NI LabVIEW 編譯器:深入內部
綜覽
內容
這篇技術文章會從 1986 年的 LabVIEW 1.0 起簡介 LabVIEW 編譯器的發展沿革。此外,文章內容也會探討近期的編譯器創新技術,同時強調這些新功能之於 LabVIEW 架構和您的好處。
編譯 (Compilation) 相較於解譯 (Interpretation)
由於在典型的 G 開發過程中,並沒有明顯的編譯步驟,因此 LabVIEW 很意外地屬於編譯式語言。反之,只要按下「Run」按鈕執行之,即可變更自己的 VI。編譯 (Compilation) 即代表使用者所撰寫的 G 程式碼,均轉譯成為機器碼,並由主機電腦直接執行。而替代方式即為解譯 (Interpretation),是由其他軟體程式 (即所謂的解譯器) 所執行,而非電腦直接執行之。
但 LabVIEW 程式語言要編譯或解譯均可;事實上,第一個版本的 LabVIEW 就使用了解譯器。在最近的版本中,LabVIEW 用編譯器取代了解譯器,以提高 VI 的執行效能;而執行效能實為編譯/解譯器的常見差異。撰寫並維護解譯器均較為簡單,但執行效能較差。編譯器使用起來較複雜,但執行時間較快。LabVIEW 編譯器的主要優點之一,就是不需再額外修改 VI 即可看到其改良的部分。LabVIEW 2010 其中一個重點,就是將內部編譯器進行了最佳化,能夠縮短 VI 的執行時間。
LabVIEW 編譯器的歷史沿革
在進一步討論現代編譯器的內部結構之前,可以先重點了解 20 年多前的編譯器架構。稍後討論 LabVIEW 編譯器時,會再進一步說明這裡所提到的演算法 (如 Type propagation、Clumping,與 Inplaceness)。
LabVIEW 1.0 於 1986 年上市。如前所述,第一版的 LabVIEW 使用的是解譯器,而且只用於 Motorola 68000。當時的 LabVIEW 語言簡單許多,所以比較不需要用到編譯器 (當時是解譯器)。舉例來說,當時沒有多型,唯一的數值型別是延伸精度浮點數。LabVIEW 1.1 第一次推出 Inplaceness 演算法,又稱「Inplacer」。 這種演算法會識別能在執行期間重複使用的資料配置,因此不需要無謂的資料副本,自然能夠大幅提升執行效能。
LabVIEW 2.0 則以真正的編譯器取代解譯器。不過,這一版的 LabVIEW 仍然只適用於 Motorola 68000,而且可以產生原生機器碼。LabVIEW 2.0 則新增了 Type Propagation 演算法,可處理語法檢查 (Syntax checking) 與資料型別解析 (Type resolution) 作業。LabVIEW 2.0 的另一項創新,則是 Clumper。Clumping 演算法能找出 LabVIEW 中的平行機制,並將節點結合成「Clump」,用於平行執行。Type Propagation、Inplaceness 和 Clumping 演算法,全都是目前 LabVIEW 編譯器的重要元件,且都在不斷提升中。LabVIEW 2.5 的新編譯器架構,特別針對 Intel x86 與 Sparc 增加支援多重後端。LabVIEW 2.5 也採用了 Linker,能管理 VI 之間的相依性,利於在重新編譯時進行追蹤。
LabVIEW 3.1 新增了 PowerPC 與 HP PA-RISC 共 2 組後端,並另有常數堆疊 (Constant folding) 功能。LabVIEW 5.0 與 6.0 則改造了程式碼產生器,並且新增 GenAPI 通用介面,可用於多重後端。GenAPI 能交叉編譯,是 Real-Time 開發的重要功能。Real-time 系統的工程師通常都是在主機電腦上撰寫 VI,再將 VI 部署至 Real-Time 系統並進行編譯。另外也包含了功能有限的 Loop-Invariant Code Motion (LICM)。最後則是擴充了 LabVIEW 的多工執行系統,能支援多執行緒。
