NI LabVIEW Compiler: 심층 탐구
개요
내용
여기서는 LabVIEW 컴파일러를 소개하고, 1986년 LabVIEW 1.0을 시작으로 LabVIEW가 어떤 발전을 거쳤는지 알아보고, 현재의 사용에 대해 간략하게 살펴봅니다. 또한 최근의 컴파일러 혁신을 살펴보고 이러한 새로운 기능이 LabVIEW 아키텍처와 사용자에게 가져다 주는 이점을 집중적으로 살펴봅니다.
컴파일과 해석
LabVIEW는 컴파일된 언어이므로 일반적인 G 개발 과정에서 명시적인 컴파일 단계가 없습니다. 대신 VI를 변경하고 실행 버튼을 눌러 실행하기만 하면 됩니다. 컴파일이란 사용자가 작성한 G 코드가 기본 머신 코드로 변환된 후 호스트 컴퓨터가 직접 실행한다는 의미입니다. 컴파일의 대안인 해석의 경우 프로그램을 컴퓨터가 직접 실행하는 대신 다른 소프트웨어 프로그램(인터프리터라고 함)에서 간접적으로 실행합니다.
LabVIEW 언어의 어떤 부분도 컴파일 또는 해석이 필요 없습니다. 하지만 LabVIEW 의 첫번째 버전에서는 인터프리터를 사용했었습니다. 이후 버전에서는 VI 런타임 성능 향상을 위해 컴파일러가 인터프리터를 대체했습니다. 이러한 성능 향상은 컴파일러가 인터프리터보다 뛰어난 일반적인 차별화 요소입니다. 인터프리터는 런타임 성능이 저하되지만 작성 및 유지 관리가 더 쉬운 경향이 있는 반면, 컴파일러는 구현하기가 더 복잡하지만 실행 시간이 더 빠릅니다. LabVIEW 컴파일러의 주요 이점 중 하나는 어떤 것도 변경할 필요 없이 모든 VI에서 컴파일러의 개선 사항을 볼 수 있다는 것입니다. 사실, LabVIEW 2010 릴리즈에서는 VI 실행 시간을 단축하기 위해 컴파일러 내부를 최적화하는 데 중점을 두었습니다.
발전 과정을 통해 살펴보는 LabVIEW 컴파일러
현재 사용되는 컴파일러의 내부에 대해 자세히 살펴보기 전에 20여 년 전의 초창기 형태부터 컴파일러의 개발 과정을 간략하게 살펴보겠습니다. Type propagation, Clumping, Inplaceness 등 여기에 소개된 일부 알고리즘에 대한 내용은 최신 LabVIEW 컴파일러에 대해 살펴보는 부분에 더 자세히 나와있습니다.
LabVIEW 1.0은 1986년에 출시되었습니다. 앞서 언급한 것처럼 LabVIEW는 첫 번째 버전에서 인터프리터를 사용했으며 Motorola 68000만을 대상으로 하였습니다. 당시에는 LabVIEW 언어가 훨씬 더 단순했기 때문에 컴파일러 (당시의 인터프리터)에 대한 요구사항 역시 적었습니다. 예를 들어, 다형성이 없었고 유일한 숫자 유형은 확장 정밀도 부동소수점이었습니다. LabVIEW 1.1에서는 Inplaceness 알고리즘 즉, "Inplacer"가 도입되었습니다. 이 알고리즘은 실행 중에 재사용할 수 있는 데이터 할당을 식별하여 불필요한 데이터 복사를 방지하고 결과적으로 실행 성능을 크게 향상시킵니다.
LabVIEW 2.0에서는 인터프리터가 실제 컴파일러로 대체되었습니다. 여전히 Motorola 68000만을 대상으로 하였지만 LabVIEW는 기본 머신 코드를 생성할 수 있었습니다. 또한 버전 2.0에는 Type propagation 알고리즘이 추가되었습니다. 이 알고리즘은 무엇보다 점점 커지는 LabVIEW 언어에서 구문 확인 및 유형 확인을 처리합니다. LabVIEW 2.0에서 구현된 또 다른 큰 혁신은 clumper의 도입입니다. Clumping 알고리즘은 LabVIEW 다이어그램에서 병렬 처리를 식별하고 노드를 병렬로 실행할 수 있는 "클럼프"로 그룹화합니다. Type propagation, Inplaceness 및 Clumping 알고리즘은 여전히 최신 LabVIEW 컴파일러의 중요한 구성 요소이며 시간이 지남에 따라 많은 부분이 개선되었습니다. LabVIEW 2.5에서 새로 도입된 컴파일러 인프라는 여러 백엔드, 특히 Intel x86 및 Sparc에 대한 지원을 추가했습니다. 또한 LabVIEW 2.5에는 VI 간 종속성을 관리하여 다시 컴파일해야 하는 시점을 추적하는 링커가 도입되었습니다.
