使用NI LabVIEW优化多核处理器的自动化测试应用
概览
多核编程基础白皮书系列的组成部分

多核编程基础白皮书系列
LabVIEW面向自动化测试应用提供了简单易用的图形化编程环境。其特别之处在于,能够将代码动态分配到不同的CPU内核,从而提高多核处理器的执行速度。了解如何优化LabVIEW应用以发挥并行编程技术的优势。
内容
多线程编程的挑战
处理器技术的各种创新使得计算机CPU的时钟频率不断提高。然而,随着时钟频率接近其理论极限,处理器厂商将目光投向了多核处理器的开发。开发自动化测试应用的工程师借助这些新型多核处理器并通过并行编程技术实现最佳性能和最大吞吐量。加州大学伯克利分校电气与计算机工程教授Edward Lee博士描述了并行处理的优势。
“许多技术专家预测,摩尔定律最终将通过越来越多的并行计算机架构得到延续。如果我们希望继续在计算中获得性能提升,程序必须能够利用这种并行技术。”
此外,行业专家认识到,编写应用程序以利用多核处理器难度非常高。微软公司创始人比尔·盖茨解释道。
“要充分发挥并行处理器的强大功能,软件必须可以处理并发问题。但正如所有编写过多线程代码的开发人员所说,这是编程中最艰巨的任务之一。”
万幸的是,NI LabVIEW软件提供了一个理想的多核处理器编程环境,该环境具有可用于创建并行算法的直观API,从而为给定的应用动态分配多个线程。事实上,可优化多核处理器的自动化测试应用以实现最佳性能。
此外,PXI Express模块化仪器充分利用了PCI Express总线的高数据传输速率,从而进一步扩大了优势。多通道信号分析和内联处理(硬件在环)这两个具体应用充分发挥了多核处理器和PXI Express仪器的优势。本白皮书评估了各种并行编程技术,并描述了每种技术所能带来的性能优势。
实现并行测试算法
第一个从并行处理中获益的常见自动化测试应用是多通道信号分析。由于频率分析是一项处理器密集型操作,因此可通过并行运行测试代码来提高执行速度,从而将每个通道的信号处理分配给多个处理器内核。从程序员的角度来看,唯一要做的工作就是对测试算法进行微小的重构。
为了说明这一点,我们比较了两种用于多通道频率分析(快速傅里叶变换(FFT))的算法在高速数字化仪的两个通道上的执行时间。NI PXIe-5122 14位高速数字化仪使用两个通道以最大采样率(100MS/s)采集信号。首先,在LabVIEW中检查该操作的传统顺序编程模型。
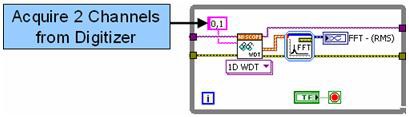
图1.LabVIEW代码顺序执行。
图1中,两个通道的频率分析在FFT Express VI中执行,其依次对每个通道进行分析。虽然上述算法仍然可在多核处理器中高效执行,但通过并行处理每个通道还可以提高算法性能。
如果对算法进行分析,会发现FFT的完成时间比高速数字化仪的采集时间要长得多。每次获取一个通道并且并行执行两个FFT,可大幅减少处理时间。图2显示使用并行方法的新LabVIEW结构框图。
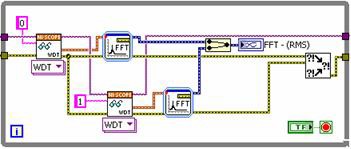
图2.LabVIEW代码并行执行。
每个通道都按顺序从数字化仪中获取。请注意,如果两次提取都来自不同的仪器,则可完全并行执行这些操作。但由于FFT为处理器密集型,因此仍可通过并行运行信号处理来提高性能。最终可减少总执行时间。图3显示了两种实现方式的执行时间。
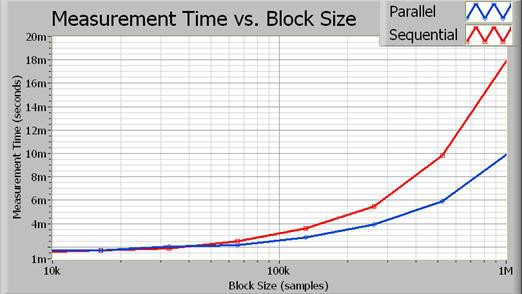
图3.随着块大小的增加,并行执行可节省的处理时间越来越明显。