LabVIEW 8.0 是以 5.0 的 GenAPI 架構為基礎,另外新增 Register Allocation 演算法。相較於 GenAPI,Register 問世時間較早,且是針對各個節點寫死 (Hard-coded) 在所產生的程式碼中。另外也採用了功能有限的 Unreachable Code 和 Dead Code Elimination。LabVIEW 2009 提供 64 位元版的 LabVIEW 和 Dataflow Intermediate Representation (DFIR)。DFIR 馬上就用於建立更高階的 Loop-Invariant Code Motion、Constant Folding、Dead Code Elimination,以及 Unreachable Code Elimination。LabVIEW 2009 開始採用的新語言功能 (如 Parallel For Loop),就是以 DFIR 為建置基礎。
而在 LabVIEW 2010 中,DFIR 另提供最佳化的新編譯器,如 Algebraic Reassociation、Common Subexpression Elimination、Loop Unrolling,以及 subVI Inlining。這個版本也在 LabVIEW 編譯鏈中新增了 Low-Level Virtual Machine (LLVM)。LLVM 是業界廣泛應用的 Open-Source 編譯器架構。LLVM 也新增了最佳化功能,如 Instruction Scheduling、Loop Unswitching、Instruction Combining、Conditional Propagation,以及更完整的 Register Allocator。
現代的編譯流程
在粗略了解 LabVIEW 編譯器的演變之後,接下來談談最新版 LabVIEW 的編譯流程。首先,我們先進一步解說不同的編譯步驟,再詳細審視各個部分。
編譯 VI 的第一步,就是 Type Propagation 演算法。這個複雜的步驟負責區分終端 (Terminal) 的類型,並且能偵測語法錯誤。透過 Type Propagation 演算法就能找出 G 程式設計語言中的語法錯誤。若演算法判定 VI 有效,就會繼續編譯作業。
在 Type Propagation 之後,VI 會先從「程式方塊圖編輯器所使用的模型」轉換成「編譯器所使用的 DFIR」。轉換為 DFIR 之後,編譯器會在 DFIR 圖上執行數次轉換,將圖分解、最佳化,並準備用於產生程式碼。許多編譯器最佳化作業 (如 Inplacer 與 Clumper) 的用途都是在於傳輸/執行這個步驟。
簡化並最佳化 DFIR 圖之後,隨即編譯成 LLVM 中間語言。中間語言會執行一系列的 LLVM,進一步將其最佳化並降級為機器碼。
Type Propagation
如前所述,Type Propagation 演算法能區分資料型別,也能偵測程式設計錯誤。事實上,這種演算法還必須負責以下幾項功能:
- 解析能調整為型別的終端隱含型別
- 解析 subVI call 並判斷有效與否
- 計算接線方向
- 檢查 VI 中的週期
- 偵測並報告語法錯誤
只要使用者對 VI 進行任何變更,系統隨即就會執行演算法,從而確保 VI 的可用狀態;因此,目前無法確實將這個步驟歸納為「編譯」作業。不過,這個演算法是 LabVIEW 編譯鏈的其中一個步驟,並且能清楚對應於傳統編譯器的詞法分析 (Lexical Analysis)、剖析 (Parsing) 或語意分析 (Semantic Analysis) 步驟。
若要簡單舉例說明能依據型別調整的終端,那就是 LabVIEW 中的 Add Primitive。2 個整數相加的結果會是整數,但兩個浮點數相加的結果,則會是一個浮點數。如陣列與叢集的複合資料型別,也屬於類似的型態。其他語言架構 (如 Shift Register) 的資料型別規則更加錯綜複雜。在 Add Primitive 的條件下,將依輸入型態決定輸出型態,且此型態是藉由程式圖「傳播 (Propagate)」出來的,因此將其命名為演算法。
透過這個 Add Primitive 範例,我們就能知道 Type Propagation 演算法也必須負責語法檢查。假設使用者將 1 個整數與 1 組字串接至 Add Primitive,會發生什麼事呢?在此情況下,新增這 2 個數值並不合理,所以 Type Propagation 演算法會回報錯誤,並將 VI 標記為「Bad」,接著中斷執行箭頭。
何謂中介表示法?為何要採用這種表示法?