LabVIEW 3.1에서는 상수 계산 단순화와 함께 PowerPC 및 HP PA-RISC라는 새로운 백엔드 두 개가 추가되었습니다. LabVIEW 5.0 및 6.0은 코드 생성기를 개선하고 여러 백엔드에 공통 인터페이스인 GenAPI를 추가했습니다. GenAPI는 크로스 컴파일을 실행하는데 이는 리얼타임 개발에 중요합니다. 리얼타임 개발자는 일반적으로 호스트 PC에서 VI를 작성하여 리얼타임 타겟에 배포 (및 컴파일)합니다. 또한 제한된 형태의 루프 불변 코드 모션이 포함되었습니다. 마지막으로, LabVIEW 멀티태스킹 실행 시스템이 여러 스레드를 지원하도록 확장되었습니다.
LabVIEW 8.0은 레지스터 할당 알고리즘을 추가하기 위해 버전 5.0에서 도입된 GenAPI 인프라를 기반으로 구축되었습니다. GenAPI를 도입하기 전, 레지스터는 각 노드에 대해 생성된 코드에 하드코딩되었습니다. 제한된 형태의 도달할 수 없는 코드와 데드 코드 제거 역시 도입되었습니다. LabVIEW 2009는 64비트 LabVIEW와 DFIR (Dataflow Intermediate Representation)을 지원합니다. DFIR은 더욱 발전된 형태의 루프 불변 코드 모션, 상수 계산 단순화, 데드 코드 제거 및 도달할 수 없는 코드 제거를 작성하는 데 즉시 사용되었습니다. 병렬 For 루프와 같이 2009년에 도입된 새로운 언어 기능은 DFIR을 기반으로 합니다.
마지막으로, LabVIEW 2010에서 DFIR은 Algebraic reassociation, Common subexpression elimination, Loop unrolling 및 SubVI Inlining과 같은 새로운 컴파일러 최적화 기능을 제공합니다. 또한 이 릴리즈에서는 LabVIEW 컴파일러 체인에 LLVM (Low-Level Virtual Machine)이 채택되었습니다. LLVM은 업계에서 널리 사용되는 오픈 소스 컴파일러 인프라입니다. LLVM을 통해 Instruction scheduling, Loop unswitching, Instruction combining, Conditional propagation 및 More sophisticated register allocator와 같은 새로운 최적화 기법이 추가되었습니다.
현재 사용되는 컴파일 과정
LabVIEW 컴파일러의 발전 과정을 간략히 이해하였으므로 이제는 최신 LabVIEW에서 컴파일 과정을 살펴보겠습니다 먼저 다양한 컴파일 단계를 개략적으로 살펴본 후 각 부분을 다시 자세히 살펴보겠습니다.
VI 버전 컴파일의 첫 번째 단계는 Type propagation 알고리즘입니다. 이 복잡한 단계는 타입에 따라 변경되는 터미널의 암시적 타입을 확인하고 구문 에러를 감지하는 역할을 합니다. G 프로그래밍 언어에서 가능한 모든 구문 에러는 Type propagation 알고리즘 실행 중 감지됩니다. 이 알고리즘이 VI가 유효하다고 결정하면, 컴파일이 계속 진행됩니다.
Type propagation 이후 VI는 먼저 블록다이어그램 편집기가 사용하는 모델에서 컴파일러가 사용하는 DFIR로 변환됩니다. 일단 DFIR로 변환되면, 컴파일러는 DFIR 그래프에서 여러 변환을 실행하여 이를 분해하고, 최적화하고, 코드 생성을 위해 준비합니다. 컴파일러 최적화(예: inplacer 및 clumper) 중 다수는 변환으로 구현되고 이 단계에서 실행됩니다.
DFIR 그래프가 최적화되고 단순화된 후, LLVM 중간 표현으로 변환됩니다. 일련의 LLVM 패스가 중간 표현에서 실행되어 더욱 최적화되고 최종적으로 머신 코드로 변환되었습니다.
Type propagation
앞서 언급했듯이 Type propagation 알고리즘은 타입을 확인하고 프로그래밍 에러를 감지합니다. 실제로 이 알고리즘에는 다음과 같은 몇 가지 기능이 있습니다.
- 타입에 따라 변경할 수 있는 터미널의 함축된 타입 확인
- SubVI 호출 확인 및 유효성 확인
- 와이어 방향 계산
- VI에서 사이클 확인
- 구문 에러 감지 및 보고
이 알고리즘은 VI를 변경할 때마다 실행되어 VI가 여전히 유효한지 확인합니다. 따라서 이 단계가 "컴파일"의 일부인지 여부는 다소 논쟁의 여지가 있습니다. 그러나 이 단계는 기존 컴파일러의 어휘 분석, 분석 또는 의미 분석에 해당하는 LabVIEW 컴파일 체인의 단계입니다.
