Search and Replace Pattern
- Updated2023-02-17
- 7 minute(s) read
Search and Replace Pattern
Searches for a pattern in the input string and replaces either the first match or every match with a substring you specify.
This node performs more quickly than Search and Replace Regular Expression but gives you fewer options for matching strings. For example, Search and Replace Pattern does not support the parenthesis or vertical bar (|) characters.
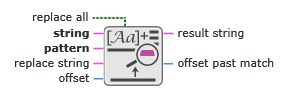
Inputs/Outputs

replace all
Boolean value that determines whether to replace all substrings that match the pattern you specify or just the first.
| True | The node replaces all matching substrings. |
| False | The node replaces the first matching substring. |
Default value: False

string
String on which the node operates.
pattern
The pattern you want to search for and replace. This input is limited to the following regular expression characters: . (period), *, +, ?, [], ^, $, \, \b, \f, \n, \s, \r, \t, and \xx. Furthermore, this input does not support character grouping, alternate pattern matching, backreferences, or non-greedy quantification.
Definitions of Special Characters
| Special Character | Description | Examples |
|---|---|---|
| . (period) | Matches any single character except a newline character. Within square brackets, . is literal. |
Input String: Welcome to LabVIEW. Regular Expression: t.... Match: to La If you use [z.] as the regular expression, the period is literal and matches either . or z. In this example, [z.] returns . as the match. |
| * | Marks the single preceding character or character class as one that can appear zero or more times in the input. Because an asterisk can mark a pattern as one that appears zero times, regular expressions that include an asterisk can return an empty string if the whole pattern is marked with an asterisk. This quantifier applies to as many characters as possible. |
Input String: Hello LabVIEW! Regular Expression: el* Match: ell Expressions such as w* or (welcome)* match an empty string if the node finds no other matches. |
| + | Marks the single preceding character or character class as one that can appear one or more times in the input. This quantifier applies to as many characters as possible. |
Input String: Hello LabVIEW! Regular Expression: el+ Match: ell |
| ? | Marks the single preceding character or character class as one that can appear zero or one time in the input. This quantifier applies to as many characters as possible. |
Input String: Hello LabVIEW! Regular Expression: el? Match: el |
| [] | Creates a character class, which allows you to match any one of a set of characters that you specify. For example,
[abc] matches
a,
b, or
c. This node interprets special characters inside square brackets literally, with the following exceptions:
|
Input String: version=14.0.1 Regular Expression: [0-9]+\.[0-9]+\.[0-9]+ Match: 14.0.1 The expression [0-9] matches any digit. The plus sign matches the previous character class, [0-9], one or more times but as many times as possible. The expression \. matches a literal . character. The plus sign matches the previous character class, [0-9], one or more times but matches as many times as possible. You can use this regular expression to match a three-part version number. |
| ^ | If ^ is the first character of the specified search string, it anchors the match to the offset in string. The match fails unless the specified search string matches that portion of string that begins with the character at offset. If ^ is not the first character in the regular expression, it is treated as a regular character. |
Input String: Hello LabVIEW! Regular Expression: ^[^ ]+ Match: Hello From the beginning of the input string, this regular expression matches as many characters – other than a space character – as possible. You can use this regular expression to isolate the first word, numeral, or other character combination of a string. |
| $ | If $ is the last character of the specified search string, it anchors the match to the last element of string. The match fails unless the specified search string matches up to and including the last character in the string. If $ is not the last character in the regular expression, it is treated as a regular character. |
Input String: Hello LabVIEW! Regular Expression: [^ ]+$ Match: LabVIEW! From the end of the input string, this regular expression matches as many characters – other than a space character – as possible. You can use this regular expression to isolate the last word, numeral, or other character combination of a string. |
| \ | Cancels the interpretation of any special character in this list. For example,
\? matches a question mark,
\. matches a period, and
\ matches a backslash. You also can use the following constructions for the following non-displayable characters:
|
Input String:
Welcome to the LabVIEW Help! Regular Expression: come\nto\tthe\sLabVIEW\sHelp\21 Match:
come to the LabVIEW Help! The expression come\n matches the literal letters followed by a newline character. The expression to\t matches the literal characters to followed by a tab. The two \s expressions match the spaces between the and LabVIEW and between LabVIEW and Help!. The expression \21 matches the exclamation point because 21 is the hexadecimal code for an exclamation point. |
replace string
String that replaces the search pattern in the input string.
Definitions of Special Characters
Use the following special characters in replace string.
| Special Character | Description | Example(s) |
|---|---|---|
| $n or ${n} |
Inserts a string you specify before or after the submatch you specify. Refer to the Specifying Backreferences in replace string section below for more information about using backreferences in replace string. Use ${n} if you have more than nine submatches in a regular expression and want to refer to a submatch after the ninth. $12 inserts only the first submatch because the function reads only the first digit that immediately follows $. However, ${12} inserts the twelfth submatch. |
Input String: Welcome LabVIEW! Pattern: (LabVIEW) Replace String: to $1! Result: Welcome to LabVIEW! |
|
Input String: Welcome to the LabVIEW Help! Pattern: We(l)(co(m)e)( )(to)( )t(he) (Lab)(VIE(W)) He(lp)(!) Replace String: $7${11}ful${12} Result: helpful! |
||
| $n | Cancels the interpretation of any special character you use in replace string. |
Input String: total=123 per day Pattern: (\d+)(per \w*)? Replace String: $$1$2 Result: total=$123 per day As in this example, use $ to insert the literal character $. Use \ to indicate a literal backslash. |
Specifying Backreferences in replace string
You can specify a backreference in replace string that refers to submatches in the input string. Use $1 to refer to the first submatch, $2 to refer to the second submatch, and so on. Consider the following example:
Input String: $value "TRUE"TRUE" *NULL
Pattern: (["*$])(\w+)\1\2\1
Replace String: $1$2value$1
Result: $value "TRUEvalue" *NULL

offset
Number of characters into the input string at which the node starts searching for a match.
Default value: 0

result string
String that this node produces after operating on the input string.

offset past match
Index in string of the first character after the last match. If the node does not find a match, offset past match is -1.
What Happens When There Is No Match?
If the node does not find pattern, result string returns an empty string and offset past match returns -1.
Reducing Performance Burden
Characters in UTF-8 can be multiple bytes so string nodes count the number of characters in a string instead of jumping to a point in memory. Since the length and offset parameters are in units of characters, avoid nesting this node with large strings because that can create exponential functions that carry a higher performance burden.