Type Propagation 判斷 VI 有效之後,就會繼續編譯作業,而 VI 也會被轉譯成 DFIR。在說明 DFIR 之前,應先初步了解中間語言 (Intermediate Representation,IR)。
IR 代表使用者的程式,按不同階段的編譯進度處理。IR 的概念在目前的編譯器說明文章中相當普遍,且可應用於任何程式設計語言。
接下來舉例說明。現在有許多種常見的 IR。最常見的 IR 就是 Abstract Syntax Trees (AST) 和 Three-address Code。
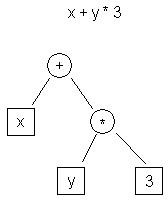 | t0 <- y t1 <- 3 t2 <- t0 * t1 t3 <- x t4 <- t3 + t2 |
| 圖 1.AST IR 範例 | 表 1.Three-Address Code IR 範例 |
圖 1 是以 AST 呈現「x + y * 3」的表示法;表 1 則是三位址碼 (Three-Address Code)。
這 2 種表示法有一個顯著差異,就是 AST 屬於較高階的表示法。相較於系統表示法 (機器碼),這種表示法更接近程式的原始表示法 (C)。相對而言,Three-Address Code 則屬於初階表示法,更類似於組合 (Assembly)。
初階和高階表示法各有其優點。舉例來說,若要進行諸如相依性分析之類的分析作業,以 AST 這樣的高階表示法可能會比使用 Three-Address Code 更容易。但如 Register Allocation 或 Instruction Scheduling 之類的其他最佳化作業,通常會以 Three-Address Code 這類初階表示法進行。
不同的 IR 各有其優缺點,因此,許多編譯器 (包括 LabVIEW 在內) 均使用多重 IR。在 LabVIEW 中,DFIR 是高階 IR;LLVM IR 則屬於初階 IR。
DFIR
LabVIEW 的高階表示法是 DFIR,除了屬於階層 (Hierarchical) 與圖形化架構之外,還可自行組合 G 程式碼。DFIR 與 G 類似,均由不同的節點所構成,且各個節點均包含端點。這些端點另可與其他端點連線。某些節點 (如迴圈) 也包含程式方塊圖,且這些程式方塊圖可能也包含其他節點。
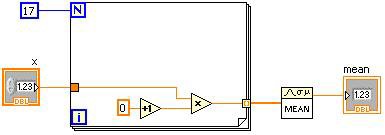
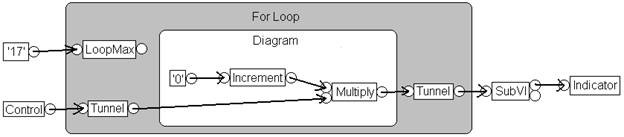
圖 2.LabVIEW G 程式碼與對等的 DFIR 程式圖
圖 2 顯示簡易 VI 與其初始的 DFIR 表示法。若先行建立 VI 的 DFIR 圖,則該圖即由 G 程式碼直接轉譯而來,且 DFIR 圖中的節點往往可逐一對應 G 程式碼中的節點。在編譯過程中,即可能移除或拆解 DFIR 節點,亦可能拒絕新的 DFIR 節點。DFIR 的主要優點之一,就是保留了 G 程式碼中的特性 (如既有的平行機制)。相對來說,Three-Address Code 的平行機制較難以察覺。
DFIR 主要為 LabVIEW 編譯器提供 2 大優點。第一,DFIR 可從 VI 的編譯器表示法中切割出編輯器 (Editor)。第二,DFIR 可做為編譯器的通用集線器,具備多組前端與後端。接著進一步說明這 2 項優點。
DFIR Graph 可從編譯器表示法中切割出編輯器 (Editor)。