타입에 따라 변경되는 터미널의 간단한 예는 LabVIEW의 더하기 원형입니다. 정수 두 개를 더하면 결과는 정수 하나이지만, 부동소수 두 개를 더하면 결과는 부동소수 한 개입니다. 배열 및 클러스터와 같은 복합 타입에도 유사한 패턴을 볼 수 있습니다. 시프트 레지스터와 같이 입력 규칙이 보다 복잡한 다른 언어 구조도 있습니다. 더하기 원형의 경우, 출력 타입은 입력 타입에 따라 결정되며, 이 타입은 다이어그램을 통해 이 알고리즘을 "전파"라고 합니다.
이 더하기 원형 예제는 또한 Type propagation 알고리즘의 구문 확인 기능을 보여줍니다. 정수와 문자열을 더하기 원형에 연결한다고 가정해 보겠습니다. 어떻게 될까요? 이 경우, 이 두 값을 더하는 것은 의미가 없으므로, Type propagation 알고리즘은 이를 에러로 보고하고 VI를 "불량"으로 표시하여 실행 화살표가 깨진 상태로 표시됩니다.
중간 표현의 정의 및 필요한 이유
Type propagation이 VI가 유효하다고 결정하면 계속 컴파일하고 VI는 DFIR로 변환됩니다. DFIR을 자세히 설명하기 전에 일반적인 중간 표현 (IR)을 살펴보겠습니다.
IR은 다양한 단계를 통해 컴파일이 진행됨에 따라 조작되는 사용자 프로그램의 표현한 것입니다. IR의 개념은 최신 컴파일러 관련 문서에서 일반적으로 다루며 모든 프로그래밍 언어에 적용할 수 있습니다.
몇 가지 예를 살펴보겠습니다. 오늘날 다양한 IR이 널리 사용되고 있습니다. 두 가지 일반적인 예로는 추상 구문 트리 (AST)와 3개 주소 코드가 있습니다.
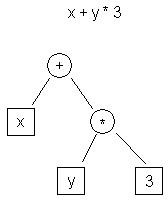 | t0 <- y t1 <- 3 t2 <- t0 * t1 t3 <- x t4 <- t3 + t2 |
| 그림 1. AST IR 예제 | 표 1. 3개 주소 코드 IR 예제 |
그림 1은 "x + y * 3" 수식의 AST 표현을 보여주며, 표 1은 3-주소 코드 표현을 보여줍니다.
이 두 표현의 한 가지 분명한 차이점은 AST가 훨씬 상위 레벨이라는 것입니다. 이는 타겟 표현 (머신 코드)보다 프로그램 (C)의 소스 표현에 더욱 가깝습니다. 이와 대조적으로 3개 주소 코드는 하위 레벨이며 어셈블리와 유사합니다.
상위 레벨과 하위 레벨 표현 둘 다 각각의 장점이 있습니다. 예를 들어, 의존성 분석과 같은 분석은 3 주소 코드와 같은 하위 레벨 표현보다 AST와 같은 상위 레벨 표현에서 수행하는 것이 더 쉬울 수 있습니다. 레지스터 할당 또는 명령 스케줄링과 같은 다른 최적화는 일반적으로 3 주소 코드와 같은 하위 레벨 표현에서 수행됩니다.
IR마다 장단점이 다르기 때문에 많은 컴파일러 (LabVIEW 포함)에서는 IR을 여러 개 사용합니다. LabVIEW 의 경우, DFIR은 상위 레벨 IR로 사용되는 반면, LLVM IR은 하위 레벨 IR로 사용됩니다.
DFIR
LabVIEW에서 상위 레벨 표현은 계층구조 및 그래프 기반이며 G 코드 자체와 닮은 DFIR입니다. G와 같이, DFIR은 다양한 노드로 구성되며, 각 노드에는 터미널이 있습니다. 터미널은 다른 터미널에 연결할 수 있습니다. 루프와 같은 일부 노드는 다이어그램을 포함하며, 다이어그램은 다른 노드를 포함할 수 있습니다.
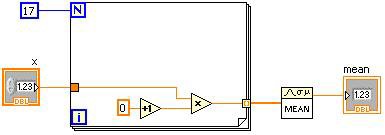
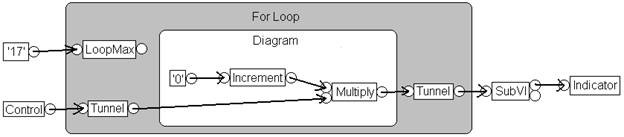
그림 2. LabVIEW G 코드와 해당하는 DFIR 그래프
그림 2는 초기 DFIR 표현과 함께 간단한 VI를 보여줍니다. VI의 DFIR 그래프가 처음 생성되면, 이는 G 코드가 직접 변환된 것이며, DFIR 그래프의 노드는 일반적으로 G 코드의 노드와 일대일로 대응됩니다. 컴파일이 진행됨에 따라, DFIR 노드가 이동 또는 분리되거나, 새로운 DFIR 노드가 삽입될 수 있습니다. DFIR의 주요 장점 중 하나는 G 코드 고유의 병렬 처리와 같은 특성을 보존한다는 점입니다. 이와 달리 3개 주소 코드로 표현되는 병렬 처리는 식별하기가 훨씬 어렵습니다.
