NI LabVIEWコンパイラ:内部
概要
内容
このホワイトペーパーでは、LabVIEWコンパイラについて紹介し、1986年のLabVIEW 1.0に始まる進化の概要を説明するとともに、現在の形式について解説します。さらに、最近行われた改善やそれらの機能がLabVIEWアーキテクチャやユーザにもたらすメリットについても紹介します。
コンパイラとインタプリタ
通常のG開発では明確なコンパイルステップがないので意外かもしれませんが、LabVIEWはコンパイラ言語です。LabVIEWでは、VIに変更を加えて「実行」ボタンをクリックすれば、実行することができます。コンパイラの場合、作成したGコードはネイティブのマシンコードに変換され、ホストコンピュータによって直接実行されます。コンパイラ言語に代わるものがインタプリタ言語です。インタプリタ言語では、コンピュータが直接プログラムを実行せず、別のソフトウェアプログラム (インタプリタ) が間接的にプログラムを実行します。
LabVIEW言語については、コンパイルや解釈を必要とするものはありません。実際、LabVIEWの最初のバージョンでは、インタプリタ言語を採用していました。後のバージョンで、VIのランタイム性能を高めるため、コンパイラに切り替わりました。これは、インタプリタ言語と比較したコンパイラ言語の一般的な差別化要因です。インタプリタの作成と管理は簡単ですが、ランタイム性能の低下を伴います。コンパイラは実装はより複雑ですが、高速での実行が可能です。LabVIEWコンパイラの主なメリットとしては、ソースコードに変更を加えなくても、コンパイラの改善で実行速度を向上させることができる点があります。実際に、LabVIEW 2010で重視した改善点は、コンパイラ内部の最適化によるVI実行速度の向上です。
LabVIEWコンパイラの歴史
現在のコンパイラについて詳しい説明に入る前に、初期から最新まで20年以上に及ぶコンパイラの発展について概略を紹介します。タイプ伝搬、クランプ、配置など、ここで紹介するアルゴリズムのいくつかは、現在のLabVIEWコンパイラのセクションで詳しく説明します。
LabVIEW 1.0は、1986年にリリースされました。すでに述べたとおり、LabVIEWの最初のバージョンではインタプリタを使用し、Motorola 68000のみに実装が可能でした。当時のLabVIEW言語は非常にシンプルだったため、コンパイラ (当時のインタプリタ) の要件も少ないものでした。たとえば、多態性はなく、拡張精度の浮動小数点数が唯一の数値タイプでした。LabVIEW 1.1では、配置アルゴリズム、「Inplacer」が加わりました。 このアルゴリズムは、実行時に再利用できるデータの割り当てを特定します。それにより不要なデータのコピーを防ぐことができ、その結果実行性能を大きく向上させることができます。
LabVIEW 2.0で、インタプリタから本当のコンパイラに切り替わりました。依然として実装対象はMotorola 68000のみでしたが、ネイティブのマシンコードが生成可能となりました。バージョン2.0で追加されたもう1つの機能として、データ型伝搬アルゴリズムがあります。データ型伝搬アルゴリズムが行う処理には、LabVIEW言語の構文チェックやタイプの解決などがあります。さらにLabVIEW 2.0の大きな改善点として、クラスタ化技術の導入がありました。クラスタ化アルゴリズムは、LabVIEWダイアグラム内で並列性を識別し、ノードを並列で実行可能な「クラスタ」に分割します。データ型伝搬、インプレース、クラスタ化などのアルゴリズムは、その後のLabVIEWでも重要コンポーネントとして多くの漸進な改善が行われてきました。LabVIEW 2.5では、新しいコンパイル環境が導入され、複数のプラットフォーム、具体的にはIntel x86とSparcがサポートされました。また、LabVIEW 2.5ではVI間の依存性を管理して、再コンパイルが必要なタイミングを追跡するリンカが追加されました。
2つの新しいプラットフォーム、PowerPCとHP PA-RISCが定数畳み込み機能とともに追加されたのは、LabVIEW 3.1です。LabVIEW 5.0と6.0では、コード生成器が改良され、複数のプラットフォームへの共通インタフェース、GenAPIが追加されました。GenAPIはクロスコンパイルが可能です。これは、リアルタイム開発では重要な機能です。通常リアルタイム開発ではホストPC上でVIを作成し、それをリアルタイムターゲットに実装 (コンパイル) します。さらに、限定的な形式のループ不変式削除も導入されました。最後に、LabVIEWマルチタスク実行システムが拡張され、複数のスレッドがサポートされました。