在導入 DFIR 之前,LabVIEW 的 VI 只具備單一表示法,編輯器與編譯器必須共用這個表示法。因此,在編譯期間,編譯器無法修改表示法;也難以最佳化編譯器。

圖 3.DFIR 的架構可讓編譯器最佳化程式碼
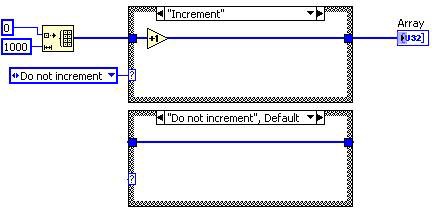
圖 3 顯示 VI 早期的 DFIR 圖。這個圖顯示最佳化數個轉換作業之後的後期編譯流程。看得出來,這個圖與先前的圖例有著極大差異。例如:
- 分解轉換作業移除了 Control、Indicator 與 SubVI 節點,並以 UIAccessor、UIUpdater、FunctionResolver 和 FunctionCall 的新節點取代。
- Loop-Invariant Code Motion 已將 Increment 與 Multiply 節點移出迴圈之外。
- Clumper 將 YieldIfNeeded 節點導入 For Loop 中,可讓「執行中的執行緒」與「其他競爭作業項目」共用執行作業。
稍後會進一步說明轉換 (Transform) 作業。
DFIR IR 可以是多重編譯器前/後端的通用集線器
LabVIEW 能搭配多款截然不同的系統,如 x86 桌上型電腦搭配 Xilinx FPGA。同樣地,LabVIEW 也具備多組運算模型。除了 G 的圖形化程式設計之外,也透過 MathScript 提供文字架構的數學。結果就是會產生前/後端集合,其中所有前/後端都必須搭配 LabVIEW 編譯器。若將 DFIR 做為「前端生產/後端消耗」的通用 IR,則可協助重複使用不同的整合作業。舉例來說,若於 DFIR 圖上建立常數堆疊 (Constant folding) 的最佳化作業,則撰寫 1 次就能套用於桌上型、Real-Time、FPGA,以及嵌入式系統。
DFIR 分解
一旦處於 DFIR 中,VI 就會先執行一系列的分解轉換。分解轉換專用於減少 DFIR 圖或將 DFIR 圖標準化。舉例來說,未接線的 Output Tunnel Decomposition,將於 Case 與 Event Structure 上尋找未接線的 Output Tunnel,並將之設定為「Use Default If Unwired」。 針對這些未接線的終端,轉換作業將丟出「具備預設值的常數」並將之接至終端,可於 DFIR 圖中清楚呈現「Use Default If Unwired」的行為。之後,後續的編譯器流程就能同等對待所有終端,並假設終端均已完成輸入接線。在此情況下,程式語言的「Use Default If Unwired」功能,會將表示法降級為更基礎的狀態,而遭「Compiled away」。
這個概念也適用於更複雜的程式語言功能。舉例來說,分解轉換能將 While Loop 上的 Feedback Node 降轉為 Shift Register。另外可搭配某些附加邏輯,建置 Parallel For Loop 做為數個後續 For Loop;並針對後續迴圈,將輸入切割為可平行化的片段,另依需要再重組這些片段。
LabVIEW 2010 有一項新功能,就是 subVI 行內展開 (Inlining),這項功能也屬於 DFIR 的分解功能。在這個編譯階段,若 subVI 的 DFIR 圖標記為「Inline」,則將直接導入至呼叫端的 DFIR 圖中。除了能避免 subVI Call 超出負載之外,也能於單一 DFIR 圖中整合呼叫端 (Caller) 和被呼叫端 (Callee)。舉例來說,我們設定這個簡易 VI 會在 vi.lib 呼叫 TrimWhitespace.vi。