DFIR은 LabVIEW 컴파일러에 두 가지 중요한 이점을 제공합니다. 먼저, DFIR은 VI의 컴파일러 표현에서 편집기를 분리합니다. 둘째, DFIR은 프런트엔드와 백엔드가 여러 개인 컴파일러의 공통 허브 역할을 합니다. 각 장점에 대해 더 자세히 살펴보십시오.
DFIR 그래프는 편집기와 컴파일러 표현을 분리합니다.
DFIR이 등장하기 전 LabVIEW에는 편집기와 컴파일러가 공유하는 VI의 단일 표현이 있었습니다. 이로 인해 컴파일러는 컴파일 과정에서 표현을 수정할 수 없었고, 이로 인해 컴파일러 최적화를 도입하는 데 어려움이 있었습니다.

그림 3. DFIR은 컴파일이 코드를 최적화할 수 있는 프레임워크를 제공합니다.
그림 3은 앞서 소개한 VI의 DFIR 그래프를 보여줍니다. 이 그래프는 여러 변환이 분해되고 최적화된 후 컴파일러 프로세스의 훨씬 더 늦은 시점을 보여줍니다. 보시다시피, 이 그래프는 이전 그래프와 상당히 다르게 보입니다. 예를 들면 다음과 같습니다.
- 분해 변환으로 인해 컨트롤, 인디케이터, SubVI 노드가 제거되고 새로운 노드(UIAccessor, UIUpdater, FunctionResolver, FunctionCall)로 대체되었습니다.
- 루프 불변 코드 동작이 증가 및 곱하기 노드를 루프 본문 밖으로 이동
- clumper가 For 루프 안에 YieldIfNeeded 노드를 삽입하여 실행 중인 스레드가 다른 경쟁 작업 아이템과 실행을 공유하도록 함
변환은 이후 섹션에서 더 자세히 설명합니다.
DFIR IR은 여러 컴파일러 프런트엔드 및 백엔드의 공통 허브 역할을 수행합니다
LabVIEW는 여러 다른 타겟과 작동하는데, 이러한 타겟은 x86 데스크탑 PC와 Xilinx FPGA 등과 같이 서로 매우 다릅니다. 마찬가지로 LabVIEW는 사용자에게 여러 연산 모델을 제공합니다. 예를 들어, LabVIEW는 G에서의 그래픽 프로그래밍 외에도 MathScript에서 텍스트 기반 수학을 제공합니다. 그 결과, 프런트엔드와 백엔드 모음이 생성되며 둘 다 LabVIEW 컴파일러와 함께 작동해야 합니다. 모든 프런트엔드가 생성하고 모든 백엔드가 소비하는 공통 IR로 DFIR을 사용하면 다양한 조합 사이에서 쉽게 재사용할 수 있습니다. 예를 들어, DFIR 그래프에서 실행되는 상수 계산 단순화 최적화의 구현은 한 번 작성하여 데스크탑, 리얼타임, FPGA 및 임베디드 타겟에 적용할 수 있습니다.
DFIR 분해
DFIR에서 VI는 먼저 일련의 분해 변환을 거치며 실행됩니다. 분해 변환은 DFIR 그래프를 축소하거나 정규화하는 것을 목표입니다. 예를 들어, 연결되지 않은 출력 터널 분해는 연결되지 않았으며 "연결되지 않으면 기본값 사용"으로 설정된 케이스 구조 및 이벤트 구조에서 출력 터널을 찾습니다. 이러한 터미널의 경우, 변환은 기본값을 가진 상수를 삭제하고 터미널에 연결하여 DFIR 그래프에서 "연결되지 않은 경우 기본값 사용" 동작을 명시적으로 만듭니다. 이후의 컴파일러 패스는 모든 터미널을 동일하게 취급하고 모든 터미널에 연결된 입력이 있다고 가정합니다. 이 경우, 언어의 "연결되지 않은 경우 기본값 사용" 기능은 표현을 보다 근본적인 형태로 축소함으로써 "컴파일"되었습니다.
이 개념은 보다 복잡한 언어 기능에도 적용할 수 있습니다. 예를 들어, 분해 변환은 피드백 노드를 While 루프의 시프트 레지스터로 줄이는 데 사용됩니다. 또 다른 분해는 병렬 For 루프를 몇몇 추가 로직이 있는 여러 순차적인 For 루프로 실행함으로써 순차적인 루프를 위해 입력을 병렬화 가능한 부분으로 나누고 각 부분을 차후에 결합합니다.
