What Is Serviceability?
Overview
The acronym “RASM” encompasses four separate but related characteristics of a functioning system: reliability, availability, serviceability, and manageability. IBM is commonly noted [1] as one of the first users of the acronym “RAS” (reliability, availability, and serviceability) in the early data processing machinery industry to describe the robustness of its products. The “M” was recently added to RASM to highlight the key role “manageability” plays in supporting system robustness by facilitating many dimensions of reliability, availability, and serviceability. RASM features can contribute significantly to the mission of systems for test, measurement, control, and experimentation as well as their associated business goals.
It would be wonderful if things never failed or needed patches or upgrades, but the reality is that sooner or later all things eventually need service. Therefore the “serviceability” of a system, which affects how efficiently corrective and preventive maintenance can be conducted, is key to the system achieving the availability you need. The expression “time is money” very much applies to the science and art of servicing a system to get it performing its mission as soon as possible.
How serviceable a system is affects how easily, quickly, and frequently you can or will conduct preventive maintenance. For example, as a young boy growing up on a farm, I had to repair a piece of machinery that failed because it was not “greased” properly. In other words, it did not receive proper preventive maintenance. I still remember a comment made by a neighbor farmer when he saw the failed part: “It looks like grease worms ate up all your grease.” I thought to myself ,“Grease worms?” When my neighbor saw the question mark on my face, he laughed at me and said, “If you had greased it more often, it would have lasted a lot longer.” I then explained that it was a real pain to grease this part because I had to dig out the wrenches and remove all of these other parts just to get to the part that I wanted to grease. Thus, it didn’t get greased (serviced) very often!
Serviceability greatly affects the reliability and availability of a system, and manageability greatly affects serviceability. Manageability’s effect on serviceability is clearly seen when considering system management capabilities such as system discovery and deployment, upgradability, health monitoring and error logging, and diagnostics and fault isolation.
Contents
- Definition of Serviceability
- Serviceability for Each Phase of Life
- Phase 1: Pre-Life
- Phase 2: Early Life
- Phase 3: Useful Life
- Phase 4: Wear Out
- Summary
- Additional Resources
Definition of Serviceability
Serviceability is the measure of and the set of the features that support the ease and speed of which corrective maintenance and preventive maintenance can be conducted on a system.
Corrective Maintenance (CM) includes all the actions taken to repair a failed system and get it back into an operating or available state. The failure can be unexpected or expected, but it is usually an unplanned outage. Mean Time To Repair (MTTR), the measure used to quantify the time required to perform CM, is also used in determining a system’s availability.
Preventive Maintenance (PM) includes all the actions taken to replace, service, upgrade, or patch a system to retain its operational or available state and prevent system failures. Mean Preventive Maintenance Time (MPMT), a measure commonly used to quantify the time required to perform PM, is also used in determining a system’s availability.
Serviceability for Each Phase of Life
Consider the bathtub curve in Figure 1. This curve, named for its shape, depicts the failure rate over time of a system or a product. A product’s life can be divided into four phases: Pre-Life, Early Life, Useful Life, and Wear Out. Each phase requires making different considerations to help avoid a failure at a critical or unexpected time because each phase is dominated by different concerns and failure mechanisms. Figure 1 includes some of these failure mechanisms.
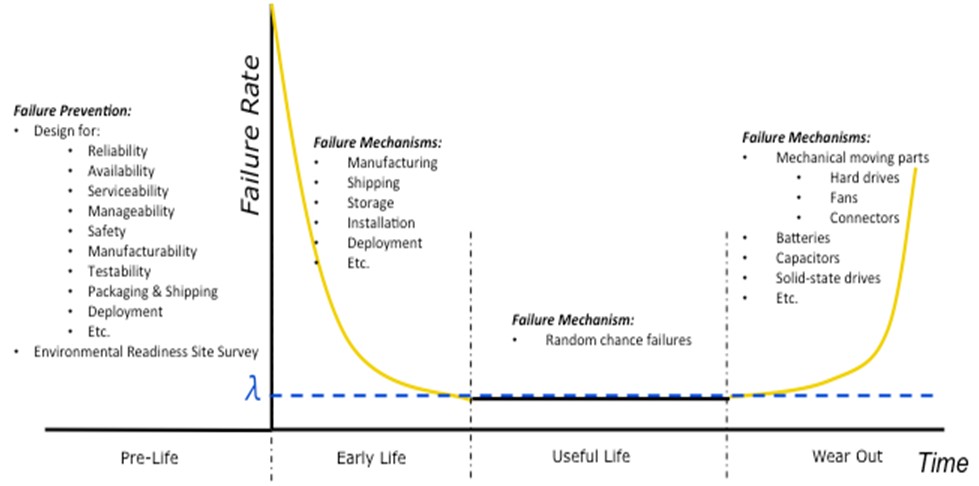
Figure 1. Bathtub Curve
Phase 1: Pre-Life
“An ounce of prevention is worth a pound of cure.”