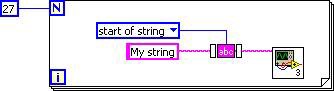
圖 4.DFIR 最佳化的簡易 VI 範例
而 vi.lib 中所定義的 TrimWhitespace.vi 是這樣:
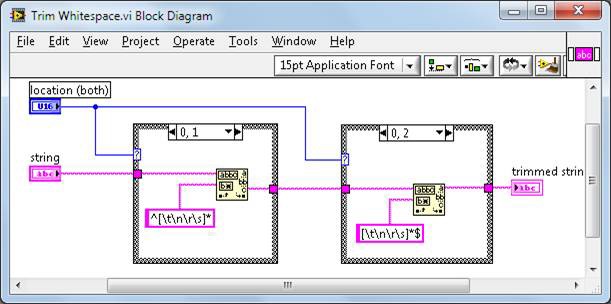
圖 5.TrimWhitespace.vi 程式方塊圖
subVI 已於呼叫端中展開,而此 DFIR 圖等同於以下所示的 G 程式碼。
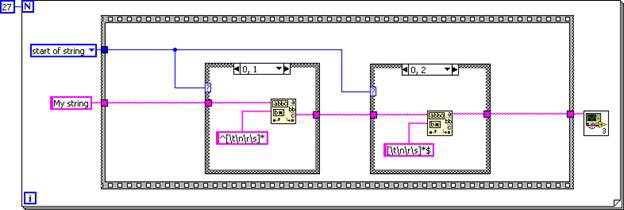
圖 6.G 程式碼等於 Inlined TrimWhitespace.vi 的 DFIR 圖
由於 subVI 的程式圖已在呼叫端程式圖中展開,Unreachable Code Elimination 和 Dead Code Elimination 即可簡化程式碼。第一個 Case Structure 絕對會執行;但第二個 Case Structure 絕不會執行。
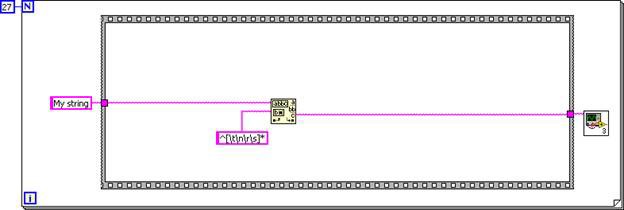
圖 7.由於輸入邏輯為常數,因此可以移除 Case Structures
同樣地,Loop-Invariant Code Motion 會將 Match Pattern Primitive 移出迴圈之外。最後的 DFIR 圖等於下列 G 程式碼。
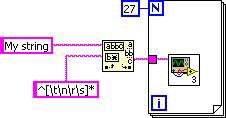
圖 8.G 程式碼等於最後的 DFIR 圖
LabVIEW 2010 預設會將 TrimWhitespace.vi 全數標記為 Inline,因此,這個 VI 的所有用戶端一律自動享有受惠於此。
DFIR 最佳化
完整分解 DFIR 圖之後,DFIR 最佳化程序隨即開始。稍後在 LLVM 編譯期間,還會執行更多最佳化作業。本節只探討其中幾項最佳化作業。這些轉換作業均屬於常見的編譯器最佳化作業,因此可找到特定最佳化的相關資訊。
Unreachable Code Elimination
只要是無法執行的程式碼,均歸類於「Unreachable」。即便移除「Unreachable Code」,也無法直接提升執行速度。但因為一旦移除 Unreachable Code 之後,後續的 Compile Passes 就不需再次運算並進行處理,所以能縮小整體程式碼並提高編譯次數。
Unreachable Code Elimination 之前

Unreachable Code Elimination 之後
圖 9.G 程式碼等同於 DFIR Unreachable Code Elimination Decomposition
在這種情況下不會執行 Case 架構的「Increment」程式圖,因此轉換作業將移除該 Case。由於 Case Structure 只剩下 1 組 Case,所以會以 Sequence Structure 取代。稍後的 Dead Code Elimination 會移除框架 (Frame) 與列舉常數 (Enumerated Constant)。
Loop-Invariant Code Motion (LICM)
Loop-Invariant Code Motion (LICM) 可針對 Loop Body 內部,找出「可安全移出迴圈」的程式碼。由於不需執行已移除的程式碼,因此可提高執行速度。
Loop Invariant Code Motion 轉換作業之前 | Loop Invariant Code Motion 轉換作業之後 |