LabVIEW 2010의 새로운 기능인 SubVI 인라인도 DFIR 분해로 구현됩니다. 이 컴파일 단계에서, “인라인”으로 표시된 SubVI의 DFIR 그래프는 호출자의 DFIR 그래프에 직접 주입됩니다. 인라인은 SubVI 호출의 오버헤드를 피하는 것 외에도 호출자와 피호출자를 단일 DFIR 그래프로 결합하여 추가적인 최적화 기회를 제공합니다. 예를 들어, vi.lib에서 Trim Whitespace.vi를 호출하는 간단한 VI를 생각해 보겠습니다.
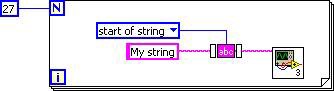
그림 4. DFIR 최적화를 보여주는 간단한 VI 예제
Trim Whitespace.vi는 다음과 같이 vi.lib로 정의됩니다.
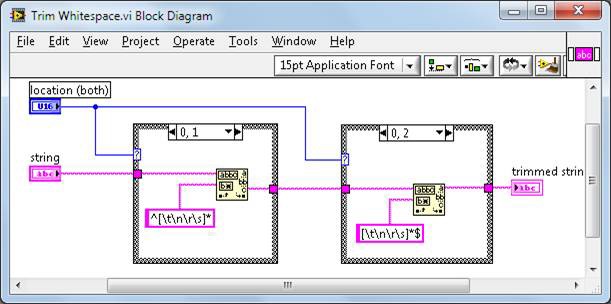
그림 5. TrimWhitespace.vi 블록다이어그램
SubVI는 호출자로 인라인되므로, 그 결과로 다음의 G 코드에 상응하는 DFIR 그래프가 나옵니다.
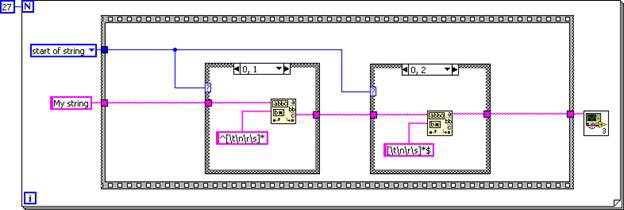
그림 6. 인라인된 Trim Whitespace.vi DFIR 그래프에 해당되는 G 코드
SubVI의 다이어그램이 호출자 다이어그램으로 인라인되었으므로, 도달할 수 없는 코드 제거 및 데드 코드 제거를 통해 코드를 단순화할 수 있습니다. 첫 번째 케이스 구조는 항상 실행되는 반면, 두 번째 케이스 구조는 실행되지 않습니다.
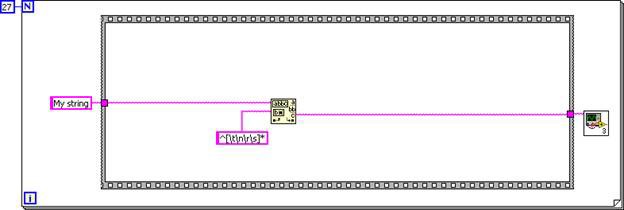
그림 7. 입력 로직이 일정하기 때문에 케이스 구조를 제거할 수 있음
마찬가지로, 루프 불변 코드 모션은 패턴 일치 원형을 루프 밖으로 이동합니다. 최종 DFIR 그래프는 다음 G 코드에 해당합니다.
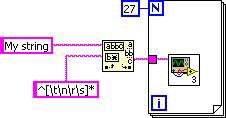
그림 8. 최종 DFIR 그래프에 해당하는 G 코드
LabVIEW 2010에서는 기본적으로 Trim Whitespace.vi가 인라인으로 표시되기 때문에 이 VI의 모든 클라이언트는 자동으로 이러한 이점을 얻습니다.
DFIR 최적화
DFIR 그래프가 완전히 분해된 후, DFIR 최적화 패스가 시작됩니다. LLVM 컴파일 중에 나중에 더 많은 최적화가 수행됩니다. 이 섹션에서는 많은 최적화 중 일부만 다룹니다. 이러한 각 변환은 일반적인 컴파일러 최적화이므로 특정 최적화에 대한 더 자세한 정보를 쉽게 찾을 수 있습니다.
도달할 수 없는 코드 제거
실행할 수 없는 코드에는 접근할 수 없습니다. 도달할 수 없는 코드를 제거해도 실행 시간이 바로 단축되는 것은 아니지만, 제거된 코드가 다음 컴파일 단계에서 다시 탐색되지 않기 때문에 코드가 줄고 컴파일 시간이 빨라집니다.
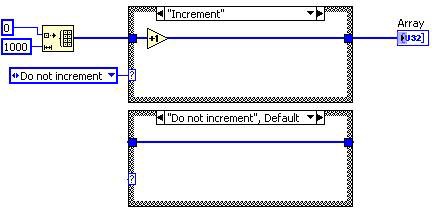
도달할 수 없는 코드 제거 전

도달할 수 없는 코드 제거 후
그림 9. DFIR 도달할 수 없는 코드 제거 분해에 해당하는 G 코드
이 경우, 케이스 구조의 "증가" 다이어그램은 실행되지 않으므로 변환은 해당 케이스를 제거합니다. 케이스 구조에는 케이스가 하나만 남아있기 때문에 시퀀스 구조로 대체됩니다. 데드 코드 제거는 나중에 프레임과 열거형 상수를 제거합니다.
