使用LabVIEW共享变量
概览
LabVIEW为创建分布式应用提供了多种多样的技术接口。共享变量可以简化此类应用的编程。本文将介绍共享变量,并讨论其功能和性能。
借助共享变量,您可以在同一个程序框图的不同循环之间或者网络上的不同VI之间共享数据。与LabVIEW中的许多其他数据共享方法(如UDP/TCP、LabVIEW队列及实时FIFO)不同,共享变量通常可在编辑时使用属性对话框进行配置,而无需在应用中添加配置代码。
您可以创建两种类型的共享变量:单进程共享变量和网络发布共享变量。本文将详细讨论单进程共享变量和网络发布共享变量。
内容
创建共享变量
要创建共享变量,必须先打开一个LabVIEW项目。在项目浏览器窗口中,右键单击终端、项目库或项目库中的文件夹,从快捷菜单中选择新建(New) » 变量(Variable),打开共享变量属性(Shared Variable Properties)对话框。选择所需的共享变量配置选项,然后单击确定(OK)按钮。
如果右键单击终端或不在项目库中的文件夹,并从快捷菜单中选择新建(New) » 变量(Variable)来创建共享变量,则LabVIEW会自动创建一个新项目库,并将共享变量置于该库中。如需详细了解变量和库,请参见共享变量生命周期部分。
图1显示的是一个单进程共享变量的共享变量属性(Shared Variable Properties)对话框。LabVIEW Real-Time模块和LabVIEW数据记录和监控(DSC)模块为共享变量提供了额外的功能和可配置属性。尽管在这个例子中,LabVIEW Real-Time模块和LabVIEW DSC模块均已安装,但您仍可以使用LabVIEW DSC模块仅针对网络发布共享变量而增加的功能。
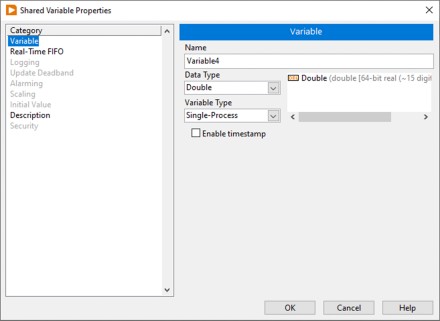
图1.单进程共享变量属性
数据类型
您可以从大量标准数据类型中为新建的共享变量选择数据类型。除了这些标准数据类型外,您还可以从数据类型(Data Type)下拉列表中选择自定义(Custom),并选择一个自定义控件作为自定义数据类型。然而,缩放和实时FIFO等部分功能将无法与某些自定义数据类型结合使用。 而且,如果您安装了LabVIEW DSC模块,那么在使用自定义数据类型时,警报将仅限于不良状态通知。
在配置完共享变量属性并单击确定(OK)按钮后,共享变量将显示在项目浏览器(Project Explorer)窗口的所选库或终端下,如图2所示。
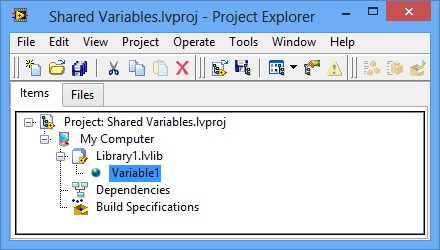
图2.项目中的共享变量
共享变量所属的终端就是LabVIEW部署和托管该共享变量的终端。如需详细了解如何部署和托管共享变量,请参见部署和托管部分。
变量引用
在将共享变量添加到LabVIEW项目后,可将其拖至VI的程序框图中来进行读或写操作,如图3所示。程序框图中读和写节点称为共享变量节点。
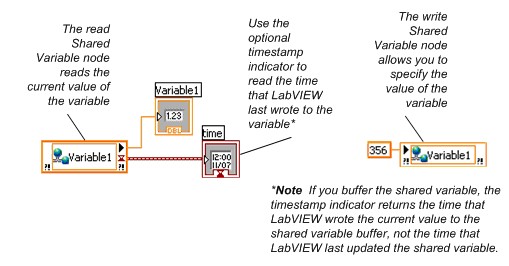
图3.使用共享变量节点读取和写入共享变量
您可以根据共享变量节点连接至变量的方式来指定节点是绝对节点或终端相对节点。绝对共享变量节点与创建该变量的终端上的共享变量连接。终端相对共享变量节点与该节点所属VI所在的终端上的共享变量连接。
如果将含有终端相对共享变量节点的VI移动到新的终端,则该共享变量也必须移动到新终端。因此,如果需要将VI和变量移至其他终端,建议使用终端相对共享变量节点。
默认的共享变量节点都是绝对的。如需更改共享变量节点连接到共享变量的方式,可右键单击该节点,然后选择引用模式(Reference Mode) » 终端相对(Target Relative)或者引用模式(Reference Mode) » 绝对(Absolute)。
您随时可以通过在项目浏览器窗口中右键单击共享变量来编辑共享变量的属性。LabVIEW项目会将新的设置自动传递给内存中引用的所有共享变量。保存变量库后,这些更改也将应用到存储在磁盘上的变量定义。
单进程共享变量
单进程变量用于传输同一个VI中不同位置间无法用连线连接的数据,例如同一个VI的并行循环,或者同一应用实例中的两个不同VI。单进程共享变量的底层实现与LabVIEW中全局变量相似。单进程共享变量相对于传统全局变量的主要优点是能够将单进程共享变量转换成网络发布共享变量,以便网络上的任何节点都可以访问。
单进程共享变量和LabVIEW Real-Time
为了保证确定性,实时应用需要使用一种无阻塞、确定性的机制来将数据从代码的确定性部分(如较高优先级定时循环和实时优先级VI)传输到非确定性部分。安装LabVIEW Real-Time模块后,您可以通过配置共享变量来使用实时FIFO,只需从共享变量属性(Shared Variable Properties)对话框中选择启用实时FIFO功能即可。NI建议采用实时FIFO在实时和较低优先级的循环之间传输数据。在单进程共享变量中,可通过启用实时FIFO来尽量避免使用底层实时FIFO VI。
当VI保留为执行时,LabVIEW会创建一个实时FIFO(这时大部分情况下应用程序的顶层VI开始运行),因此首次执行共享变量节点时,无需任何特别的考虑。
注意: 在旧版本的LabVIEW(8.6之前的版本)中,LabVIEW会在共享变量节点首次尝试写入或读取共享变量时创建一个实时FIFO。这一行为使得首次使用共享变量的执行时间会比随后使用时稍长。如果应用中要求极其精确的定时,可以在实时优先级循环内部放置初始“热身”迭代来解决接入时间波动的问题,或者在实时优先级循环外部至少对该变量进行一次读取操作。
