Producer/Consumer Architecture in LabVIEW
Overview
The Producer/Consumer design pattern is based on the Master/Slave pattern and is geared towards enhanced data sharing between multiple loops running at different rates. The Producer/Consumer pattern is used to decouple processes that produce and consume data at different rates. The Producer/Consumer pattern’s parallel loops are broken down into two categories; those that produce data, and those that consume the data produced.
This article discusses common use cases and benefits for the Producer/Consumer architecture and points to resources for use of this technique in LabVIEW. For a more in-depth look at sharing information between loops or step-by-step guide and exercises to build a Producer/Consumer loop in LabVIEW, consider taking our LabVIEW Core 2 course.
Contents
Why Use Producer/Consumer?
The Producer/Consumer pattern gives you the ability to easily handle multiple processes at the same time while iterating at individual rates.
Buffered Communication
When there are multiple processes running at different speeds, buffered communication between processes is extremely effective. With a large enough buffer, the producer loop can run at much higher speeds than the consumer loop without data loss.
For example, consider an application has two processes – the first process performs data acquisition and the second process takes that data and places it on a network. The first process operates at three times the speed as the second process. If the Producer/Consumer design pattern is used to implement this application, the data acquisition process will act as the producer and the network process the consumer. With a large enough communication queue (buffer), the network process will have access to a large amount of the data that the data acquisition loop acquires. This ability to buffer data will minimize data loss.
To visualize the buffered communication that occurs when using the Queue functions, see the example program Move LabVIEW Window Using Producer/Consumer Loops
Data Acquisition and Processing
The Producer/Consumer pattern is commonly used when acquiring multiple data sets to be processed in order.
Suppose you want to write an application that accepts data while processing them in the order they were received. Because queuing up (producing) this data is much faster than the actual processing (consuming), the Producer/Consumer design pattern is best suited for this application. This will allow the consumer loop to process the data at its own pace, while allowing the producer loop to queue additional data at the same time.
Consider – if both the producer and consumer are in the same loop for this application, the data acquisition speed slows to match the speed of processing the data. This is why is it beneficial to break up your code by process, data acquisition (Producer) and processing (Consumer).
Network Communication
Network communication requires two processes to operate at the same time and at different speeds: the first process would constantly poll the network line and retrieve packets, and the second process would take these packets retrieved by the first process and analyze them. In this example, the first process will act as the producer because it is supplying data to the second process which will act as the consumer. This application would benefit from the use of the Producer/Consumer design pattern. The parallel producer and consumer loops will handle the retrieval and analysis of data off the network, and the queued communication between the two will allow buffering of the network packets retrieved. This buffering will become very important when network communication gets busy. With buffering, packets can be retrieved and communicated faster than they can be analyzed.
Queued Message Handling
The Queued Message Handler architecture is a specialized version of the Producer/Consumer architecture. Data queues are used to communicate data between loops in the Producer/Consumer design pattern. These queues offer the advantage of data buffering between producer and consumer loops.
Build a Producer/Consumer
The Producer/Consumer design consists of parallel loops which are broken down into two categories; producers, and consumers. Communication between producer and consumer loops is done by using queues or channel wires.
Queues
LabVIEW has built-in Queue Operation VIs found in the Functions palette >> Data Communication >> Queue Operations.
Queues are based on the first-in/first-out theory. In the Producer/Consumer design pattern, queues can be initialized outside both the producer and consumer loops. Because the producer loop produces data for the consumer loop, it will be adding data to the queue (adding data to a queue is called “enqueue”).
The consumer loop will be removing data from that queue (removing data from a queue is called “dequeue”). Because queues are first-in/first-out, the data will always be analyzed by the consumer in the same order as they were placed into the queue by the producer. Figure 1 illustrates how the Producer/Consumer design pattern can be created in LabVIEW.
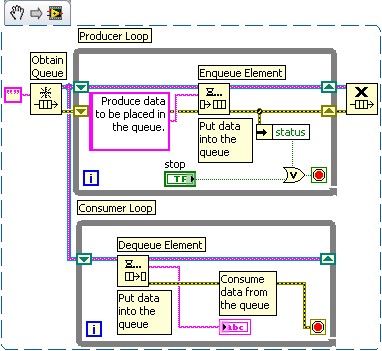
Figure 1: Producer/Consumer Design Pattern
Note: This image is a LabVIEW snippet, which includes LabVIEW code that you can reuse in your project. To use a snippet, right-click the image, save it to your computer, and drag the file onto your LabVIEW diagram.
There are examples for using queues within LabVIEW which you can use as a starting point for your application. Find examples using the LabVIEW Example Finder and search for Queue.
Channels
Channel wire functionality was added in LabVIEW 2016. You can use channel wires to achieve the same functionality as queues.
In queues, you set up the queue reference (Obtain Queue), add data (Enqueue) and remove data (Dequeue), and close the queue reference (Release Queue); with Channels, this process is simplified to only set up the Writer and Reader of the data.
For more information on channel wires and getting started templates, see Communicating Data between Parallel Sections of Code Using Channel Wires – LabVIEW Help
Important Notes
There are some caveats to be aware of when dealing with the Producer/Consumer design pattern such as queue use and synchronization.
Queue use
Problem: Queues are bound to one particular data type. Therefore every different data item that is produced in a producer loop needs to be placed into different queues. This could be a problem because of the complication added to the block diagram.
Solution: Queues can accept data types such as array and cluster. Each data item can placed inside a cluster. This will mask a variety of data types behind the cluster data type. Figure 1 implements cluster data types with the communication queue.
Synchronization
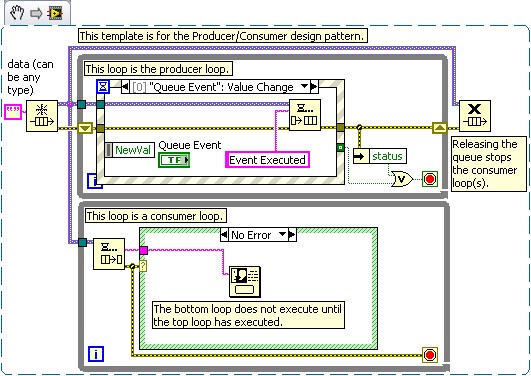
Problem: Since the Producer/Consumer design pattern is not based on synchronization, the initial execution of the loops does not follow a particular order. Therefore, initializing one loop before the other may cause a problem.
Solution: Adding an event structure to the Producer/Consumer design pattern can solve these types of synchronization problems. Figure 2 depicts a template for achieving this functionality. More information pertaining to synchronization functions is located below in the Related Links section.