루프 불변 코드 모션
루프 불변 코드 모션은 안전하게 밖으로 이동할 수 있는 루프 본문 내부의 코드를 식별합니다. 이동된 코드의 실행 횟수가 줄기 때문에 전체 실행 속도가 향상됩니다.
Loop invariant code motion 이전 | Loop invariant code motion 이후 |
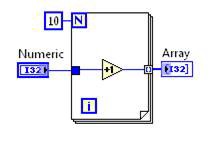
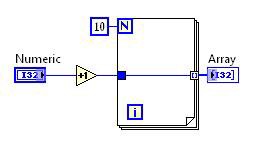
그림 10. DFIR 루프 불변 코드 모션 분해에 해당하는 G 코드
이 경우, 증가 연산은 루프 밖으로 이동합니다. 루프 본문은 그대로 남아있어 배열을 작성할 수 있지만, 반복할 때마다 다시 계산할 필요는 없습니다.
Common Subexpression Elimination
Common Subexpression Elimination은 반복된 계산을 식별하여 한 번만 수행하고, 그 결과를 다시 사용합니다.
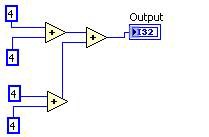
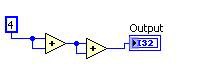
이전 이후
그림 11. DFIR Common Subexpression Elimination 분해에 해당하는 G 코드
상수 계산 단순화
상수 계산 단순화는 다이어그램에서 런타임에 상수인 부분을 식별하므로 초반에 확인할 수 있습니다.
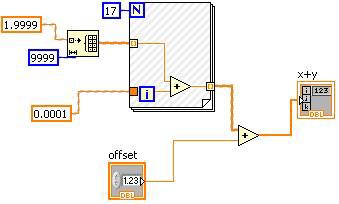
그림 12. 상수 계산 단순화는 LabVIEW 블록다이어그램에서 시각화할 수 있음
그림 12의 VI에 있는 해시 표시는 상수 계산 단순화 부분을 나타냅니다. 이 경우, "오프셋" 컨트롤은 상수 계산을 단순화할 수 없지만, For 루프를 포함하여 더하기 원형의 다른 피연산자는 상수값입니다.
Loop Unrolling
Loop Unrolling은 생성된 코드에서 루프의 본문을 여러 번 반복하고 전체 반복 횟수를 같은 비율로 줄여 루프 오버헤드를 줄입니다. 이렇게 하면 루프 오버헤드가 줄고 코드 크기가 약간 증가하지만 추가 최적화 기회가 제공됩니다.
데드 코드 제거
데드 코드는 불필요한 코드입니다. 데드 코드를 제거하면 제거된 코드가 더 이상 실행되지 않기 때문에 실행 시간이 단축됩니다.
데드 코드는 일반적으로 사용자가 직접 작성하지 않은 변환으로 인해 DFIR 그래프가 조작되어 생성됩니다. 다음의 예를 생각해 보겠습니다. 도달할 수 없는 코드 제거는 케이스 구조를 제거할 수 있는지 확인합니다. 이렇게 하면 데드 코드 제거 변환이 제거할 수 있는 데드 코드가 "생성"됩니다.
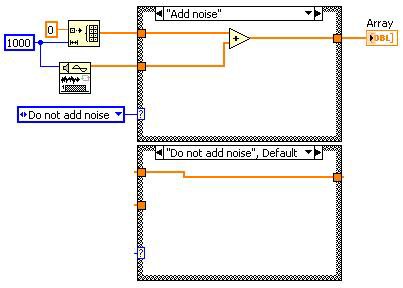
이전
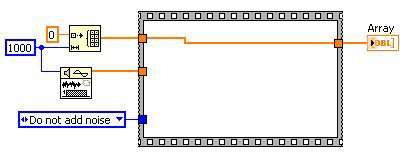
도달할 수 없는 코드 제거 후
데드 코드 제거 후
그림 13. 데드 코드를 제거하면 컴파일러가 탐색해야 하는 코드의 양을 줄일 수 있음
이 섹션에서 다루는 대부분의 변환은 다음과 같은 상관관계가 있습니다. 하나의 변환을 실행하면 다른 변환이 실행될 기회가 생길 수 있습니다.
DFIR 백엔드 변환
DFIR 그래프가 분해되고 최적화된 후, 여러 백엔드 변환이 실행됩니다. 이러한 변환은 DFIR 그래프를 LLVM IR로 낮추기 위해 DFIR 그래프를 평가하고 주석을 추가합니다.