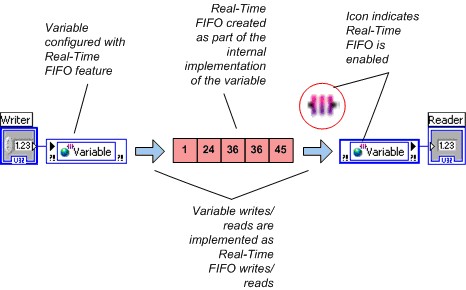
图4.已启用实时FIFO的共享变量
即使共享变量有多个写入线程或读取线程,LabVIEW也是为每个单进程共享变量创建单一的实时FIFO。为了保证数据的完整性,多个写入线程(读取线程)之间互斥。但读取线程和写入线程之间并不互斥。NI建议在实时优先级循环中,单进程共享变量应避免使用多个写入线程或读取线程。
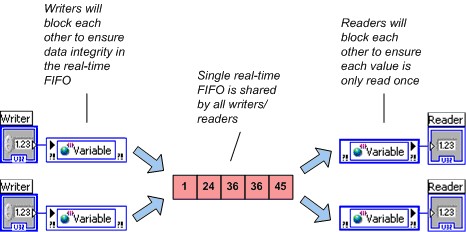
图5.多个写入和读取线程共享一个FIFO
启用实时FIFO后,启用FIFO的变量就有两种类型可供选择:即单元素和多元素缓冲区。这两类缓冲区之间的一个区别是:单元素FIFO不会对溢出或下溢情况进行报警。第二个区别是,多个读取线程读取空缓冲区时,LabVIEW返回的值不同。单元素FIFO的多个读取线程接收相同值,且单元素FIFO返回相同值直至写入线程再次写入该变量。空的多元素FIFO的多个读取线程将各自获得它们最后一次从缓冲区读取的值;如果之前没有读取过该变量,则会得到变量所属数据类型的默认值。该行为如下图所示。
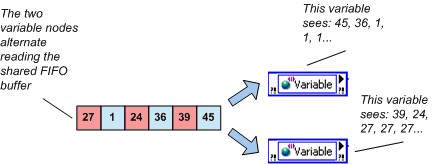
图6.最后一次读取行为以及多元素实时FIFO共享变量
如果应用要求每个读取线程获取写入多元素FIFO共享变量的每个数据点,则每个读取线程应使用独立的共享变量。
网络发布共享变量
利用网络发布共享变量,您可以在以太网网络上读写共享变量。网络应用的处理完全通过网络发布变量完成。
除了使数据可在网络外使用,网络发布共享变量中还增加了许多单进程共享变量所不具备的功能。由于这些增加的功能,网络发布共享变量的内部实现要比单进程共享变量要复杂得多。下文将讨论这方面内容,并给出利用网络发布共享变量来获得卓越性能的一些建议。
NI-PSP
NI发布-订阅协议(NI-PSP)是专为传输网络共享变量而优化的网络协议。 NI-PSP的最底层协议是TCP/IP,已重点针对桌面系统和NI RT终端的性能进行了全面的调整(参见以下基准测试性能比较)。
LogosXT的工作原理
图7所示为网络共享变量的软件栈。 由于此处所述的工作原理专门针对LogosXT堆栈级别,因此理解这一点很重要。 LogosXT是软件栈中负责优化共享变量吞吐量的层。
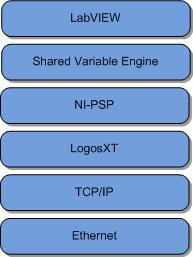
图7.共享变量网络堆栈
图8显示的是LogosXT传输算法的主要组成部分。 本质上,它非常简单。 其中两个最重要的组成部分是:
- 8 KB传输缓冲区
- 10 ms定时器线程
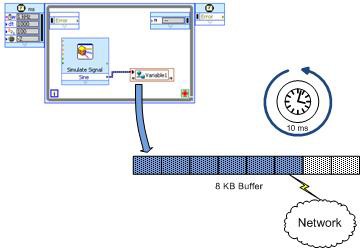
图8.LogosXT的主要组成部分。 当缓冲区满了或者10 ms过去之后,缓冲区的数据将传输出去
这些数字是在经过彻底分析各种数据包大小和时间后得出的,旨在优化数据吞吐量。 算法如下:
- 如果在10 ms定时器触发之前传输缓冲区容量已满(8 KB),则缓冲区中的数据会立即通过与启动写入操作相同的线程发送到TCP。 对于共享变量,该线程将是共享变量引擎线程。
- 如果10 ms过去了,缓冲区还没有填满,那么数据将通过定时器的线程发送出去。
重要说明:两个不同端点之间的所有连接共有一个传输缓冲区。 也就是说,代表两台不同机器之间的连接的所有变量将共享一个缓冲区。 但不要将此传输缓冲区与共享变量的缓冲属性混淆。 这个传输缓冲区是一个非常底层的缓冲区,它将变量多路复用到一个TCP连接中,从而优化了网络吞吐量。
由于网络堆栈这一层的功能会对LabVIEW程序框图上的代码产生负面作用,因此理解该功能很重要。 从吞吐量的角度来看,在单个发送操作中发送尽可能多的数据显然效率更高,因而该算法会等待10 ms。 从时间和数据包大小的角度来看,每个网络操作都有固定的开销。 如果我们发送许多小数据包(N个数据包),这些数据包总共包含B字节,那么我们需要支付N次网络开销。 然而,如果我们发送一个包含B字节的大数据包,那么我们只需支付一次固定开销,这样整体吞吐量要高得多。
如果需要以尽可能高的吞吐量与终端流式传输数据,则此算法非常适用。 另一个方面,如果不需要经常发送小数据包,例如向终端发送命令以执行某些操作(如断开继电器[1个字节的布尔数据]),但希望命令能尽快到达终端,则需要优化延迟。
如果对于应用来说,优化延迟更为重要,则需要使用“刷新共享变量数据”函数。 该VI将强制LogosXT中的传输缓冲区通过共享变量引擎和网络进行刷新。 这将极大降低延迟。
注意: 在LabVIEW 8.5中,不存在强制LogosXT刷新其缓冲区的情况,也不存在“刷新共享变量数据”函数。 由于程序会先等待传输缓冲区被填满,然后再按10 ms的定时频率将缓冲区接收到的数据发送出去,因此系统基本上至少会有10 ms的延迟。
但如上所述,将一台机器连接到另一台机器的所有共享变量均共享同一个传输缓冲区,因此如果调用“刷新共享变量数据”,将会影响系统上的许多其他共享变量。 而如果有其他依赖于高吞吐量的变量,调用刷新共享变量数据.vi (Flush Shared Variable Data.vi)则会对其产生不利影响(图9)。
图9.刷新共享变量数据.vi
部署与托管
