LabVIEWで開発する組み込みアプリケーションを最適化する
概要
組み込みアプリケーションを開発する際、メモリの制約やタイムクリティカルなコード要件など、システム上の制約がプログラミングの方向性に重要な影響を与えることがあります。ソフトウェア実装にボトルネックがあってはなりません。このドキュメントでは、組み込みアプリケーションの最適化に役立つプログラミング手法の概要を説明します。ここで紹介するテクニックは、すべてのARM、Blackfin、組み込みターゲットに適用できます。
内容
メモリ割り当て
ダイナミックメモリ割り当ては行わないでください。 タイムクリティカルなコードでは、ダイナミックメモリ割り当ては大きな負荷がかかります。LabVIEWで開発する組み込みアプリケーションでは、「配列連結追加」関数と「文字列連結」関数を使用する際にダイナミックメモリ割り当てが実行されます。または、「配列連結追加」関数の代わりに「部分配列置換」関数を使用して、割り当て済みの配列の要素を入れ替えることもできます。配列定数または「配列初期化」関数を使用して、割り当て済みの配列をループの外側に作成する必要があります。以下の図は、異なる実装を比較しています。
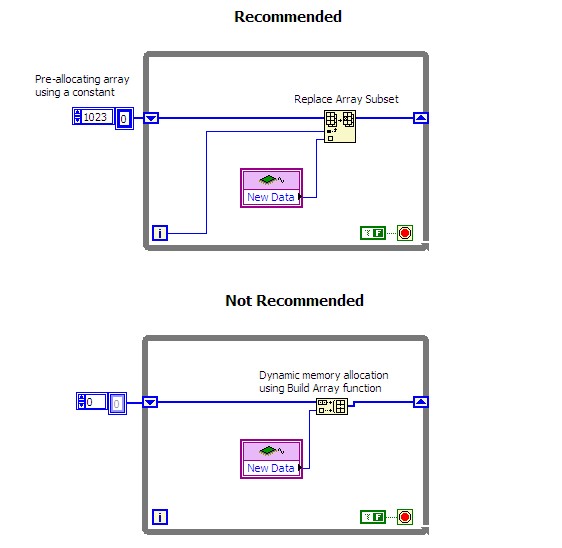
データ配置
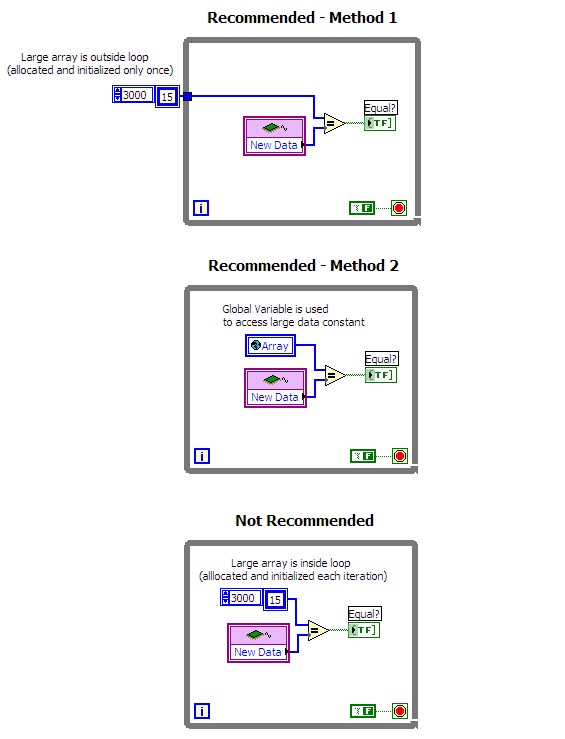
大きな定数をループ内に配置しないでください。 大きな定数をループ内に配置すると、ループの各反復の開始時に、LabViewでメモリの割り当てと配列の初期化が行われます。この処理は、タイムクリティカルなコードでは大きな負荷がかかる可能性があります。代わりに、配列をループの外側に配置し、ループトンネルを経由して配線するか、あるいはグローバル変数を使用してデータにアクセスします。以下の図は、推奨される方法を示しています。
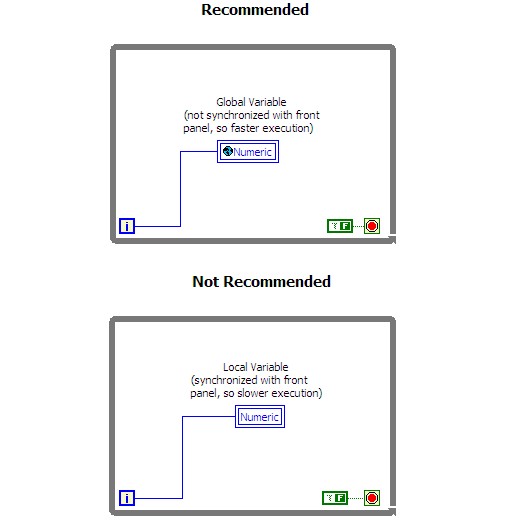
ローカル変数ではなくグローバル変数を使用してください。 ローカル変数にアクセスすると、そのたびにフロントパネルと同期するための余分なコードが実行されます。 多くの場合、ローカル変数の代わりにグローバル変数を使用することで、コードのパフォーマンスを向上させることができます。グローバル変数の場合、余分なフロントパネル同期コードが実行されないため、ローカル変数よりもわずかに速く実行できます。以下の図は、異なる実装を比較しています。
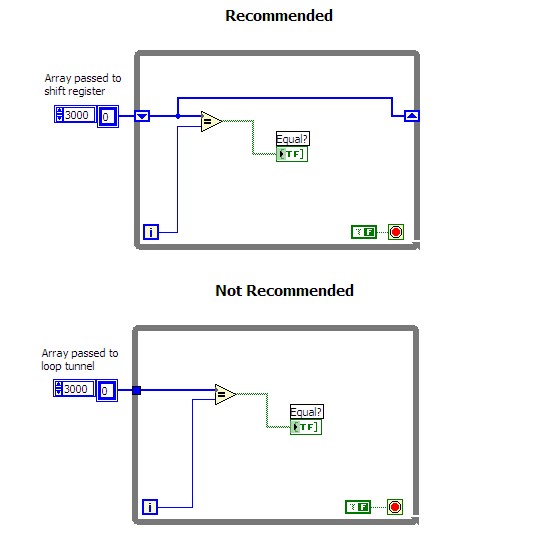