Clumper
Clumping 알고리즘은 DFIR 그래프의 병렬 처리를 분석하고 노드를 병렬로 실행할 수 있는 클럼프로 그룹화합니다. 이 알고리즘은 멀티스레드 협력 멀티태스킹을 사용하는 LabVIEW의 런타임 실행 시스템과 밀접한 관련이 있습니다. Clumper가 생성하는 각 클럼프는 실행 시스템에서 개별 태스크로 예약됩니다. 클럼프 내의 노드는 직렬화되어 고정된 순서로 실행됩니다. 각 클럼프의 실행 순서를 미리 정하면 Inplacer가 데이터 할당을 공유하고 성능이 크게 향상됩니다. 또한 Clumper는 루프 또는 I/O와 같은 긴 작업에 yield를 삽입하여, 이러한 클럼프가 다른 클럼프와 협력하여 멀티태스킹을 수행할 수 있도록 합니다.
Inplacer
Inplacer는 DFIR 그래프를 분석하고 데이터 할당을 다시 사용할 수 있는 경우와 복사본을 만들어야 하는 경우를 식별합니다. LabVIEW의 와이어는 단순한 32비트 스칼라 또는 32MB 배열일 수 있습니다. LabVIEW와 같은 데이터 흐름 언어에서는 데이터를 최대한 많이 재사용하는 것이 중요합니다.
다음 예를 생각해 보십시오(최상의 성능과 메모리 공간을 얻기 위해 VI의 디버깅은 비활성화되어 있음).
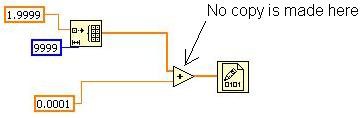
그림 14. Inplaceness 알고리즘을 보여주는 간단한 예제
이 VI는 배열을 초기화하고, 각 요소에 일부 스칼라 값을 추가하고, 이를 2진 파일에 씁니다. 배열 복사본이 몇 개 있어야 할까요? LabVIEW는 초기에 배열을 생성해야 하지만, 더하기 연산은 해당 배열에서만 작동할 수 있습니다. 따라서 와이어당 하나의 할당이 아니라 배열 복사본이 하나만 필요합니다. 이는 배열이 큰 경우 메모리 소비와 실행 시간 둘 다에서 상당한 차이를 가져옵니다. 이 VI에서 Inplacer는 이 기회를 인식하여 "In Place" 동작을 수행하고 이를 활용하기 위해 더하기 노드를 설정합니다.
도구≫프로파일 아래의 “버퍼 할당 보이기” 도구를 사용하여 사용자가 작성하는 VI의 동작을 확인할 수 있습니다. 이 도구는 더하기 원형에 대한 할당을 표시하지 않으며, 이는 데이터 사본이 생성되지 않고 더하기 연산이 발생함을 나타냅니다.
이는 다른 노드가 원래 배열을 필요로 하지 않기 때문에 가능합니다. 그림 15와 같이 VI를 수정하는 경우 Inplacer는 더하기 원형에 대한 복사본을 만들어야 합니다. 이는 두 번째 2진 파일에 쓰기 원형이 원래 배열을 필요로 하고 첫 번째 2진 파일에 쓰기 원형 이후에 실행되어야 하기 때문입니다. 이렇게 수정하면 버퍼 할당 보이기 도구가 더하기 원형의 할당을 보여줍니다.
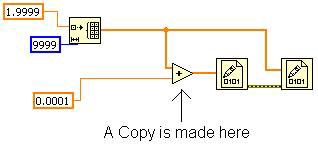
그림 15. 원본 배열 와이어를 분기하면 메모리에서 복사본이 생성됨
할당기
Inplacer가 다른 노드와 메모리 위치를 공유할 수 있는 노드를 식별하면 VI가 실행해야 하는 할당을 생성하기 위해 할당기가 실행됩니다. 이는 각 노드와 터미널을 방문하여 구현됩니다. 다른 터미널을 기준으로 제자리에 있는 터미널은 새 할당을 생성하는 대신 다시 할당을 재사용합니다.
코드 생성기
코드 생성기는 DFIR 그래프를 타겟 프로세서의 실행 가능한 머신 명령어로 변환하는 컴파일러의 구성요소입니다. LabVIEW는 DFIR 그래프의 각 노드를 데이터 흐름 순서로 탐색하고, 각 노드는 GenAPI로 알려진 인터페이스를 호출합니다. GenAPI는 DFIR 그래프를 해당 노드의 기능을 설명하는 순차적인 중간 언어 (IL) 형태로 변환하는 데 사용됩니다. IL은 플랫폼에 독립적인 방법을 사용하여 노드의 하위 레벨 동작을 설명합니다. IL의 다양한 명령은 산술, 메모리 읽기, 메모리에 쓰기를 수행하고 비교 및 조건 분기 등을 수행하는 데 사용됩니다. IL 명령어는 메모리 또는 중간 값을 저장하는 데 사용되는 버추얼 레지스터에 저장된 값에서 작동할 수 있습니다. IL 명령어의 예로는 GenAdd, GenMul, GenIf, GenLabel 및 GenMove가 있습니다.