网络发布共享变量必须部署到网络上托管该变量值的共享变量引擎(SVE)中。当写入一个共享变量节点时,LabVIEW会将这个新值发送给部署和托管该变量的SVE。SVE处理循环将发布该值,使得订阅者可以得到更新值。图10显示的就是这一过程。从客户端/服务器的角度来看,SVE是共享变量的服务器,所有对其的引用(不论是对变量进行写入还是读取操作)都是客户端。SVE客户端是每个共享变量节点实现中的一部分,在本文中,客户端和订阅者这两个术语是可互换的。
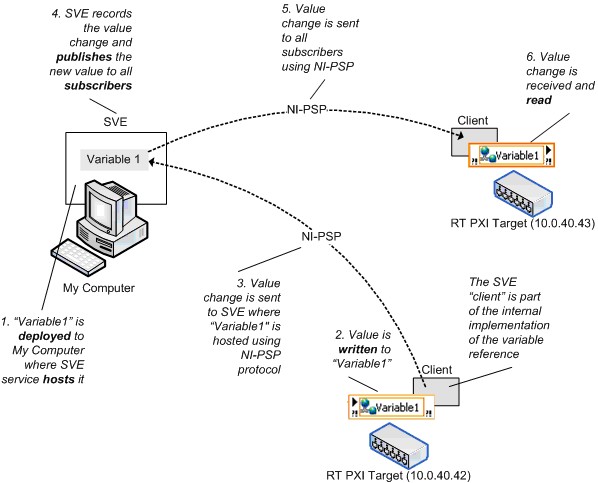
图10.共享变量引擎以及网络共享变量值的变化
网络发布变量和LabVIEW Real-Time
实时FIFO可以通过网络发布共享变量来启用,但与启用实时FIFO的单进程共享变量相比,启用FIFO的网络发布共享变量有一个重要的行为差异。上面说过,在单进程共享变量中,所有写入和读出操作共享一个单一的实时FIFO;但网络发布共享变量并非如此。无论是单元素和多元素情况下,网络发布共享变量的每一个读取线程都有各自的实时FIFO,如下所示。
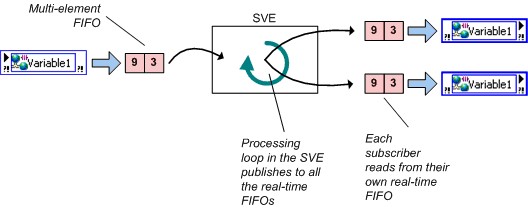
图11.启用实时FIFO的网络发布变量
网络缓冲
对于网络发布共享变量,您可以使用缓冲功能。在共享变量属性(Shared Variable Properties)对话框中,可以配置缓冲,如图12所示。
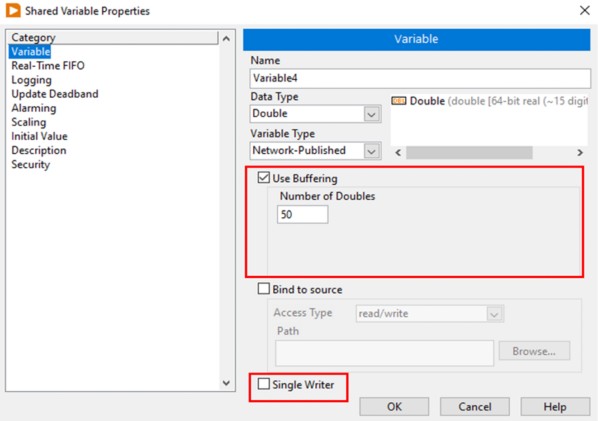
图12.在网络发布共享变量中启用缓冲功能
启用缓冲功能后,您能以数据类型的单位指定缓冲区的大小,在本例中,该数据类型为双精度。
缓冲功能可以解决对于变量读取/写入速度的临时波动问题。读取线程偶尔比写入线程慢的情况可能会导致一些更新数据的丢失。如果应用可以容忍偶尔的数据丢失,则较慢的读取速率并不会影响应用,此时就不需要启用缓冲功能。但是,如果读取线程必须获得每个更新数据,请启用缓冲功能。您可以在共享变量属性(Shared Variable Properties)对话框中的变量(Variable)页面设定缓冲区大小,这样就可以确定在旧数据被覆盖之前,应用可以保存多少更新数据。
在上述对话框中配置网络缓冲区时,您实际上是配置了两个不同缓冲区的大小。 服务器端缓冲区,即图13中标有共享变量引擎(SVE)的方框中的缓冲区,这是自动创建的,并被配置为与客户端缓冲区同样的大小,稍后再详细介绍该缓冲区。 客户端缓冲区就是在启用共享变量缓冲区时逻辑上认为的缓冲区。 客户端缓冲区(如图13右边所示)是负责维持先前值队列的缓冲区。 正是这一缓冲区避免了共享变量受到循环速度或网络流量波动的影响。
与启用实时FIFO的单进程变量(所有写入线程和读取线程共享相同的实时FIFO)不同,网络发布共享变量的每个读取线程都有自己的缓冲区,因此读取线程不会相互影响。
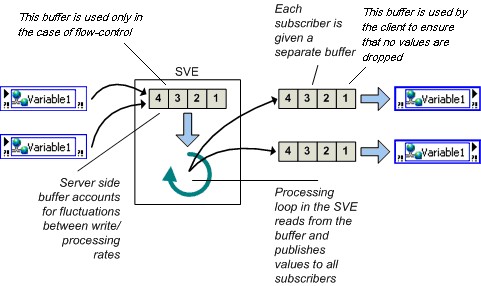
图13.缓冲
缓冲功能只适用于变量读取/写入速度存在临时波动的情况。如果程序运行的时间不确定,而读取线程速率总是低于写入线程速率,则不管将缓冲区设置为多大,最终都会出现数据丢失的情况。由于缓冲功能会为每个订阅者分配一个缓冲区,为避免不必要的内存占用,请仅在必要时使用缓冲功能。
网络和实时缓冲
如果同时启用网络缓冲和实时FIFO,则共享变量的执行中将同时包含一个网络缓冲区和一个实时FIFO。如前所述,启用实时FIFO后,将为每个读取线程和写入线程创建新的实时FIFO,使得多个写入线程和读出线程之间不会彼此阻塞。
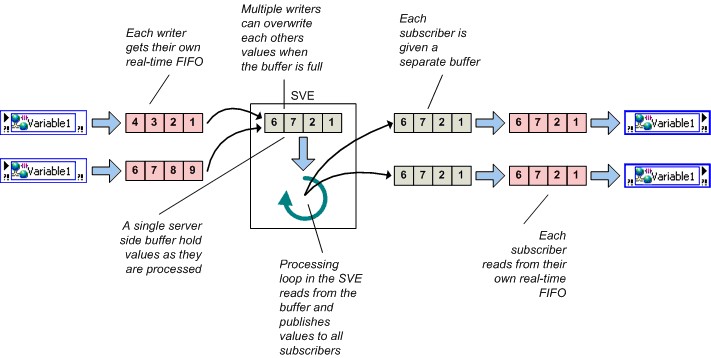
图14.网络缓冲和实时FIFO
虽然这两个缓冲区的大小可以独立设置,但在大多数情况下,NI建议将其设为同样的大小。如果启用实时FIFO,LabVIEW将为每个读取线程和写入线程创建新的实时FIFO。因此,多个写入线程和读出线程之间不会彼此阻塞。
缓冲区生命周期
LabVIEW在初始写入或读取操作时创建网络和实时FIFO缓冲区,具体取决于缓冲区的位置。
- 服务器端缓冲区在写入线程初始写入共享变量时创建。
- 客户端缓冲区在建立订阅时创建。
当包含共享变量节点的VI开始执行时,即会触发这些行为。 如果写入线程在特定读取线程订阅共享变量之前将数据写入共享变量,则该订阅者将无法得到这些初始数据值。
注意: 在LabVIEW 8.6之前,首次执行共享变量读取或写入节点时会创建缓冲区。
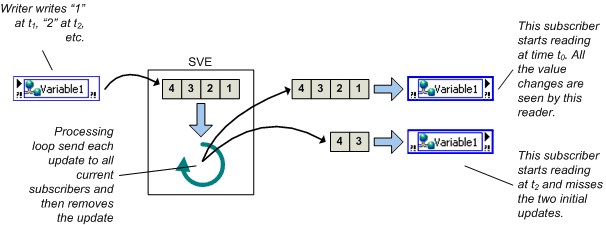
图15.缓冲区生命周期
缓冲区溢出/下溢
网络发布共享变量会报告网络缓冲区的溢出和下溢情况。不管是哪个版本,实时FIFO都会通过返回错误来指示溢出/下溢情况。
注意: 旧版LabVIEW不会报告网络缓冲区的溢出/下溢情况。 在LabVIEW 8.0或8.0.1,可以用下列两种方式检查网络缓冲下溢。由于共享变量时间标识的分辨率为1 ms,当以低于1 kHz的速率更新共享变量时,可以将变量的时间标识与后续读取操作的时间标识进行比较来检测缓冲区下溢。或者读取线程可以使用与数据绑定的序列号来报告缓冲区溢出/下溢。但如果数据类型是数组,则在实时优先级循环内不能对共享变量使用第二种方法,因为如果簇中的某个元素是数组,则启用实时FIFO的共享变量不支持自定义控件(簇)数据类型。
共享变量生命周期