–Benjamin Franklin
The focus during Pre-Life is planning and design. The design and accessibility of a system can have the greatest impact on its serviceability. But to design appropriately, you must understand the level of serviceability you need for a system.
Consider the following major factors when determining your serviceability requirements. These are only some of the considerations you need to make.
Cost of downtime: This is the most fundamental question that you must understand. This information should help drive how much you spend on the system or how much serviceability you can afford to have. The cost of downtime should include the cost of lost production/sales and the cost of employees/customers not able to do their work.
Preventive maintenance: The frequency that you need to conduct PM and the average time it takes to conduct PM, expressed as mean preventive maintenance time (MPMT), impact the availability of your system.
Sparing strategy: Keeping spare parts nearby to quickly replace failed components reduces the MTTR and, therefore, enhances serviceability. Spare parts do add to the cost of the overall solution, but waiting and ordering parts at the time of their failure results in the system being unavailable during the time it takes to deliver the parts. This reduced availability adds to the cost incurred by downtime, and can outweigh the cost of keeping spare parts in inventory and readily accessible.
Diagnostic tool requirements: Identifying the failed component(s) is crucial to making the repair. Thus it is desirable to quickly and accurately diagnose, or even predict, a failure. You can achieve this with effective manageability features. Good manageability can lead to faster and more efficient serviceability and, hence, higher availability. This is one way manageability, serviceability, and availability are related.
Learn more about manageability
Operation and service skills: Similar to the availability of spare parts, the availability of skilled personnel to diagnose and service the repair for CM contributes to availability. In addition, skilled personnel to conduct PM is another key to efficient serviceability and higher availability.
Environmental factors: The environment in which the system operates can have a great impact on its serviceability. For example, if the system is used in a crowded, remote, or hostile environment, it may be difficult or unsafe for personnel to access until the surrounding areas are free from these hazards. This can cause significant delays in MTTR. Conducting an Environmental Readiness Site Survey (ERSS) before system installation and deployment is an effective way to evaluate many of these factors, and it can help you understand how the environment can affect the required serviceability.
Phase 2: Early Life
Early Life is typically characterized by a failure rate higher than that seen in the Useful Life phase. These failures are commonly referred to as “infant mortality.” Such early failures can be accelerated and exposed by a process called Burn In, which is typically implemented prior to system deployment. The higher failure rate is often attributed to manufacturing flaws, bad components not found during manufacturing test, or damages during shipping, storage, or installation. The failure rate rapidly decreases as these issues are worked out.
Since failures are usually more prevalent during this phase of life, which leads to a higher number of CM events, you should plan for a greater than normal number of spares. You can take advantage of this phase to estimate the time it will take to conduct CM and PM on your system.
The time required to conduct CM is measured by the MTTR defined as:
[2]
The time required to conduct PM is measured by the MPMT defined as:
Phase 3: Useful Life
Useful Life is when the system’s Early Life issues have been worked out and it is trusted for normal operation. During this phase, many of the rigorous scientific and mathematic concepts of RASM engineering are applied. In Useful Life, failures are considered to be “random chance failures,” and they typically yield a constant failure rate. This is fortunate because a constant failure rate simplifies the mathematics associated with predicting failures.
During Useful Life, you can calculate the MTBF with a constant failure rate, “λ,” as shown below:
If the failure rate, λ, or the MTBF is considered to be constant, then:
[3]
Mathematically, serviceability (S) is measured in terms of mean maintenance time (MMT) or as:
[4]
From a feature set point of view, the robustness of serviceability can be characterized by some key features like:
- Modular architectures: A modular architecture helps you compose a complete system with discrete interconnecting parts or subsystems. Examples include blade servers [5] and PXI test systems. In contrast with modular systems, integrated box systems limit scalability, upgrades, and serviceability. Modular architectures promote fault isolation to a contained and replaceable part or field-replaceable unit (FRU). This greatly reduces the MTTR and gets the system back to its missions faster. If the system has a modular architecture, it is much easier to replace only the module/component that has failed or looks like it will fail soon. This also lends itself to easier and faster diagnostics and isolation of a failed component when debugging the system.
- No PM requirements: This can virtually eliminate the MPMT for your system. For example, sealed bearings in an automobile eliminate the cost of the PM time related to them and they last a long time. In fact, most last longer than many other parts of the car. For this reason, most of the time, you do not need to replace the bearings until they fail, so no PM is required for bearings. Integrated circuits (ICs) frequently fall into the no PM requirements category with some exceptions for analog circuits that require regular calibration. Calibration is considered PM because the system does not operate as expected if it is taking incorrect measurements. But today, many systems have no fans or filters that need to be cleaned or analog components that need to be calibrated, so they for all practical purposes do not need PM.