LabVIEW 2009 및 이전 버전에서는 이 IL 형식이 타겟 플랫폼의 머신 명령 (예: 80X86 및 PowerPC)으로 직접 변환되었습니다. LabVIEW는 간단한 1 패스 레지스터 할당기를 사용하여 버추얼 레지스터를 물리적 머신 레지스터에 맵핑했으며, 각 IL 명령은 지원되는 각 타겟 플랫폼에서 구현하기 위해 하드 코딩된 특정 머신 명령 세트를 내보냅니다. 이 방법은 매우 빠르기는 하지만 임시방편에 불과하며 부실한 코드를 생성하므로 최적화에 적합하지 않았습니다. 플랫폼과 상관 없는 상위 레벨 표현인 DFIR은 지원할 수 있는 코드 변환의 종류에 제한이 있습니다. 최신 최적화 컴파일러에서 전체 코드 최적화 세트에 대한 지원을 추가하기 위해 LabVIEW는 LLVM이라는 타사 오픈 소스 기술을 최근에 채택했습니다.
LLVM
LLVM (Low-Level Virtual Machine)은 일리노이 주립대에서 연구 프로젝트 목적으로 개발된 다용도 고성능 개방 소스 컴파일러 프레임워크입니다. LLVM은 유연하고 깔끔한 API와 제한적이지 않은 라이센스로 인해 학계와 산업계에서 널리 사용되고 있습니다.
LabVIEW 2010에서는 LabVIEW 코드 생성기가 LLVM을 사용하여 타겟 머신 코드를 생성하도록 리팩토링되었습니다. 기존의 LabVIEW IL 표현은 편리한 시작점을 제공하므로 LabVIEW가 지원하는 더욱 큰 DFIR 노드와 원형 세트가 아니라 약 80개의 IL 명령만이 재작성하면 됩니다.
VI의 DFIR 그래프에서 IL 코드 스트림을 생성한 후 LabVIEW는 각 IL 명령을 방문하여 해당하는 LLVM 어셈블리 표현을 생성합니다. 다양한 최적화 패스를 호출한 후 LLVM JIT (Jist-in-Time) 프레임워크를 사용하여 메모리에 실행 가능한 머신 명령을 생성합니다. LLVM의 머신 이전 정보는 LabVIEW 표현으로 변환되므로, VI를 디스크에 저장하고 다른 메모리 베이스 주소에 다시 로드할 때, 새 위치에서 실행되도록 올바르게 패치할 수 있습니다.
LabVIEW가 LLVM을 사용하여 수행하는 표준 컴파일러 최적화는 다음과 같습니다.
- Instruction combining
- Jump threading
- Scalar replacement of aggregates
- Conditional propagation
- Tail call elimination
- Expression reassociation
- Loop invariant code motion
- Loop unswitching and index splitting
- Induction variable simplification
- Loop unrolling
- Global value numbering
- Dead store elimination
- Aggressive dead code elimination
- Sparse conditional constant propagation
이 문서에서는 위의 모든 최적화 기법에 대한 자세히 설명하지 않지만, 인터넷뿐 아니라 대부분의 컴파일러 교재를 통해 자세한 정보를 확인할 수 있습니다.
내부 벤치마크를 통해 살펴본 결과, LLVM을 사용함으로써 VI 실행 시간이 평균 20 퍼센트 증가하였습니다. 개별 결과는 VI가 수행하는 계산의 특성에 따라 달라집니다. 다시 말해, 일부 VI는 결과가 더욱 우수했고 또 다른 VI에서는 성능의 변화가 없었습니다. 예를 들어, 고급 분석 라이브러리를 사용하는 VI 또는 최적화된 C로 이미 구현된 코드에 크게 의존하는 VI는 성능에 거의 차이가 없습니다. LabVIEW 2010은 LLVM을 사용하는 첫 번째 버전이며 향후 개선될 가능성이 여전히 많습니다.
DFIR과 LLVM이 함께 실행됨
루프 불변 코드 모션 및 데드 코드 제거와 같은 일부 최적화 기법은 DFIR이 수행한다고 이미 설명했습니다. 실제로 일부 최적화 패스는 컴파일러의 다른 레벨에서 여러 번 실행하는 것이 좋습니다. 다른 최적화 패스가 코드를 변환하여 새로운 최적화 기회를 제공할 수 있기 때문입니다. 중요한 점은 DFIR은 상위 레벨 IR이고 LLVM은 하위 레벨 IR이지만, 이 두 가지가 함께 실행되어 코드 실행에 사용되는 프로세서 아키텍처를 위해 작성한 LabVIEW 코드를 최적화한다는 사실입니다.