大きな配列ではループトンネルの代わりにシフトレジスタを使用してください。 大きな配列をループトンネル経由で渡すと、元の値が各反復の開始時に配列位置にコピーされるため、負荷が大きくなる可能性があります。シフトレジスタでは、このコピー操作が実行されません。データ値を変更しない場合は、左シフトレジスタを右シフトレジスタに配線する必要があります。以下の図は、異なる実装を比較しています。
数値変換
浮動小数点操作ではなく整数操作を行ってください。 プロセッサに浮動小数点ユニットがない場合、浮動小数点に変換して処理を行い、再度整数データタイプに戻す操作には、大きな負荷がかかる可能性があります。下記の図は、「商と余り」関数が通常の「商」関数より速く実行され、「ビットシフト」関数が「2の累乗でスケール」関数より速く実行されることを示しています。

自動数値変換は行わないでください。 コード性能を高めるもう1つの方法として、指定なしタイプ変換 (強制ドット) をすべて削除する方法があります。「変換」関数を使用して、データタイプを明示的に変換します。これにより、コピー操作およびデータタイプの確定が回避されます。以下の図は、異なる実装を比較しています。
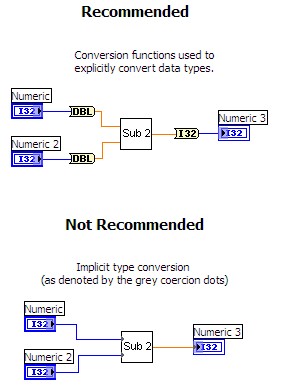
使用すべきでない関数とデータタイプ
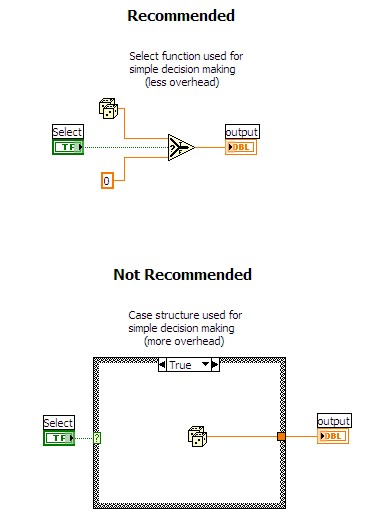
簡単な意思決定にケースストラクチャは使用しないでください。 LabVIEWで簡単な意思決定を行う際は、多くの場合、ケースストラクチャでなく「選択」関数を使用した方が時間を短縮できます。ケースストラクチャの各ケースにはそれぞれ独自のブロックダイアグラムが含まれているため、「選択」関数と比較すると、はるかに多くのオーバーヘッドを伴います。ただし、1つのケースで大量のコードを実行し、もう1つのケースではわずかなコードしか実行しない場合は、ケースストラクチャを使用した方がよいこともあります。「選択」関数を使うかケースストラクチャを使うかは、状況に応じて判断する必要があります。以下の図は、異なる実装を比較しています。
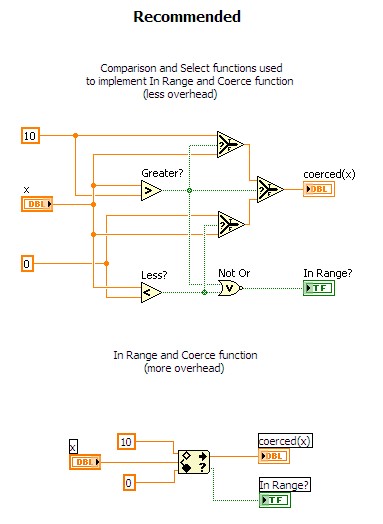
タイムクリティカルなコードでは、「範囲内と強制」関数を使用しないでください。 「範囲内と強制」関数は、ユーザによる構成が可能な特殊機能の使用や余分なデータタイプ確定処理のために、かなりのオーバーヘッドを伴います。この関数は、タイムクリティカルなコードで使用する場合は、「比較」関数と「選択」関数を使って再実装する必要があります。以下の図は、異なる実装を比較しています。
