NI does not actively maintain this document.
This content provides support for older products and technology, so you may notice outdated links or obsolete information about operating systems or other relevant products.

閱讀本白皮書,了解當前多核心程式設計師所面臨的挑戰。具體而言,本文件廣泛探討各項能應用於軟體架構的多核心程式設計模式。
目前已有幾本書深入探討了程式設計模式,因此本文件將簡要介紹下列概念以及如何將其套用至 LabVIEW:
1.作業平行機制
2.資料平行機制
3.流程
4.結構網格
從軟體架構的角度,嘗試整合最適合用於解決應用程式問題的平行模式。選擇合適的模式之前,請先考慮應用程式的特性與硬體架構。
此外,文件內容會以前述各項模式 (一般 While 迴圈、反饋節點、移位暫存器、時序迴圈、平行迴圈) 為脈絡,重點探討各種 LabVIEW 架構。
LabVIEW 2014 Real-Time Module 在 Phar Lap ETS 目標系統支援最高 12 核心的 CPU。此前這個模組僅支援八個 CPU 核心,即便目標系統不只八個核心也一樣。
作業平行機制是最簡單的平行程式設計形式,能將應用程式分成各自獨立且可在不同處理器上執行的多個作業。 假設程式有兩個迴圈 (A 迴圈 和 b 迴圈),A 迴圈負責執行訊號處理常式,b 迴圈負責更新使用者介面。 這就是作業平行機制,亦即一個多執行緒應用程式可以在不同的執行緒中執行這兩個迴圈,從而充分利用多個 CPU。
在 LabVIEW 中,只要程式方塊圖含部分的平行程式碼就能實現作業平行機制。 LabVIEW 的優點是能讓使用者「看見」程式碼中的平行機制,而且很容易就能區分不同的作業,順利達成這種形式的平行機制。 此外,LabVIEW 會自動執行應用程式的多執行緒處理,使用者不必擔心執行緒管理或執行緒之間的同步化。
只要將大型陣列或矩陣分割為子集、執行作業並整合結果,即可將資料平行機制套用至大型資料集。
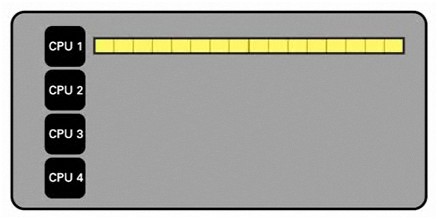
首先考慮連續執行,也就是一個 CPU 嘗試處理整個資料集。
圖 - 單一 CPU 處理
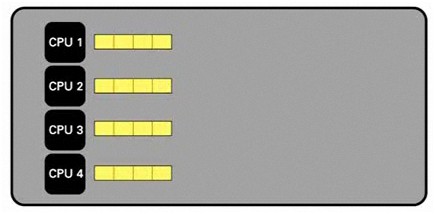
下一個範例則是將同一個資料集分成四個部分。使用者可以將這個資料集分散到可用的核心,從而大幅提升速度。
圖 - 多 CPU 處理
在控制系統之類的即時高效能運算 (HPC) 應用領域,平行執行大型矩陣向量乘法運算是相當普遍且有效率的策略。矩陣通常是固定的,可以提前分解矩陣。感測器收集的量測結果可以為每個迴圈提供向量。舉例來說,可以使用矩陣向量的結果控制致動器。
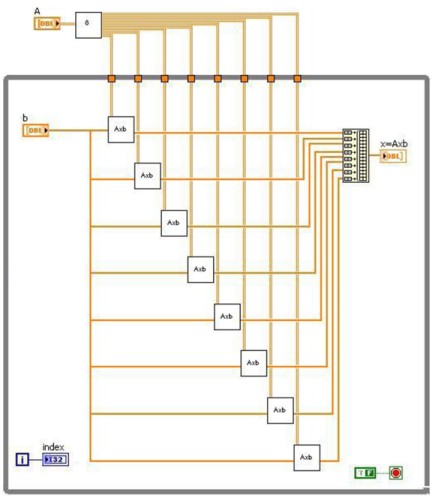
下列程式方塊圖顯示了分配到八個核心的矩陣向量乘法運算。
圖 - LabVIEW 中的矩陣向量乘法運算
程式方塊圖會從左至右執行,並且進行下列步驟:
1. 在 A 矩陣進入 While 迴圈之前將 A 矩陣分解
2. 將 A 矩陣的各個部分乘以 b 向量
3. 結合運算產生的向量,得出最終結果 x=Axb
流程就像裝配生產線。串流應用程式以及當使用者必須依序修改大量使用 CPU 的演算法,並且其中每個步驟均十分耗時的時候,可以考慮使用這個方法。
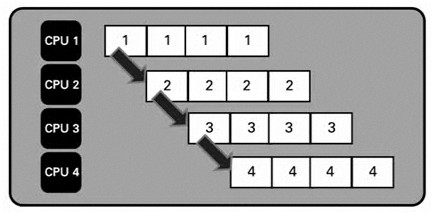
圖 - 演算法中依序執行的各個階段