如前所述,所有共享变量都是项目库的一部分。SVE将会注册项目库和库中包含的共享变量(当LabVIEW需要调用其中某个变量时)。默认情况下,只要运行引用任意所包含共享变量的VI时,SVE即会部署并发布共享变量库。由于SVE将部署包含该共享变量的整个库,因此无论所运行的VI是否引用库中的全部共享变量,SVE都将发布库中所有的共享变量。您随时可以手动部署任意项目库,只需要右键单击项目浏览器窗口的库即可。
停止VI或重启托管该变量的机器并不影响共享变量在网络上的可用性。如果需要删除网络上的共享变量,则必须明确地在项目浏览器窗口中解除该变量所属库的部署。也可选择工具(Tools) » 分布式系统管理器(Distributed System Manager)来解除共享变量或整个变量项目库的部署。
注意: 旧版LabVIEW使用变量管理器(工具(Tools) » 共享变量(Shared Variable) » 变量管理器(Variable Manager))而不是分布式系统管理器来管理共享变量的部署。
前面板数据绑定
另一个仅适用于网络发布共享变量的功能是前面板数据绑定。在项目浏览器窗口中,将共享变量拖拽到VI前面板,即可创建共享变量的绑定控件。当控件启用数据绑定时,改变控件的值将改变与其绑定的共享变量的值。在VI运行时,如果成功连接到SVE,则在VI的前面板对象旁边会出现一个绿色标记,如图16所示。

图16.将前面板控件绑定到共享变量
通过属性(Properties)对话框中的数据绑定(Data Binding)页面,可实现和改变任意输入控件和显示控件的绑定。当使用LabVIEW Real-Time模块或LabVIEW DSC模块时,选择工具(Tools) » 共享变量(Shared Variable) » 前面板批量绑定配置(Front Panel Binding Mass Configuration),即可显示前面板批量绑定配置(Front Panel Binding Mass Configuration)对话框,然后创建一个将多个输入控件和显示控件绑定到共享变量的操作界面。
针对在LabVIEW Real-Time系统上运行的应用程序,NI不建议使用前面板数据绑定功能,因为前面板可能不存在。
编程访问
如上所述,您可以使用LabVIEW项目来交互式创建、配置和部署共享变量,还可以使用程序框图上的共享变量节点或前面板的数据绑定来读写共享变量。LabVIEW 2009及之后版本还提供对于以上功能的编程访问。
在需要创建大量共享变量的应用中,可使用VI服务器,通过编程方式来建立项目库和共享变量。此外,LabVIEW DSC模块提供了一套全面的VI,让您能够通过编程方式来创建和编辑共享变量和项目库以及管理SVE。以编程方式创建共享变量库只能在Windows系统上实现,但通过编程来部署这些新库可在Windows或LabVIEW Real-Time系统上完成。
在需要动态更改VI读写的共享变量或需要读写大量变量的应用程序中,可使用编程共享变量API。您可以通过编程方式创建URL,然后动态更改共享变量。
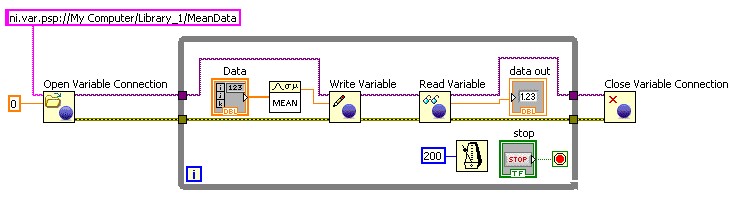
图17.使用编程共享变量API来读写共享变量
此外,由于NI LabWindows/CVI 8.1和NI Measurement Studio 8.1引入了网络变量库,您可以在ANSI C、Visual Basic .NET或者Visual C#环境下读写共享变量。
共享变量引擎
SVE是一个软件框架,使网络发布共享变量可通过网络将值传送出去。在Windows系统中,LabVIEW将SVE配置为一个服务,并在系统启动时启动SVE。在实时终端上,SVE是一个在系统开机时加载的可安装启动组件。
要使用网络发布共享变量,SVE必须至少在分布式系统的一个节点上运行。网络上的任何节点都可以读写SVE发布的共享变量。如表1所示,节点可以引用变量,无需安装SVE。如果需要根据应用需求在不同的位置部署共享变量,则可以在多个系统中同时安装多个SVE。
共享变量托管位置推荐
在分布式系统中,需要考虑一系列因素来决定由哪个计算设备部署和托管网络发布共享变量。
计算设备是否兼容SVE?
下表汇总了SVE适用的平台,并给出了可通过参考节点或DataSocket API使用网络发布共享变量的平台。NI要求所有适用平台至少能提供32 MB内存,但针对SVE建议采用64 MB内存。
注意,Linux或Macintosh系统尚不支持共享变量的托管。
Windows PC
| Mac OS
| Linux
| PXI
Real-Time | Compact FieldPoint
| CompactRIO
| Compact视觉系统
| 商用PC
(LabVIEW Real-Time ETS) | |
SVE
| X
| X
| ||||||
引用节点
| X
| X
| ||||||
DataSocket API(启用PSP)
|
应用需要数据记录和监控功能吗?
如果您想使用LabVIEW DSC模块的功能,则必须在Windows上托管共享变量。LabVIEW DSC模块对网络发布共享变量新增如下功能:
·NI总数据库的历史记录。
·联网警报和警报记录。
·缩放。
·基于用户的安全。
·初始值。
·创建自定义I/O服务器。
·将共享变量集成到LabVIEW事件结构中。
·以编程方式控制共享变量各个方面和共享变量引擎的LabVIEW VI。此类VI对于管理大量共享变量特别有帮助。
计算设备是否有足够的处理器和内存资源?