LabVIEW 8.0では、バージョン5.0で導入されたGenAPIインフラストラクチャに基づき、レジスタ割り当てアルゴリズムが追加されました。GenAPIが登場する以前は、レジスタは各ノードに対し生成されたコード内でハードコード化されていました。限定的な形式の到達不能コードとデッドコードの削除機能も追加されました。LabVIEW 2009では、64ビットLabVIEWとDFIR (データフロー中間表現) が導入されました。このDFIRを使用して、ループ不変式削除、定数畳み込み、デッドコードや到達不能コードの除去などの機能がさらに高度化されました。並列Forループなど、2009年に新たにリリースされた言語機能は、DFIRに基づいて構築されています。
LabVIEW 2010では、代数的処理、共通式削除、ループ展開、サブVIのインラインなど、新しいコンパイラの最適化が行われています。またこの最新版では、LLVM (Low-Level Virtual Machine) がLabVIEWコンパイラチェーンに採用されています。LLVMは、業界で広く使用されているオープンソースのコンパイル環境です。LLVMにより、命令のスケジューリング、ループと条件文の入れ替え、命令合成、条件付き伝搬、さらに高度なレジスタアロケータなど、さらなる最適化が追加されています。
現在のコンパイルプロセス
LabVIEWコンパイラの歴史について概要を紹介した後は、現在のLabVIEWにおけるコンパイルプロセスについて解説します。まずさまざまなコンパイルステップについて大まかに説明し、次にそれぞれについて詳しく紹介します。
VIのコンパイルの最初のステップは、データ型伝搬アルゴリズムです。この複雑なステップでは、端子の型解決をしたり、構文エラーを検出したりします。Gプログラミング言語で発生しうる全ての構文エラーは、データ型伝搬アルゴリズムで検出されます。アルゴリズムによってVIが有効と判断されたら、コンパイルを続行します。
データ型伝搬が終わったら、VIはブロックダイアグラムエディタで使用されるモデルから、コンパイラで使用されるDFIRに変換されます。DFIRに変換されたら、コンパイラはDFIRグラフ上で複数の変換を実行して分解し、最適化して、コード生成ができる状態にします。置換処理やクラスタ化など、多くのコンパイラ最適化は変換として実装されこのステップで実行されます。
DFIRグラフの最適化と簡素化の後は、LLVM中間表現に変換されます。一連のLLVMパスが中間表現上で実行され、最適化して最終的にマシンコードに変換します。
タイプ伝搬
上述のとおり、タイプ伝搬アルゴリズムはタイプ解決し、プログラミングのエラーを検出します。実際に、このアルゴリズムには下記のような複数の機能があります。
- 端子に接続されるデータ型の解決
- サブVIの呼び出しおよび有効性の確認
- ワイヤ方向の計算
- VI内のサイクルのチェック
- 構文エラーの検出とレポート生成
このアルゴリズムは、ユーザがVIに変更を加える度に実行して、VIが有効かどうかを判断します。そのためこのステップが「コンパイル」プロセスの一部であるかどうかは議論の余地があります。ただしこのステップは、LabVIEWコンパイルチェーンの中で、明らかに従来のコンパイルにおける字句解析、構文解析、または意味解析に相当するステップです。
タイプに適応する端子の簡単な例が、LabVIEWの加算プリミティブです。2つの整数を足すと整数になりますが、2つの浮動小数点数を足すと浮動小数点数になります。同様のパターンは、配列やクラスタなどの複合タイプでも見られます。シフトレジスタのような他の言語構造には、さらに複雑なタイプ規則を持つものもあります。加算プリミティブの場合、出力タイプは入力タイプによって決まり、タイプはダイアグラム内を「伝搬」されるとしているため、このような名前のアルゴリズムになっています。
この加算プリミティブの例は、タイプ伝搬アルゴリズムの構文チェック機能も示しています。整数と文字列を加算プリミティブに配線するとします。この場合、2つの値を加算することは意味がないため、タイプ伝搬アルゴリズムはエラーを報告し、VIが不良であるとして実行ボタンに壊れた矢印を表示します。
中間表現 ― 解説とメリット
タイプ伝搬によりVIが有効とされたら、コンパイルは続行しVIはDFIRに変換されます。DFIRの詳細を説明する前に、ここで中間表現 (IR) について考えてみます。
IRとは、コンパイルのさまざまな段階において処理が進められるユーザのプログラムを表現したものです。IRという表記はコンパイラの用語として一般的に使われており、あらゆるプログラミング言語に適用できます。
いくつかの例について考えてみます。よく使用されるIRにはさまざまなものがあります。ここでは抽象構文ツリー (AST) と3番地コードという2つの一般的な例を紹介します。