就像裝配生產線一樣,每個階段只集中處理一個工作單元。每個結果依序傳送至下一個階段,直到進入最後階段為止。
若要將流程策略應用於將在多核心 CPU 執行的應用程式,可以將演算法分解成多個步驟,每個步驟都擁有大致相同的工作單元,並且都在獨立核心上分別執行。這個演算法可重複應用於多組資料或連續串流的資料。
圖 - 流程方法
關鍵在於將演算法分割為耗時相同的多個步驟,因為每次迭代所需的時間與整體流程中耗時最長的獨立步驟一樣長。舉例來說,如果步驟 2 需要 1 分鐘才能完成,而步驟 1、3、4 各需要 10 秒,要完成整個迭代就需要 1 分鐘。
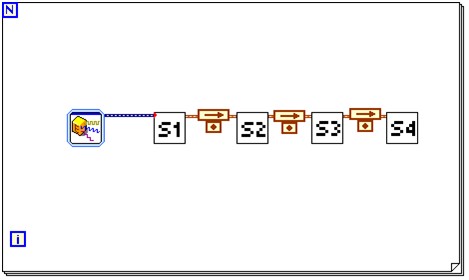
圖 4 中的 LabVIEW 程式方塊圖就是流程方法的範例。For 迴圈用黑色框線圈出,其中含 S1、S2、S3 與 S4 階段,分別代表演算法中必須依序執行的各個函式。 LabVIEW 是一種結構化的資料流程語言,因此,每個函式的輸出都會沿著線路傳送至下一個函式的輸入。
圖 - LabVIEW 中的流程方法
請注意,小點上方出現箭頭代表是反饋節點。反饋節點表示將函式分割成獨立的流程階段。相同程式碼的非流程版本看起來很相似,只是不會有反饋節點。常用這項技術的範例包括快速傅利葉轉換 (Fast Fourier Transform,FFT) 要求一次處理一個步驟的串流應用。
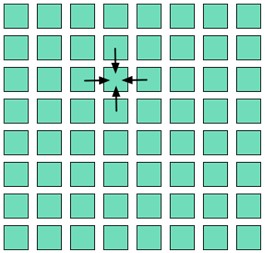
許多與實體模型相關的運算會使用結構網格模式。在此模式中,每次迭代都會計算 2D 或 ND 網格,而每個更新過的網格值都是其鄰近格線的函式,如圖 8 所示。
圖 - 結構網格方法
使用平行版本的結構網格,能將網格分割成子網格,並且獨立運算各個子網格。工作程序之間的通訊只能在鄰近子網格的寬度範圍內進行。平行效率是面積周長比的一項函式。
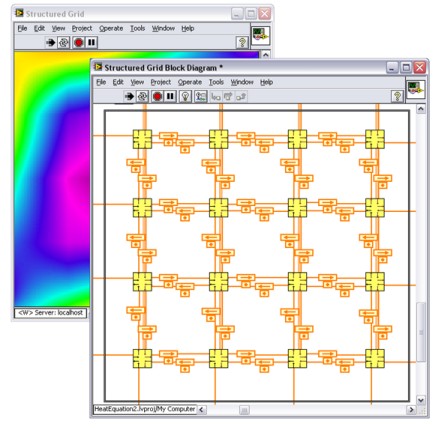
舉例來說,下圖所示的程式方塊圖能解邊界條件經常改變的熱方程式。
圖 - LabVIEW 中的結構網格方法
可以看見的 16 個圖示代表 16 項作業,這些作業能解特定網格大小的 Laplace 方程式,其中的 Laplace 方程式就是能解熱方程式的一種方式。16 項作業對應 16 個核心。 迴圈每完成一次迭代,這些核心就會交換邊界條件,處理程序則會建立一個通用的解決方案。反饋節點代表項目之間的資料交換,以出現在小點上方的箭頭表示。使用者也可以將這樣的程式方塊圖對應於 1、2、4、8 核心的電腦。電腦核心數量增加後,也可以採用類似的策略。
While 迴圈是一種基本架構,能與多種程式設計模式並用 (作業平行機制、資料平行機制、流程或結構網格)。 依據模式的不同,使用一般 While 迴圈有時就能因應需求,而在其他情況下,則可能需要用到特定類型的 While 迴圈 (例如時序迴圈)。
就上述流程方法而言,應採用移位暫存器或反饋節點 (在這種情況下,兩者的行為是一樣的)。
Parallel For 迴圈支援使用者以程式設計方式設定平行工作程序的數量,這些平行工作程序執行程式碼,達成隱含的平行機制 (亦即程式碼能總結複雜概念,並將不同的工作程序對應至不同的核心)。 針對每一個處理器核心建立一個工作程序,讓平行執行發揮最大的效能。
Parallel For 迴圈非常適合用於需要在迴圈中反覆執行且迭代之間不具相依性的密集運作。 不過,若有相依性存在,就不適合使用 Parallel For 迴圈,因為存在相依性表示演算法應依序執行。 在此情況下,可以運用流程之類的其他技術實現平行機制。