SVE是一项需要处理和内存资源的额外进程。为了在分布式系统中获得优异性能,请选择具有最大内存和最高处理能力的机器安装SVE。
哪个系统始终在线?
如果在分布式应用中,某些系统可能定期离线,则需将SVE托管在始终在线的系统上。
共享变量引擎的其他功能
图18列出了SVE的许多功能。除了管理网络发布共享变量外,SVE还负责:
·采集来自I/O服务器的数据。
·通过OPC和PSP的服务器为订阅者提供数据。
·为任何配置了缩放、警报和记录服务的共享变量提供这些服务。这些服务仅在使用LabVIEW DSC模块时可用。
·监测警报条件并进行相应响应。
I/O服务器
I/O服务器是SVE的插件,借助这些插件,程序可以使用SVE来发布数据。NI FieldPoint包含了一个I/O服务器,该服务器可直接将FieldPoint存储库的数据发布到SVE。由于SVE是OPC服务器,因此SVE和FieldPoint I/O服务器的结合构成了FP OPC服务器。注意FieldPoint安装程序中不包括SVE,您需要通过其他软件组件(如LabVIEW)安装SVE。
NI-DAQmx中也有一个I/O服务器,它可以自动将NI-DAQmx全局虚拟通道发布到SVE。这个I/O服务器取代了传统的DAQ OPC服务器和RDA。NI-DAQmx包含SVE并且可以在未安装LabVIEW的情况下进行安装。
使用LabVIEW DSC模块,用户可以新建I/O服务器。
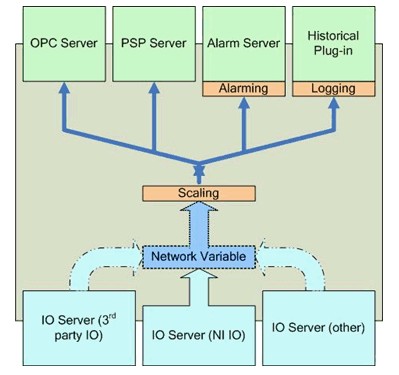
图18.共享变量引擎(SVE)
OPC
SVE是3.0兼容的,并可用作Windows机器上的OPC服务器。任何OPC客户端可对托管于Windows机器上的共享变量进行读写操作。在Windows机器上安装LabVIEW DSC模块后,SVE也可以用作OPC客户端。Windows托管的共享变量可以绑定到DSC的OPC数据项上,并对这些变量进行读写操作。
因为OPC是基于COM(一个Windows API)的技术,实时终端并不与OPC直接通信。如图19所示,您仍可以通过将共享变量托管到Windows来访问实时终端的OPC数据项。
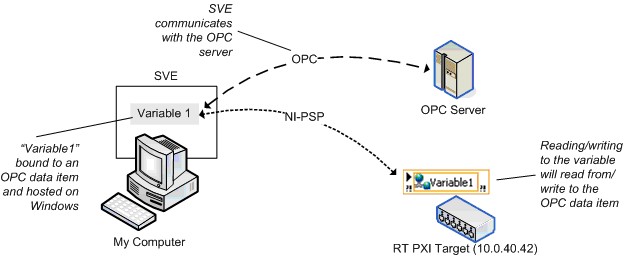
图19.绑定至OPC数据项
性能
本节为使用共享变量创建高性能应用提供了一般准则。
由于单进程共享变量的实现类似LabVIEW全局变量和实时FIFO,因此NI对于单进程共享变量如何获得卓越性能并没有给出特别的建议。以下各节均侧重于网络发布共享变量。
共享处理器
网络发布共享变量通过隐藏网络编程的许多实现细节,简化了LabVIEW的程序框图。一般来讲,应用程序中会包括LabVIEW VI、SVE以及SVE客户端代码。为了获得共享变量的卓越性能,开发应用时需要注意定期释放处理器以让SVE线程运行。为了实现这一点,一种方法是在处理循环中添加等待,并确保应用中不使用未定时循环。实际需要等待的精确时间取决于具体应用、处理器和网络;每个应用都需要根据经验进行一定程度的微调来达到优异性能。
SVE位置的考虑
共享变量托管位置推荐部分讨论了在选择安装SVE的位置时需要考虑的一系列因素。图20显示了另一个会明显影响共享变量性能的因素。本例包含了实时终端,但它的基本原则也适用于非实时系统。图20所示的是一个低效运用网络发布共享变量的例子:在实时终端上生成数据,然后需要将处理完的数据记录到本地,并通过远程机器进行监控。由于变量的订阅者必须从SVE接收数据,因此在高优先级循环中的写入操作和标准优先级循环中的读取操作之间将存在很大的延时,而且这一操作涉及整个网络中的两个来回。
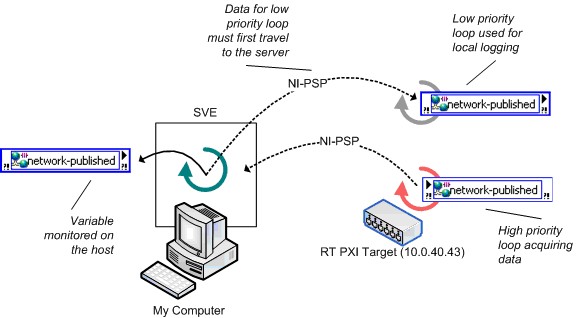
图20.实时系统中低效使用网络发布变量
图21给出了一个较好的应用程序框架。该应用程序采用单进程共享变量在高优先级循环和低优先级循环之间传输数据,极大地减少了等待时间。低优先级循环负责记录数据,并通过网络发布共享变量为主机端的订阅者写入数据更新。
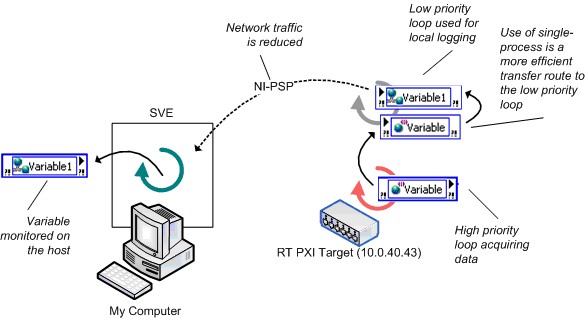
图21.实时系统中高效使用网络发布变量
基准测试
本部分比较了共享变量和LabVIEW中其他数据共享方法的性能,如LabVIEW的全局变量、实时FIFO、TCP/IP。下表总结了以下各节讨论的测试。
测试 | 描述 | SVE位置 | 说明 |
|---|---|---|---|
T1 | 单进程共享变量与全局变量 | N/A | 确定最大读取/写入速率 |
T2 | 启用实时FIFO的单进程共享变量与实时FIFO VI | N/A | 采用实时FIFO时,确定最大读取/写入速率。 确定在定时循环中写入到共享变量或实时FIFO并同时从标准优先级循环读回数据的最高可持续速率。 |