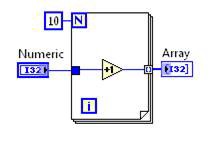
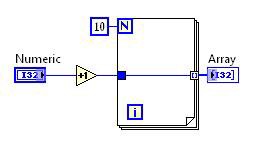
圖 10.G 程式碼等同於 DFIR Loop-Invariant Code Motion Decomposition
在此情況下的 Increment Operation 將移出迴圈之外。但由於仍保留了 Loop Body,因此能建立陣列;而且不需要在重複計算各次週期。
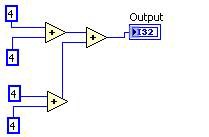
Common Subexpression Elimination
Common subexpression elimination 可找出重複的計算作業、執行單次計算,再重複使用該筆結果。
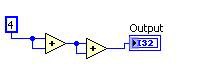
之前 之後
圖 11.G 程式碼等同於 DFIR Common Subexpression Elimination Decomposition
Constant Folding
Constant Folding 可找出執行期間,程式方塊圖仍保持一致的部分。
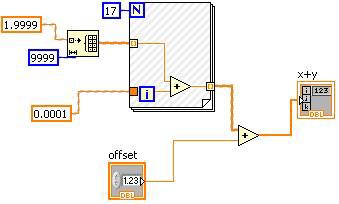
圖 12.LabVIEW 程式圖可以呈現 Constant Folding
圖 12 中的「#」標記就代表程式方塊圖的 Constant Folding 部分。在此條件下,「offset」控制項不能是 Constant Folded,但 Plus Primitive 的其他運算元 (包括 For Loop 在內) 均屬於常數值。
Loop Unrolling
Loop unrolling 可在已經產生的程式碼中多次重複單一 Loop Body,以利減輕迴圈的作業負擔,並以相同係數減少總循環次數。如此雖然能降低迴圈負擔,並進一步最佳化系統效能,但可能會讓程式碼變得更複雜冗長。
Dead Code Elimination
Dead code 就是不必要的程式碼。移除從未使用過的 Dead code 就能加快執行速度。
若使用者並未直接撰寫轉換作業,卻又透過這些轉換作業運作 DFIR 圖,就會產生 Dead Code。請看下例範例。Unreachable Code Elimination 會決定可移除的 Case Structure。如此將「產生」無效程式碼,並由 Dead code elimination 轉換作業將其移除。
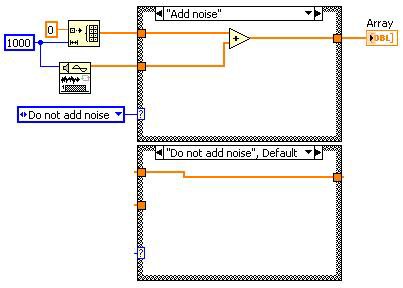
之前
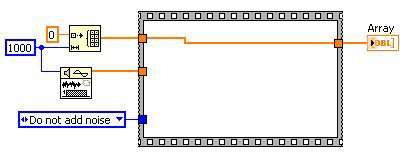
Unreachable Code Elimination 之後
Dead Code Elimination 之後
圖 13.Dead Code Elimination 可以減少編譯器必須處理的程式碼數量
此處所提到的轉換作業都有類似的相互關係。只要執行 1 項轉換作業,就可能必須再執行另 1 項轉換。
DFIR 後端轉換
在分解/最佳化 DFIR 之後,隨即執行數次的後端轉換。這些轉換作業會預先評估 DFIR 圖,進一步將 DFIR 降級為 LLVM IR。
Clumper