事实上,对于较大的块大小,并行算法的性能提高了两倍。图4展示了性能增长的百分比与采集大小(以样本为单位)的关系。
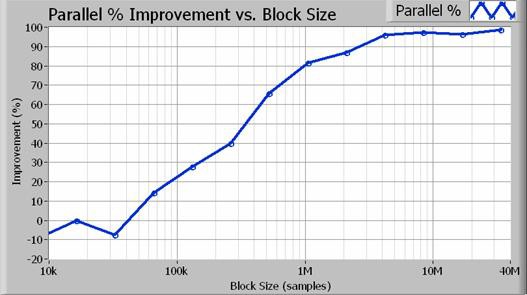
图4.对于大于100万个采样(100Hz分辨率带宽)的块大小,并行方法可使性能提高80%或更高。
由于使用LabVIEW动态分配每个线程,因此可以轻松在多核处理器上提高自动化测试应用的性能。事实上,无需创建特别的代码即可启用多线程。并行测试应用只需进行少量的编程调整即可从多核处理器中受益。
配置自定义并行测试算法
并行信号处理算法可帮助LabVIEW在多个内核之间分配处理器使用量。图5说明了CPU处理算法各个部分的顺序。
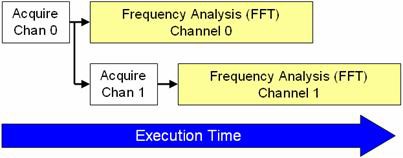
图5.LabVIEW可并行处理大部分采集的数据,从而节省了执行时间。
并行处理要求LabVIEW复制(或克隆)每个信号处理子程序。默认情况下,许多LabVIEW信号处理算法配置为“重入执行”。 这意味着LabVIEW会动态分配每个子程序的独立实例,包括单独的线程和内存空间。因此,必须将自定义子例程配置为以重入方式运行。在LabVIEW中通过一个简单的配置步骤即可完成此操作。如需设置该属性,请选择File(文件)>>VI Properties(VI属性),然后选择Execution(执行)类别。然后,选择Reentrant execution(重入执行)标志,如图6所示。
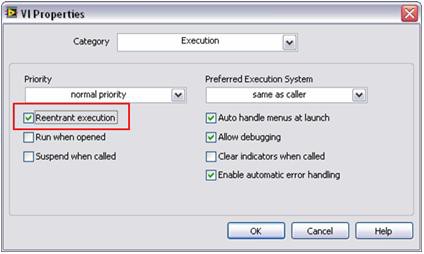
图6.通过这个简单步骤,就可以并行执行多个自定义子程序,与标准LabVIEW分析函数无异。
因此,可通过使用简单的编程技术在采用多核处理器的自动化测试应用中实现更高的性能。
优化硬件在环应用
第二个受益于并行信号处理技术的应用是使用多台仪器同时进行输入和输出。通常,这些应用被称为硬件在环(HIL)或在线处理应用。该情况下,可使用高速数字化仪或高速数字I/O模块来采集信号。在软件中执行数字信号处理算法。最后,由另一台模块化仪器生成结果。典型结构框图如图7所示。

图7.下图显示了典型硬件在环(HIL)应用的步骤。
典型HIL应用包括在线数字信号处理(如滤波和插值)、传感器仿真和自定义组件仿真。可使用多种技术来实现在线数字信号处理应用的最佳吞吐量。
一般可使用单循环结构和具有队列的流水线多循环结构这两种基本的编程结构。单循环结构易于实现,并且在小块大小的情况下具有较低的延迟。而多循环架构具有更高的吞吐量,因为它们可以充分利用多核处理器。
使用传统的单循环方法,依次放置高速数字化仪读取函数、信号处理算法和高速数字I/O写入函数。如图8的结构框图所示,每个子程序必须按顺序执行,具体取决于LabVIEW编程模型。
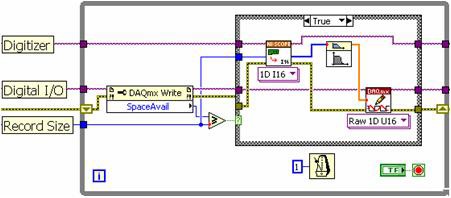
图8.使用LabVIEW单循环方法时,每个子程序必须依次执行。
单循环结构存在一些限制。由于每个阶段都是按顺序执行的,因此处理器在处理数据时无法执行仪器I/O。这种方法无法高效使用多核CPU,因为处理器一次只执行一个功能。单循环结构完全可以满足较低的采集速率要求,对于更高的数据吞吐量,必须使用多循环结构。
多循环架构使用队列结构在每个While循环之间传递数据。图9展示了使用队列结构在While循环之间进行编程的情况。
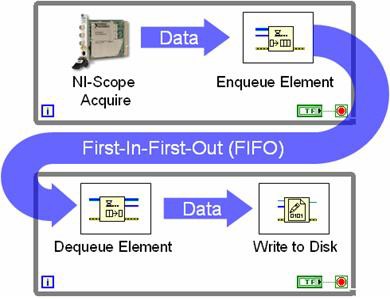
图9.使用队列的多循环结构可共享数据。