T3 | 启用实时FIFO的网络发布共享变量与启用TCP的双循环实时FIFO | 运行LV RT的PXI | 确定单点数据流经网络的最高速率。 共享变量:读取线程VI始终在主机上。RT-FIFO + TCP:类似T2,但具有TCP通信/IP网络。 |
T4 | 网络发布共享变量内存占用 | RT系列终端 | 确定共享变量部署后的内存使用量。 |
T5 | 比较8.2网络发布共享变量与8.5变量 - 数据流 | RT系列终端 | 比较NI-PSP在8.5中的新实现与在8.20或更早版本中的实现。 此基准测试测量了将cRIO设备的波形数据流式传输至桌面主机上时的吞吐量。 |
T6 | 比较8.2网络发布共享变量与8.5变量 - 高通道数 | RT系列终端 | 比较NI-PSP在8.5中的新实现与在8.20或更早版本中的实现。 此基准测试测量了cRIO设备上高通道数应用的吞吐量。 |
表2.基准测试概述
以下章节描述了NI为每个基准测试创建的代码,并给出了实际的基准测试结果。方法和配置部分详细讨论了每种基准测试选择的方法以及运行每个基准测试的软硬件环境的配置细节。
单进程共享变量与LabVIEW全局变量的比较
单进程共享变量与LabVIEW全局变量相似。事实上,单进程共享变量的实现是在LabVIEW全局变量的基础上增加了时间标识功能。
为了比较单进程共享变量与LabVIEW全局变量的性能,NI编写了多个基准测试VI,以测量VI每秒钟对LabVIEW全局变量或单进程共享变量进行读写的次数。图22显示的是单进程共享变量读取基准测试的程序框图。单进程共享变量写入基准测试和LabVIEW全局变量读取/写入基准测试遵循同一模式。
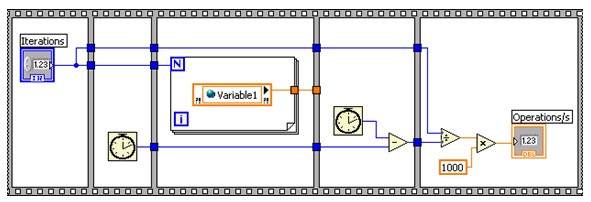
图22.单进程共享变量读取基准测试VI
综合读取/写入测试还包括了验证每个写入点都在同一循环中被无损读回的验证代码。
T1的测试结果
图23给出了T1的测试结果。结果表明,单进程共享变量的读取性能低于LabVIEW全局变量。而从写入性能以及读取/写入性能来看,单进程共享变量略低于LabVIEW全局变量。单进程共享变量的性能会受到是否启用时间标识功能的影响,因此如果没有必要,建议关闭时间标识功能。
方法和配置部分讲述了基准测试的具体方法和测试配置的细节。
图23.单进程共享变量与全局变量性能的比较
单进程共享变量与实时FIFO的比较
NI通过可持续吞吐量的基准测试来比较启用了FIFO的单进程共享变量和传统实时FIFO VI的性能。此基准测试中还测试了传送数据的大小或负载对以上两种实时FIFO实现的影响。
测试包括一个用于生成数据的实时优先级循环(TCL),以及一个用于消耗数据的标准优先级循环(NPL)。 NI通过对一系列双精度标量和数组数据类型进行测试来确定负载大小的影响。标量类型决定了负载为双精度数值时的吞吐量,数组类型决定了其余负载类型的吞吐量。在无数据丢失的情况下执行上述两个循环时的最大可持续速度就是该测试记录的最大可持续吞吐量。
图24给出了实时FIFO基准测试的简化程序框图,其中略去了许多用于创建和注销FIFO的必要代码。需要注意的是从LabVIEW 8.20开始,引入了一个可以替代此处所示FIFO子VI的新FIFO函数。本文中的数据图表即通过该FIFO函数得到,它比之前8.0.x中FIFO子VI的性能更好。
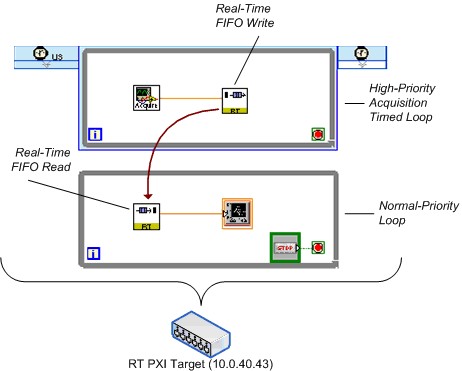
图24.简化的实时FIFO基准测试VI
另一个等效的测试中采用了单进程共享变量。图25显示的是该程序框图的简单描述。
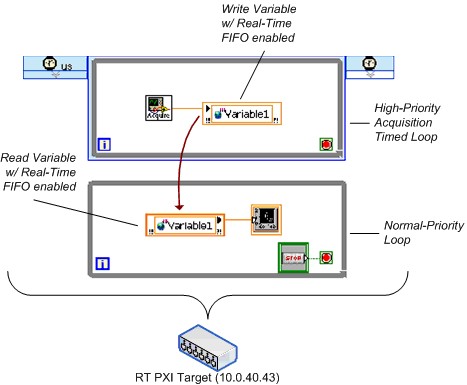
图25.启用FIFO的单进程共享变量基准测试的简化VI
T2的测试结果
图26和27给出了T2测试的结果,并比较了启用FIFO的单进程共享变量和实时FIFO函数的性能。结果表明,使用单进程共享变量的吞吐量略低于使用实时FIFO的吞吐量。
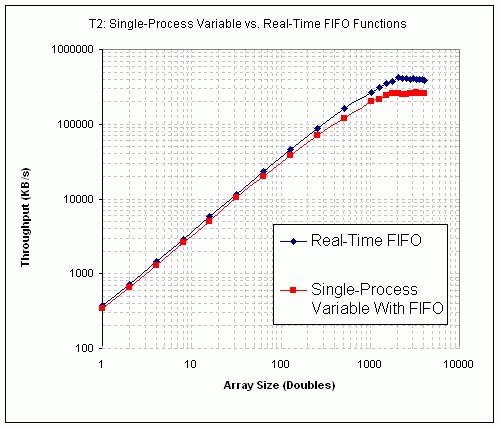
图26.单进程共享变量与实时FIFO VI的性能(PXI)的比较
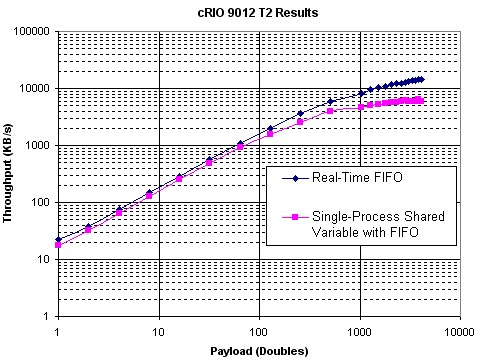
图27.单进程共享变量与实时FIFO VI性能的比较(cRIO 9012)
网络发布共享变量与实时FIFO和TCP/IP的比较
由于共享变量的灵活性,只需更改几个配置,就可以在网络中快速发布单进程共享变量。特别是对于实时应用,要在早期版本的LabVIEW中完成同样的传输,则需要引入大量的代码来读取RT系列控制器上的实时FIFO,然后从众多可用的网络协议中选择一个来实现数据的网络传输。为了比较二者性能的不同,NI同样创建了基准测试VI来测量在一系列负载条件下无数据丢失时的可持续吞吐量。