- System health monitoring and failure alarm systems (sometimes called watchdog systems or system prognostics tools): The faster you can know about a system failure the faster you can address it, thus lowering the MTTR of your system. Health monitoring can also save you money by converting an unplanned outage to a planned outage (from a CM event to a PM event) because you may be able to see a problem coming before it actually causes a system failure and further damage. Thus, you can choose a more convenient time to take the system off line and replace the questionable component before it fails. The development of system prognostics and Big Analog Data™
solutions continues to improve the abilities of computer-based software systems in the data acquisition industry to predict system failures before they happen. This science can also save money by minimizing the frequency of PM. Most PM programs service or replace system components on a regularly scheduled periodic basis with the assumption that the old components are wearing out and are less reliable than the new ones being installed, thus avoiding an unwanted and unplanned failure. This may not always be true or the most efficient approach. Have you ever heard the saying, “If it ain’t broke, don’t fix it.”? A component that has been used for a while may not be less reliable than a new replacement that may be affected by Early life (or infant mortality) failures. So if you can use the component as long as possible and replace it only just before it is about to fail, you can save money on unnecessary spares and unnecessary PM. You can avoid any unnecessary risks of failure due to component Early Life issues and lower your system’s MPMT.
- System self-test and diagnostics capabilities: The faster you can find the failed component in a system, the faster you can repair it and restore the system to its original working state. This lowers your system’s MTTR.
- System replication and software distribution: If you have a software failure or if the software gets corrupted, the faster you can restore the software, the lower your system MTTR. If you need to install a patch to fix an issue or upgrade the software, the faster you can do so, the lower your system MPMT.
- Toolless: You do not need tools to service your system (replace modules/components). This saves time because you don’t need to look for any special tools. It can also save you money because you don’t need to own any special tools.
- Redundancy: Redundancy usually has the greatest positive impact on the reliability and availability of the system. Since a redundant component can immediately replace a failed component, the MTTR to correct this failure is effectively zero. You may not need the entire system to be redundant, but rather only the most critical components or the components that are the most likely to fail. For example, you may require redundant power supplies and fans, but the rest of the system has a very low failure rate (or a very high MTBF), so you don’t need to duplicate those components.
- Hot-swappable redundant components: The benefit of hot-swappable components is that you are not required to take the system down or off line to repair/replace a failed component or to conduct PM on the redundant components. Thus, you may “never” have a system outage, making the availability of your system virtually equal to 100 percent!
- Software rejuvenation: Since a common cause of failure in a computing or test system is software faults, you should consider the RASM implications of software. Many times a system fails because of software as the system’s resources exhaust, and a resultant hang or crash occurs. To service this fault, you can apply techniques such as software rejuvenation [6], as responsive CM or as PM, to reset the system before the software’s progressive degradation reaches the point of failure.
These features also help improve the availability and reliability of your system by lowering MTTR and MPMT or by avoiding an unscheduled system outage.
Phase 4: Wear Out
The Wear Out phase begins when the system’s failure rate starts to rise above the “norm” seen in the Useful Life phase. This increasing failure rate is due primarily to expected part wear out. Usually mechanical moving parts such as fans, hard drives, switches, relays, and frequently used connectors are the first to fail. However, electrical components such as batteries, capacitors, and solid-state drives can be the first to fail as well. Most ICs and electronic components last about 20 years [7] under normal use within their specifications.
During the Wear Out phase, a system’s reliability is compromised and difficult to predict since it no longer exhibits a constant failure rate (or MTBF). Therefore, rigorous PM and replacement plans are advised. High serviceability features and practices can significantly lower the cost and downtime associated with replacing and upgrading systems during their Wear Out phase.
Summary
- Planning and design in Pre-Life is an opportunity to focus on serviceability issues such as ERSS, PM, CM, sparing, and replacement strategies.
- The design and accessibility of a system have the greatest impact on its serviceability.
- Understanding the financial and resource costs of downtime is critical.
- An ERSS in Pre-Life helps define serviceability levels and their barriers.
- Early Life focuses on testing and can be used to estimate your MTTR and MPMT.
- Serviceability improves the reliability and availability of the system during Useful Life.
Additional Resources
View the entire RASM white paper series
[1] “Design and Evaluation,” 3rd ed., by Daniel P. Siewiorek and Robert S. Swarz, Reliable Computer Systems (A K Peters/CRC Press, 1998).
[2] “The Certified Reliability Engineer Handbook,” 2nd ed., by Donald W. Benbow and Hugh W. Broome, ASQ Quality Press, Milwaukee Wisconsin, 2013, ISBN 978-0-87389-837-9, Chapter 13, page 227.
[3] “Reliability Theory and Practice,” by Igor Bazovsky, Prentice-Hall, Inc., 1961, Library of Congress Catalog Card Number: 61-15632, Chapter 5, page 33.
[4] “Practical Reliability Engineering” Fifth Edition, by Patrick D. O’Conner and Andre Kleyner, Wiley, ISBN 978-0-470-97981-5, Chapter 16, page 410.
[5] Blade Server, http://en.wikipedia.org/wiki/Blade_server.
[6] Software Aging, http://en.wikipedia.org/wiki/Software_aging.
[7] “Telcordia Technologies Special Report, SR-332”, Issue 1, May 2001, Section 2.4, pages 2–3.