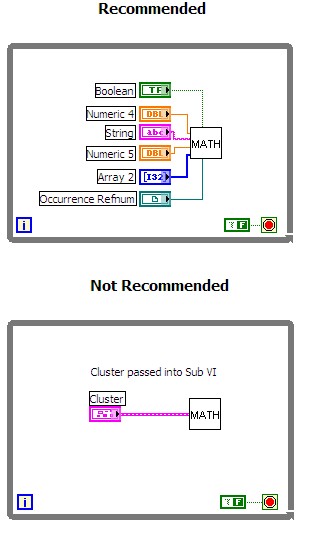
タイムクリティカルなコードでは、クラスタを使用しないでください。 クラスタがサブVIに渡される際、不要なデータタイプ情報も同時に渡されます。コードの実行速度を高めるには、ブロックダイアグラムのタイムクリティカルな領域でクラスタを使用しないようにしてください。以下の図は、異なる実装を比較しています。
インラインCノードの使用方法
LabVIEWとC言語のハイブリッドコードを使用することで、最もよい結果が得られる可能性があります。インラインCノードとライブラリ関数呼び出しノードを使用すると、CコードをLabVIEWブロックダイアグラム内で直接使用できるようになります。インラインCノードおよびライブラリ関数呼び出しノードの詳細については、LabVIEWヘルプ (下記リンク) を参照してください。
LabVIEWコード内でCベースのアルゴリズムを使用するのに最も適しているのは、以下のような場合です。
1) 既存のCアルゴリズムを再利用する。
2) Cコードに適した小さな数値/配列アルゴリズムがある。
最適なビルド設定
コードは通常、以下のビルド設定を使用すると最速で実行されます。
| ビルド設定 | 目的 |
|---|---|
| シリアルのみを生成 = TRUE | コードの並行処理の性能を高めます。 |
| デバッグ情報を生成 = FALSE | 呼び出しを削除してコードをデバッグします。 |
| ガードコードを生成 = FALSE | 数式処理/配列ルーチンから余分な保護コードを 削除します。 |
| 整数のみを生成 = TRUE | 浮動小数点ユニットのないターゲットでの 性能を向上させます。 |
| スタック変数を使用 = TRUE | スタティックに割り当てられたメモリ位置ではなく、 スタックスペースを使用します。 |
| C関数呼び出しを生成 = TRUE | サブVIを呼び出す際により効率的なコードを生成します。 ただし、すべての入力をすべてのサブVIに配線する必要があります。 |
まとめ
優れた組み込みプログラミング手法を実践すると、組み込みアプリケーションの制約に対応した最適なコードを作成することができます。これらのテクニックの1つか2つを実行するだけでもアプリケーションの性能は著しく向上するかもしれません。ただし、これらすべてのテクニックを組み合わせて使用すれば、さらに良い結果を得ることができます。