時序迴圈可以發揮 While 迴圈的作用,但多了一項特殊的特性,即能協助使用者根據多核心硬體的配置最佳化效能。舉例來說,時序迴圈內的任何程式碼一律會在單一執行緒中執行,這一點就不同於可能會用到多執行緒的 While 迴圈。這樣的做法看似不符合直覺操作,也或許會令人不解多核心系統何以會採用單執行緒。 就即時系統以及重視快取最佳化的用途而言,這個特性特別實用。 除了能在單一執行緒中執行之外,這個迴圈也能設定處理器親和性,也就是將該執行緒指派給某個特定 CPU (從而協助進行快取最佳化) 的機制。
請務必注意,在一般 While 迴圈中運作良好的平行模式 (例如資料平行機制與流程),無法與時序迴圈同時運作,原因在於單一執行緒無法做到平行機制。 反之,可使用多個時序迴圈來實作相關技術。舉例來說,若採用流程方法,可使用單一時序迴圈代表流程中的特定階段,並透過 FIFO 於迴圈之間傳輸資料。
佇列對於同步化多個迴圈之間的資料非常重要。 舉例來說,佇列可用於執行產生者/消耗者架構。 本文件並未具體提到產生者/消耗者架構,原因在於這個架構並非平行程式設計專用架構,而是比較偏向通用程式設計架構。 即便如此,這個架構在多核心 CPU 中仍然運作良好,可將 CPU 的使用率降到最低,迴圈與佇列的組合是其運作良好的原因。
請注意,佇列並非在迴圈之間共用資料的精確機制,如果即時是必要條件,可以改用 RT FIFO。
LabVIEW Real-Time 有一項特性,就是可以使用 CPU 集區 VI「預留」CPU,供特定執行緒集區使用。 這是另一種快取最佳化機制。
舉例來說,假設要在四核心系統上執行某應用程式,而這款應用程式會以最快的速度反覆處理資料。 假設資料集確實能夠裝入 CPU 快取,在快取中執行這類運作就非常理想。 事實上,在快取中執行運作的成效可能會高於嘗試平行處理程式碼並將四個 CPU 同時派上用場。 因此,開發人員可以選擇只預留兩個 CPU 給 OS 排程器,例如 CPU 0 和 2,而不是讓 OS 安排將四個 CPU (0 到 3) 全數用於平行作業。 (這裡提到的四核心處理器或許可以讓 CPU 0 和 1 共用一個大型快取、CPU 2 和 3 共用另一個大型快取) 透過預留 CPU 的方式,開發人員可以協助將資料確實保留在快取中,同時也確保運作過程能夠完全用到這兩個大型共用快取。
CPU 資訊 VI 提供執行 LabVIEW 應用程式的系統所特有的資訊。 如果有可能會將應用程式部署於多種不同的機器 (例如雙核心、四核心甚至是八核心機器),這項資訊會非常實用。
使用 CPU 資訊 VI,可以讓應用程式讀取諸如「# of logical processors」之類的參數,並且根據特定機器的結果,將結果饋送至 Parallel For 迴圈。
舉例來說,如果應用程式在雙核心機器上執行,邏輯處理器的數量 = 2,那麼最理想的 Parallel For 迴圈數量設定也會是 2。 這樣可以讓程式碼更容易按照基礎硬體進行調整。
追蹤功能是一種相當實用的多核心應用程式除錯方式,在桌上型系統或即時系統中皆可執行。 請見 Desktop Execution Trace Toolkit 與 Real-Time Trace Viewer 的產品說明書。在 LabVIEW 2013 及更早的 LabVIEW Real-Time Module 版本中,Real-Time Trace Viewer 封裝為獨立工具組 (Real-Time Execution Trace Toolkit)。
總而言之,有經驗的程式設計師應該考慮到能很好地對應至特定應用的程式設計模式。 本文件探討的模式包括作業平行機制、資料平行機制、流程,以及結構網格。
為充分運用本文所述的模式,LabVIEW 開發人員應整合不同的架構、VI 與除錯工具,確實發揮最佳效能。