对于预变量方式,基准测试VI采用了实时FIFO和TCP/IP。TCL负责生成数据并将其放置在实时FIFO中;NPL负责从FIFO中读出数据并通过TCP/IP发送至整个网络。PC主机接收数据并验证没有丢失任何数据。
图28给出了实时FIFO和TCP/IP基准测试的简化程序框图。与上面相同,此程序框图对实际基准测试VI做了大幅简化。
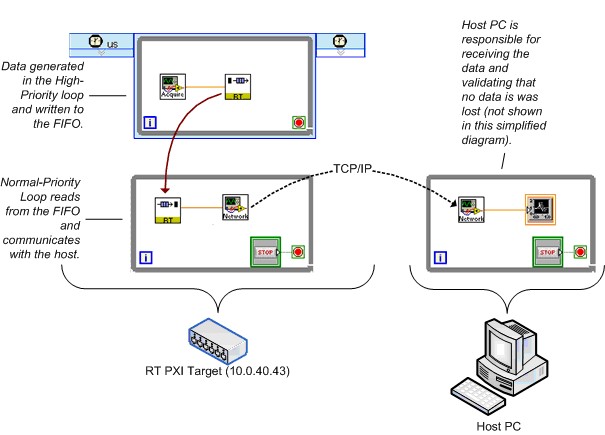
图28.简化的实时FIFO和TCP/IP基准测试VI
NI给出了一个使用网络发布共享变量的等效测试版本。图29显示的是简化的程序框图。
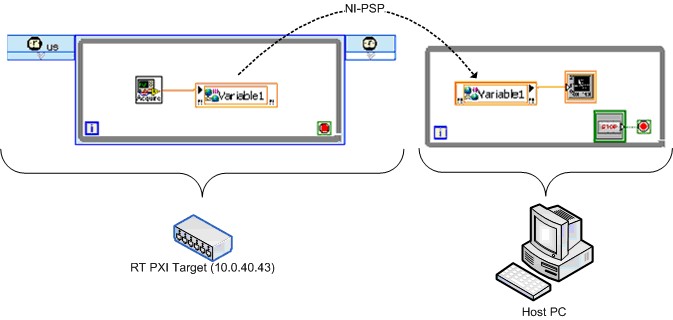
图29.启用了实时FIFO的网络发布共享变量基准测试的简化VI
T3的测试结果
本部分给出了T3测试的结果,比较了启用实时FIFO的网络发布共享变量和基于实时FIFO VI和LabVIEW TCP/IP的等效代码的性能。图30显示的是当LabVIEW Real-Time终端采用嵌入式RT系列PXI控制器时的结果。
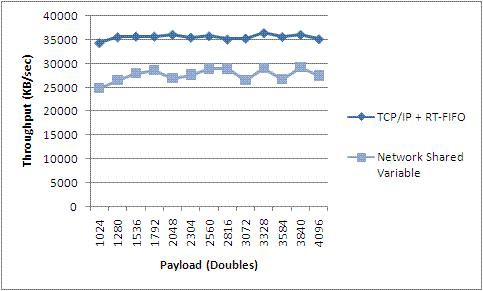
图30.网络发布共享变量与实时FIFO和TCP VI的性能比较(PXI)
T3的结果表明,网络发布共享变量的吞吐量与TCP方法的接近,而且在中高负载下,两种方法的吞吐量基本保持一致。 共享变量使编程工作更容易,但并不是没有代价的。 但应注意,如果仅使用简单的TCP方法,其性能很可能不如共享变量,特别是对于在8.5中新增加的NI-PSP而言。
T4的测试结果
网络发布共享变量的内存占用
注意在LabVIEW 8.5中,没有对变量占用内存做出明显改变。 因此,这个基准测试并未重新运行。
确定共享变量的内存占用并非易事,因为其占用的内存取决于配置。例如,带有缓冲区的网络发布共享变量会根据需要在程序中动态分配内存。除了网络缓冲区外,LabVIEW也会为FIFO创建缓冲区,因此为共享变量启用实时FIFO也会增加内存使用。综上所述,本文的基准测试结果仅提供内存的基本测量。
图31显示了在LabVIEW将500和1000个指定类别的共享变量部署到SVE时SVE占用的内存。该图表明变量类型并不显著影响所部署共享变量使用的内存。这里需要注意的是,这些变量都是非缓冲变量。
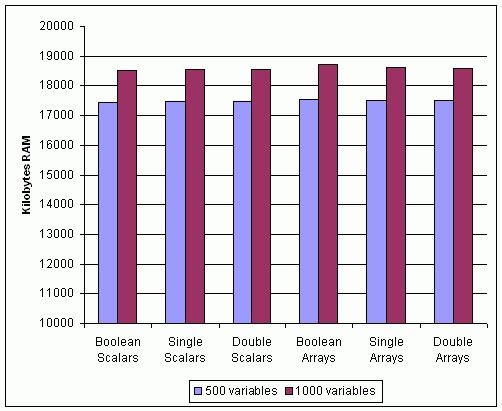
图31.采用不同数据类型的网络发布共享变量的内存使用量
图32显示了内存使用相对于所部署共享变量数目的函数关系。这项测试只使用一种类型的变量,即空的布尔数组。内存使用量随变量数量的增加而线性增大。
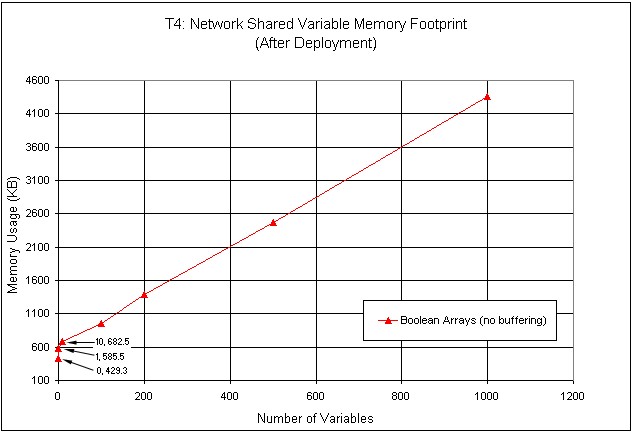
图32.不同大小的共享变量的内存使用量
T5的测试结果
比较8.2网络发布共享变量与8.5变量-数据流
在LabVIEW 8.5中,我们已经实现了用于传输共享变量数据的网络协议底层。 它能够提供更好的性能。
在这里,我们在cRIO 9012上托管一个双精度波形类型的变量。 我们生成所有数据,然后在一个小循环中将数据传送到主机,这时主机将尽可能快地从另一个波形共享变量节点中读取数据。
从图30可以看到,LabVIEW 8.5中的性能获得了明显改善,在本例中提高了600%以上。
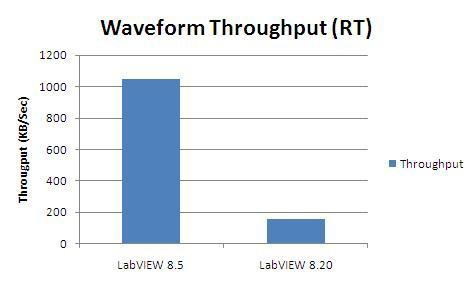
图33.LabVIEW 8.5和LabVIEW 8.20(或更早版本)的波形吞吐量比较
T6的测试结果
比较8.2网络发布共享变量与8.5变量-数据流
在这项测试中,我们使用与T5相同的两个终端,但是与传送单变量不同,我们将数据类型设为双精度并使共享变量的数量在1 - 1000间变化,同时不断测量吞吐量。 同样,所有的变量都托管于cRIO 9012,在其上不断生成数据并传送到主机等待读取。
图34再次显示出从LabVIEW 8.20至LabVIEW 8.5性能有着显著的提升。 然而,多个小变量与T5中单一大变量的情形相比,吞吐量显著减少。 这是因为每一个变量都有与本身相关的固定空间开销。 当使用多个变量时,这种开销会乘以变量数目,因而变得非常明显。
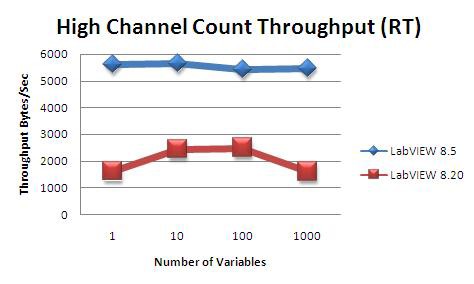
图34.LabVIEW 8.5和LabVIEW 8.20(或更早版本)的高通道数吞吐量比较
方法和配置
本部分提供了上述所有基准测试的详细信息。
T1的方法和考虑因素
T1测试使用了一个简单的基准测试模板,通过在大量迭代后进行简单的求平均值来确定读写速率。每次测试执行时共5.0亿次迭代按分钟记录执行时间,分辨率单位是毫秒。
T1的软硬件配置
主机硬件
- Dell Precision 450
- Intel Xeon 2.4 GHz奔腾双核处理器
- 1 GB DRAM
主机软件
- Windows XP SP2
- LabVIEW 8.20