Clumping 演算法能分析 DFIR 中的平行機制,並將節點結合成「Clump」再進行平行執行。這個演算法可以搭配 LabVIEW 的 Run-time 執行系統,也就是使用多執行緒的協同多工作業。由 Clumper 所產生的 Clump,均已排程為執行系統中的獨立作業。在 Clump 中的節點,會按照序列化的順序執行。由於已預先決定 Clump 的執行順序,因此可讓 Inplacer 共用資料分配並大幅提升效能。Clumper 亦必須負責將 Yield 插入至冗長的作業 (如迴圈或 I/O) 中,所以這些 Clump 可與其他 Clump 協同進行多工。
Inplacer
當要再使用資料分配,或必須取得副本時,Inplacer 會分析 DFIR 圖並進行識別。LabVIEW 中的接線必須是簡易的 32 位元 Scalar,或是 32 MB 的陣列。在如 LabVIEW 的資料流程式語言中,必須能儘量重複使用資料。
請看下列範例 (注意,這裡為了達到最佳效能並盡可能減少使用記憶體,因此停用了 VI 除錯功能)。
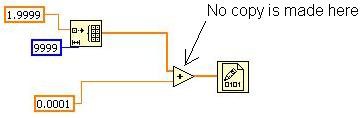
圖 14.Inplaceness 演算法簡易範例
這個 VI 會初始化 1 組陣列、將一些 Scalar 值新增至每個元素中,再將之寫入二進制檔案。陣列又應該有幾份副本呢?LabVIEW 必須重新建立陣列,且新增的作業只能在該陣列上原地運作。因此,陣列只需要 1 組副本即可,並不需要各組接線均分配 1 組副本。若陣列屬於大型陣列,則不論是記憶體使用量或執行時間而言,都會造成極大差異。在這個 VI 中,Inplacer 會找機會在「正確地點」操作,另設定額外節點以利用這項作業。
只要點選 Tools» Profile 找到「Show Buffer Allocations」,就能針對自己撰寫的 VI 檢視此行為。這項工具並不會在 Add Primitive 顯示分配情形,但會註明尚未複製資料,還有在正確位置所發生的額外作業。
由於沒有其他節點需要原始陣列,因此可能會發生上述情形。若按照圖 15 所示的方法修改 VI,則 Inplacer 會接著複製 Add Primitive。因為第二組 Write to Binary File Primitive 需要原始陣列,且必須在第一組 Write to Binary File Primitive 之後執行,才會造成圖 15 的情形。在修改之後,Show Buffer Allocations 工具會顯示 Add Primitive 上的分配。
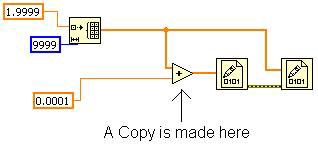
圖 15.若將原始陣列接線進行分支,將於記憶體中製作副本
分配器
在 Inplacer 找出可共用記憶體位置的節點之後,接著 Allocator 將建立由 VI 執行的分配作業。必須掃過各個節點與終端,才能建立這項分配作業只要是屬於 In-place 的終端,均將再使用分配作業,而不會建立新的分配作業。
程式碼產生器
程式碼產生器屬於編譯器的元件之一,可將 DFIR 圖轉換為系統處理器所能執行的機器指令。LabVIEW 會依照資料流的順序,於 DFIR 圖中操作各組節點。每個節點都會呼叫一個名為 GenAPI 的介面,這個介面的作用是將 DFIR 圖轉換為後續的中介語言 (Intermediate language,IL) 形式,用於描述該節點的功能。IL 也能透過平台以外的方式描述節點的初階行為。IL 中另有不同的指令能建置運算作業、讀取/寫入記憶體、執行比較與條件分支 (Conditional branch),以及更多功能。IL 指令亦可於記憶體上操作,或根據虛擬暫存區 (且將儲存中介值) 中的數值操作。IL 指令範例則包含 GenAdd、GenMul、GenIf、GenLabel,與 GenMove。
