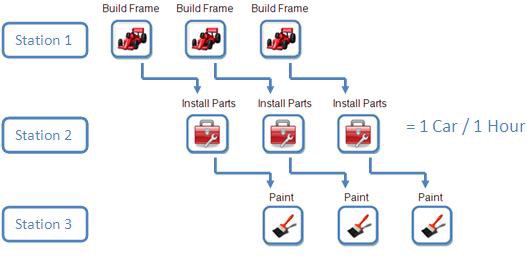
Figure 2. L’utilisation de pipeline augmente considérablement le débit de votre application.
Utilisation de pipeline de base dans LabVIEW
Le même concept de pipelining que celui présenté dans l’exemple de la voiture peut être appliqué à toute application LabVIEW dans laquelle vous exécutez une tâche en série. Essentiellement, vous pouvez utiliser les registres de décalage et les nœuds de rétroaction de LabVIEW pour créer une « chaîne de montage » à partir du programme de votre choix. L’illustration conceptuelle suivante montre comment un exemple d’application en pipeline peut s’exécuter sur plusieurs cœurs de CPU :
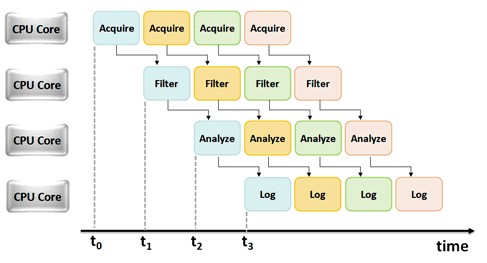
Figure 3. Diagramme de cadencement pour une application avec utilisation de pipeline s’exécutant sur plusieurs cœurs de processeur.
Questions importantes
Lors de la création d’applications multicœurs réelles ayant recours à l’utilisation de pipelines, le programmeur doit tenir compte de plusieurs aspects importants. L’équilibrage des étapes du pipeline et la minimisation du transfert de mémoire entre les cœurs sont notamment essentiels pour réaliser des gains de performance grâce à l’utilisation de pipelines.
Équilibrer les étapes
Dans les exemples de la construction automobile et de LabVIEW ci-dessus, on suppose que l’exécution de chaque étape du pipeline prend le même temps ; on peut dire que ces étapes du pipeline sont équilibrés. C’est toutefois rarement le cas dans les applications réelles. Si l’exécution de l’étape 1 prend trois fois plus de temps que celle de l’étape 2, l’utilisation de pipelines aux deux étapes ne permet qu’une augmentation minime des performances.
Sans utilisation de pipeline (temps total = 4 s) :

Avec utilisation de pipeline (temps total = 3 s) :
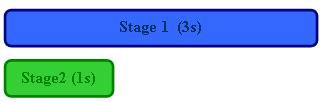
Remarque : Augmentation des performances = X 1,33 (e n’est pas le cas idéal pour l’utilisation de pipeline)
Pour remédier à cette situation, le programmeur doit déplacer les tâches de l’étape 1 à l’étape 2 jusqu’à ce que l’exécution des deux étapes prenne à peu près le même temps. La tâche peut s’avérer difficile si le nombre d’étapes du pipeline est élevé.
Dans LabVIEW, il est utile d’évaluer chaque étape de votre pipeline pour vous assurer qu’il est bien équilibré. Pour ce faire, il est très facile d’utiliser une structure séquence plate en conjonction avec la fonction Tick Count ([compte d’impulsions d’horloge] ms), comme l’explique la figure 4.
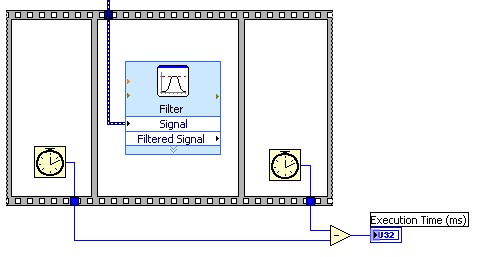
Figure 4. Comparez les étapes de votre pipeline pour vous assurer qu’il est bien équilibré.
Transfert de données entre les cœurs
Dans la mesure du possible, il est préférable d’éviter de transférer de grandes quantités de données entre les étapes du pipeline. Étant donné que les étapes d’un pipeline donné peuvent être exécutées sur des cœurs de processeur distincts, tout transfert de données entre des étapes individuelles peut en fait entraîner un transfert de mémoire entre des cœurs de processeur physiques. Si deux cœurs de processeur ne partagent pas de cache (ou si la taille du transfert de mémoire dépasse la taille du cache), il arrive que l’utilisateur de l’application finale constate une diminution de l’efficacité de la mise en pipeline.
Conclusion
En résumé, l’utilisation de pipelines est une technique que les programmeurs peuvent utiliser pour augmenter les performances des applications en série par nature (sur les machines multicœurs). Les processeurs ayant tendance à augmenter le nombre de cœurs par puce, des stratégies telles que l’utilisation de pipeline deviendront essentielles pour le développement d’applications dans un avenir proche.
Afin d’optimiser l’accroissement des performances grâce au recours aux pipelines, les étapes individuelles doivent être soigneusement équilibrées de manière à ce qu’aucune d’entre elles ne soit bien plus chronophage que d’autres. En outre, tout transfert de données entre les étapes du pipeline doit être réduit au minimum afin d’éviter une baisse des performances due à l’accès à la mémoire à partir de plusieurs cœurs.