T2的方法和考虑因素
T2测试是通过确定不同优先级任务之间的最大可持续通信速率来确定吞吐量。具有毫秒分辨率的定时循环用于生成数据。自由运行的标准优先级循环用于消耗数据,它从实时FIFO或者单进程共享变量读取数据直到空为止,在没有出错的条件下重复这一过程,并持续一定的时间。当满足下列所有条件时,测试结果是有效的:
- 没有发生缓冲区溢出
- 数据完整性得以保持:没有丢失数据,且收到的数据和发送的数据次序一致
- 定时循环在指定的热身时间1秒后可以准确定时
单进程共享变量接收端循环执行简单的数据完整性检查,例如确保预期数量的数据点均已收到,而且收到的信息模式并不缺乏中间值。
对于所有测试变量和涉及到的数据类型,NI针对实时FIFO和共享变量FIFO缓冲区将缓冲区大小配置为100个元素。
T2的软硬件配置
PXI硬件
- NI PXI-8196 RT系列控制器
- 2.0 GHz奔腾处理器
- 256 MB DRAM
- Broadcom 57xx(1 Gb/s内置式以太网适配器)
PXI软件
- LabVIEW 8.20 Real-Time模块
- 网络变量引擎1.2.0
- 变量客户端支持1.2.0
- Broadcom 57xx千兆以太网驱动程序2.1,配置为轮询模式
CompactRIO硬件
- NI cRIO 9012控制器
- 400 MHz处理器
- 64 MB DRAM
CompactRIO软件
- LabVIEW 8.20 Real-Time模块
- 网络变量引擎1.2.0
- 变量客户端支持1.2.0
T3的方法和考虑因素
T3测试通过直接记录网络上的数据传输数量和整体测试时间来测量吞吐量。具有毫秒分辨率的定时循环用于生成数据,它负责将特定的数据模式写入网络发布共享变量或实时FIFO VI。
对于网络发布共享变量,NPL运行于主机系统,并从一个自由运行的While循环的变量中读取数据。而对于实时FIFO VI的测试情况,NPL运行于实时系统,按一定的速率检查FIFO的状态,读取所有的可读数据,并通过TCP发送至网络。基准测试结果表明,该轮询有效期可设定为1或10 ms。
当满足下列所有条件时,测试结果是有效的:
- 不管在FIFO还是网络上,没有发生缓冲区溢出
- 数据完整性得以保持:没有丢失数据,且收到的数据和发送的数据次序一致
- TCL VI中的定时循环在指定的热身时间1秒后可以准确定时
读取完每个数据点以后,网络变量测试的NPL会检查数据模式的正确性。对于实时FIFO测试,TCL负责根据实时FIFO是否发生溢出进行数据验证。
为了避免数据丢失,NI会将缓冲区大小配置为不小于NPL和TCL循环周期之比,对于实时FIFO缓冲区则设置最小100个元素的下边界。
T3的软硬件配置
主机硬件
- Intel Core 2 Duo 1.8 GHz
- 2 GB DRAM
- Intel PRO/1000(1 Gb/s以太网适配器)
主机软件
- Windows Vista 64
- LabVIEW 8
网络配置
1Gb/s开关网络
PXI硬件
- NI PXI-8196 RT控制器
- 2.0 GHz奔腾处理器
- 256 MB DRAM
- Broadcom 57xx(1 Gb/s内置式以太网适配器)
PXI软件
- LabVIEW 8.5 Real-Time模块
- 网络变量引擎1.2.0
- 变量客户端支持1.2.0
- Broadcom 57xx千兆以太网驱动程序2.1
T4的方法和考虑因素
在T4测试中,NI采用具有下列数据类型的非缓冲网络发布共享变量:双精度、单精度、布尔型、双精度数据、单精度数组、布尔数组等。
T4的软硬件配置
PXI硬件
- NI PXI-8196 RT控制器
- 2.0 GHz奔腾处理器
- 256 MB DRAM
- Broadcom 57xx(1 Gb/s内置式以太网适配器)
PXI软件
- LabVIEW Real-Time模块8.0
- 网络变量引擎1.0.0
- 变量客户端支持1.0.0
- Broadcom 57xx千兆以太网驱动程序1.0.1.3.0
T5和T6的方法和考虑因素
在T5和T6测试中,NI采用双精度波形类型的非缓冲网络发布共享变量。
T5和T6的软硬件配置
主机硬件
- 64位Intel Core 2 Duo 1.8 GHz
- 2 GB RAM
- 千兆以太网
主机软件
- Windows Vista 64
- LabVIEW 8.20和LabVIEW 8.5
CompactRIO硬件
- cRIO 9012
- 64 MB RAM
CompactRIO软件
- LabVIEW RT 8.20和LabVIEW RT 8.5
- 网络变量引擎1.2 (LabVIEW 8.20)和1.4 (LabVIEW 8.5)
- 变量客户端支持1.0 (LabVIEW 8.20)和1.4 (LabVIEW 8.5)