在 LabVIEW 2009 之前的版本,這個 IL 型別均針對系統平台直接轉換為機器指令 (如 80X86 與 PowerPC)。LabVIEW 則使用簡易的 One-pass Register Allocator,將虛擬暫存區對應至實體機器暫存區。且各組 IL 指令均將發出特定機器指令的 Hard-coded Set,將其建置於各個所支援的系統平台上。雖然這項作業的速度極快,但仍屬相對初階的程式碼,且不適用於最佳化作業。而高階的 DFIR 可獨立於平台之外,但只限用於能支援的程式碼轉換作業。為了讓目前的編譯器能完整支援程式碼最佳化功能,LabVIEW 新導入所謂的 LLVM 開放技術。
LLVM
Low-Level Virtual Machine (LLVM) 是高效能的開放式編譯器架構,原本是針對美國伊利諾大學 (University of Illinois) 的研究專案所設計。由於 LLVM 極富彈性、API 清楚明確,且不限制授權,目前已廣泛運用於學術與產業中。
LabVIEW 2010 重新設計了 LabVIEW 的程式碼產生器,透過 LLVM 產生所需的機器程式碼。現有的 LabVIEW IL 呈現方式,只需重新撰寫約 80 組 IL 指令,不需耗時撰寫 LabVIEW 所支援的大量 DFIR 節點與 Primitive。
透過 VI 的 DFIR 圖建立 IL 程式碼串流之後,LabVIEW 會掃描每一組 IL 指令,並且建立對等的 LLVM 組裝式呈現方式。其中將引用不同的最佳化步驟,接著使用 LLVM Just-in-Time (JIT) 架構,於記憶體中建立可執行的機器指令。LLVM 的機器重新定址 (Relocation) 資訊,會轉換為 LabVIEW 的表示法。因此,若使用者將 VI 儲存在磁碟中,再將 VI 重新載入至不同的記憶體基本位址,就可以進行修改並在新位址上執行。
LabVIEW 也使用 LLVM 執行數項標準的編譯器最佳化:
- 指令結合
- 跳轉執行緒
- 純量替換聚集
- 條件傳播
- 尾呼叫消除
- 運算式重新連結
- 迴圈不變式程式碼移動
- 迴圈取消切換與索引分割
- 歸納變數簡化
- Loop Unrolling
- 全域數值編號
- 消除 Dead Store
- 積極消除無效程式碼
- 稀疏條件式常數傳播
礙於篇幅,本技術文章無法完整解釋上述所有作業。若要了解更多資訊,請參閱編譯器教科書與網路資料。
NI 內部測試基準顯示,LLVM 平均能提升約 20% 的 VI 執行時間。依 VI 所執行的運算性質不同,其效能提升幅度也有所差異。某些 VI 可能大幅提升效能,也有些 VI 的效能毫無變化。舉例來說,若使用高階分析函式庫的 VI,或是高度依賴以 C 語言建置的程式碼,其效能差異就不會太大。LabVIEW 2010 是採用 LLVM 的第一個版本,未來也會不斷創新並提升。
DFIR 與 LLVM 並行
使用者可能已經注意到,DFIR 已開始執行某些最佳化功能 (如 Loop-Invariant Cde Motion 與 Dead Code Elimination)。事實上,因為有些最佳化步驟,必須將程式碼轉換為「新最佳化作業所支援的形式」,所以某些最佳化步驟必須重複執行,或用於不同層級的編譯器,才能顯現出其優點。但以最基本概念來看,DFIR 屬於高階 IR,LLVM 屬於初階 IR。此 2 種 IR 可同時執行,進而最佳化「針對處理器架構所撰寫的 LabVIEW 程式碼」。