图9为典型的生产者―消费者循环结构。在本示例中,高速数字化仪在一个循环中采集数据,并在每次迭代期间将新数据集传递至FIFO。消费者循环仅监视队列状态,并在每个数据集可用时将其写入磁盘。使用队列的价值在于两个循环彼此独立执行。上例中,即使数据写入磁盘存在延迟,高速数字化仪仍将继续采集数据。额外的样本只是暂时存储在FIFO队列中。通常,生产者―消费者流水线方法可提供更高的数据吞吐量和更高效的处理器利用率。该优势在多核处理器中更为明显,因为LabVIEW可为每个内核动态分配处理器线程。
对于在线信号处理应用,可使用三个独立的While循环和两个队列结构传递数据。这种情况下,一个循环从仪器采集数据,一个循环专门执行信号处理,第三个循环将数据写入第二台仪器。
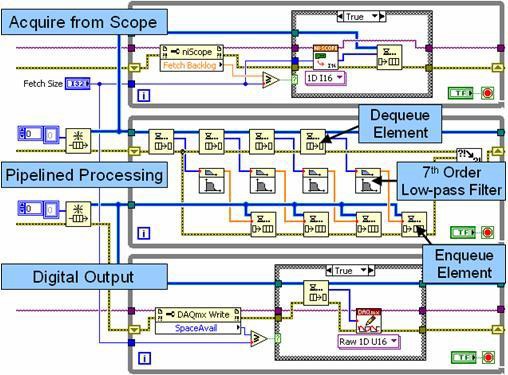
图10.使用结构框图对具有多个循环和队列结构的流水线信号处理进行说明。
图10中,顶层循环是一个生产者循环,用于从高速数字化仪采集数据并将其传递至第一个队列结构(FIFO)。中间循环既作为生产者又作为消费者。每次迭代期间,其从队列结构中卸载(消耗)多个数据集,并以流水线方式进行独立处理。这种流水线方法可独立处理多达四个数据集,从而提高多核处理器的性能。请注意,中间循环也可作为生产者,将处理后的数据传递至第二个队列结构。最后,底部循环将处理后的数据写入高速数字I/O模块。
并行处理算法可提高多核CPU的处理器利用率。事实上,总吞吐量取决于处理器利用率和总线传输速度这两个因素。一般来说,CPU和数据总线在处理大数据块时运行效率最高。此外,使用传输速度更快的PXI Express仪器还可进一步缩短数据传输时间。
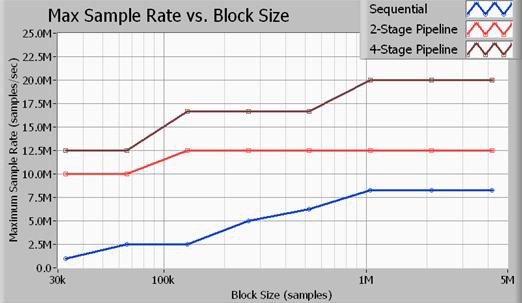
图11.多循环结构的吞吐率远快于单循环结构。
图11说明了根据采集大小(以样本为单位)来计算的最大吞吐率,以采样率为单位。此处所示的全部基准测试均基于16位采样执行。此外,此处使用的信号处理算法是一个七阶巴特沃斯低通滤波器,截止频率为采样率的0.45倍。如数据所示,使用四阶段流水线(多循环)方法可实现最大的数据吞吐量。请注意,两阶段信号处理方法的性能优于单循环方法(顺序),但其处理器使用效率低于四阶段方法。上述采样率是NI PXIe-5122高速数字化仪和NI PXIe-6537高速数字I/O模块输入和输出的最大采样率。请注意,在20MS/s时,应用总线以40MB/s的输入速率和40MB/s的输出速率传输数据,汇总后的总线带宽为80MB/s。
与此同时,应考虑流水线处理方法会在输入和输出之间引入延迟这一情况。延迟取决于多个因素,包括块大小和采样率。下表1和表2比较了单循环和四阶段多循环架构根据模块大小和最大采样率测量的延迟。
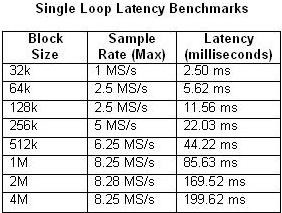
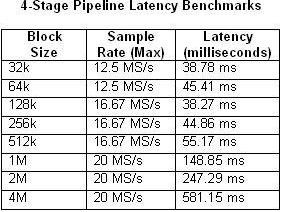
表1和表2.这些表格展示了单循环和四阶段流水线基准测试的延迟。
如您所料,延迟会随着CPU使用率接近100%而增加。采样率为20MS/s的四阶段流水线示例中尤为明显。相比之下,在任何单循环示例中,CPU使用率都几乎不超过50%。
结论
多核处理器技术的进步和数据总线速度的提高使PXI和PXI Express模块化仪器等基于PC的仪器受益无穷。由于新型CPU通过添加多个处理内核来提高性能,因此需要并行或流水线处理结构来最大限度提高CPU效率。幸运的是,LabVIEW通过将处理任务动态分配给各个处理内核,解决了这一编程难题。如图所示,通过构建LabVIEW算法以利用并行处理,可显著提高性能。