Stratégies de programmation pour le traitement multicœur: parallélisation des données
Aperçu
Contenu
- Parallélisation des données
- Parallélisation des données en LabVIEW
- Une application de la parallélisation des données
- Pour plus d’informations sur la programmation multicœur, visitez :
Parallélisation des données
La parallélisation des données est une technique de programmation qui sert à partager un jeu de données de taille importante en fractions susceptibles d’être traitées en parallèle. Après traitement, elles sont recombinées en un seul jeu de données. Avec cette technique, les programmeurs peuvent modifier un process (une application) qui ne serait pas capable, sinon, d’utiliser la puissance du traitement multicœur et donc d’utiliser efficacement toute la puissance de traitement disponible.
Considérez le scénario de la Figure n°1, qui illustre le traitement d’un jeu de données de taille importante par un seul processeur. Dans ce scénario, les trois autres cœurs de l’unité centrale (UC) sont au repos, alors que le premier processeur supporte seul la charge de travail du traitement du jeu complet de données.
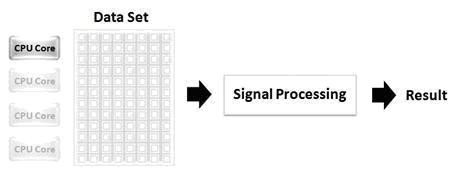
Figure n°1. Dans les méthodes de programmation traditionnelles, un jeu de données de taille importante est traité sur un seul cœur de l’UC, alors que les autres cœurs restent au repos.
Considérez maintenant l’implémentation illustrée à la Figure n°2, qui utilise la parallélisation des données pour améliorer de manière significative la puissance de traitement d’un processeur quadruple-cœur. Dans ce cas, le jeu de données est partagé en quatre sous‑ensembles. Chaque sous-ensemble est ensuite associé à un cœur particulier pour le traitement. À la fin du traitement, les jeux de données sont rassemblés en un seul jeu de données complet.
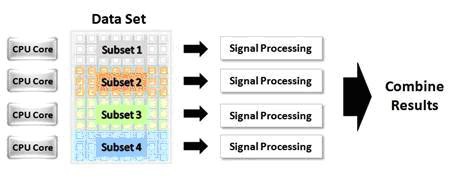
Figure n°2. En utilisant la technique de programmation dite de parallélisation des données, un jeu de données de taille importante peut être traité en parallèle sur plusieurs cœurs d'UC.
Le paradigme de la programmation graphique de LabVIEW de NI est idéal pour les architectures de données parallèles. Le traitement parallèle de LabVIEW est intuitif et simple, contrairement aux langages textuels traditionnels, qui nécessitent des connaissances de programmation avancées pour créer une application multithread.
Parallélisation des données en LabVIEW
Le code de la Figure n°3 présente une opération de multiplication effectuée sur deux matrices, Matrix 1 et Matrix 2. Il s’agit d’une implémentation en LabVIEW de la multiplication de deux matrices de taille importante.
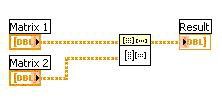
Figure n°3. Implémentation standard de la multiplication de deux matrices en LabVIEW, sans utiliser la parallélisation des données.
Une opération telle que celle-ci peut prendre une quantité importante de temps pour se terminer, particulièrement lorsque des jeux de données de taille importante sont impliqués. Le code de la Figure n°3 ne profite en aucune façon de la puissance de calcul supplémentaire offerte par un processeur multicœur le VI Matrix Multiply soit déjà multithread et entièrement optimisé pour les processeurs multicœur. Au contraire, le code de la Figure n°4 fait usage de la parallélisation des données et permet ainsi d’exécuter l’opération bien plus rapidement sur un processeur double-cœur que le code présenté à la Figure n°3.
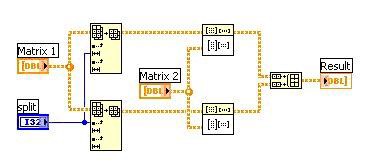
Figure n°4. Ce code LabVIEW illustre la parallélisation des données ; en divisant la matrice en deux parties, l’opération peut être calculée simultanément sur deux cœurs de l’UC.
En utilisant cette technique dans LabVIEW pour accroître les performances sur un processeur multicœur, il est important de se rendre compte qu’une amélioration de performances ne peut pas être obtenue à moins que le VI Matrix Multiply ne soit réentrant. Tant qu’il n’est pas réentrant, les instances séparées du VI Matrix Multiply ne peuvent pas agir indépendamment et de manière concurrente.
Le tableau ci-dessous présente les temps d'exécution du code LabVIEW des Figures 3 et 4, avec des matrices 1000 x 1000 en entrée. Lorsque la parallélisation des données est utilisée, une amélioration de performances est obtenue même sur un processeur simple cœur, parce que la tâche est davantage multithread. Remarquez que les performances sont quasiment doublées sur le processeur double-cœur lorsque la parallélisation des données est utilisée.
|
| Temps d’exécution sur un seul processeur | Temps d’exécution sur un processeur double cœur |
| Multiplication de matrice sans Parallélisation des données | 1,195 secondes | 1,159 secondes |
| Multiplication de matrice avec Parallélisation des données | 1,224 secondes | 0,629 secondes |
Une application de la parallélisation des données
À l’Institut Max Planck de Munich (Allemagne), les chercheurs ont appliqué la parallélisation des données à un programme LabVIEW qui effectue le contrôle du plasma de la plate-forme de fusion nucléaire la plus avancée d’Allemagne : le tokamak ASDEX. Le programme s’exécute sur un serveur octuple-cœur, qui effectue des opérations sur des matrices de taille importante en parallèle sur les huit cœurs de l’UC afin d’assurer une boucle de contrôle de 1 ms. Louis Giannone, chercheur en chef, remarque : "au premier stade de la conception de notre application de contrôle programmée en LabVIEW, nous avons obtenu une accélération du traitement de 20 fois sur une machine à 8 processeurs, par rapport à un processeur simple-cœur, tout en respectant notre exigence de vitesse de la boucle de contrôle de 1 ms".
Avec la parallélisation des données et d’autres techniques similaires les développeurs peuvent exploiter pleinement la puissance de traitement offerte par le multicoeur. La restructuration des process (applications) qui ne sont pas parallèles par nature sous une forme parallèle facilite l’exploitation du potentiel des processeurs multicœurs, alors que de son côté LabVIEW continue de représenter simplement le parallélisme du code.