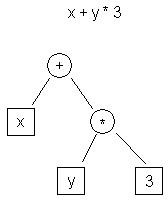 | t0 <- y t1 <- 3 t2 <- t0 * t1 t3 <- x t4 <- t3 + t2 |
| 図1.AST IRの例 | 表1.3番地コードIRの例 |
図1は、“x + y * 3”という式をASTで表したものです。表1は、同じ式を3番地コードで表したものです。
この2つの表現で明らかに異なるのは、ASTの方がはるかに高レベルであるという点です。プログラムのターゲット表現 (マシンコード) よりもソース表現 (C) に近いことがわかります。一方3番地コードは、低レベルでアセンブリ言語に似ています。
高レベル表現も低レベル表現も、それぞれメリットがあります。例えば依存性分析は、3番地コードのような低レベル表現より、ASTのような高レベル表現の方が簡単かもしれません。ただしレジスタ割り当てや命令のスケジューリングといった最適化は、通常3番地コードのような低レベル表現で行います。
IRにはそれぞれメリットとデメリットがあるため、多くのコンパイラ (LabVIEWを含む) は複数のIRを使用します。LabVIEWの場合、DFIRは高レベルIR、LLVM IRは低レベルIRとして使用されています。
DFIR
LabVIEWでは、高レベル表現として、階層型でグラフを利用し、Gコードに似たDFIRを使用します。Gと同様、DFIRもさまざまなノードから構成され、それぞれに端子が付いています。端子は、別の端子に配線することができます。ループなど一部のノードにはダイアグラムを含めることができ、そのダイアグラムにもノードを含めることができます。
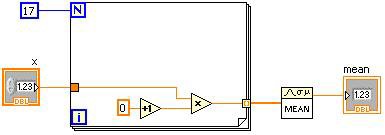
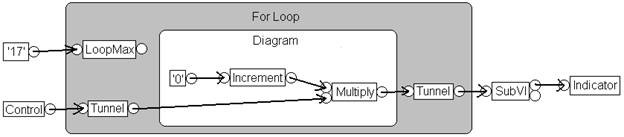
図2.LabVIEWのGコードと対応するDFIRグラフ
図2は、シンプルなVIを初期のDFIR表現とともに示ししたものです。このVIのDFIRグラフを最初に作成した際、VIはGコードを直接変換したものでした。DFIRグラフのノードは、一般にGコードのノードと一対一の対応関係にあります。コンパイルが進むと、DFIRノードは移動または分割されるか、あるいは新しいDFIRノードが配置されます。DFIRの主なメリットの1つに、Gコードに特有の並列性といった特性を持ち合わせている点があります。並列性を3番地コードで表すと、はるかに理解しづらいものとなります。
DFIRを使用すると、LabVIEWコンパイラにとって2つの大きな利点があります。1つ目として、DFIRはVIのコンパイラ表現からエディタを切り離します。2つ目は、DFIRは複数のフロントエンドとバックエンドを持つコンパイラの共通ハブとして機能するという点です。これらの利点についてそれぞれ詳しく説明します。
DFIRグラフによるコンパイラ表現からのエディタ切り離し
DFIRが登場する以前、LabVIEWではエディタとコンパイラの両方で同じVI表現を使用していました。その方法ではコンパイルプロセスの途中で表現を修正することができなかったため、コンパイラを最適化することは困難でした。

図3.DFIRはコンパイラがコードを最適化する仕組みになっている
図3は、上述のVIのDFIRグラフを示しています。このグラフは、コンパイラプロセスで数回の変換により分解と最適化が行われた後の状態を示しています。図からわかるように、このグラフは上記のグラフとはかなり違っています。例:
- 分解変換により制御器、表示器、サブVIノードが削除され、UIAccessor、UIUpdater、FunctionResolver、FunctionCallという新しいノードに置き換えられます。
- ループ不変式削除により、増分ノードと乗算ノードはループ外に移動しています。
- クラスタ化によりYieldIfNeededノードがForループ内に配置されています。そのため実行中のスレッドが他の競合するタスクと実行を共有するようになります。
変換については、後のセクションで詳しく説明します。
DFIR IRは複数のコンパイラのフロントエンドとバックエンドの共通ハブとして機能する
LabVIEWは複数の異なるターゲットと互換性があります。そのうちのいくつかは、たとえばx86デスクトップPCとXilinx FPGAのように、大きな違いがあります。同様に、LabVIEWでは演算モデルも複数あります。LabVIEWでは、G言語を使用したグラフィカルプログラミングだけでなく、たとえばMathScriptでテキストベースの数式処理を行うこともできます。そのためフロントエンドとバックエンドが複数存在し、その全てをLabVIEWコンパイラで処理することになります。全てのフロントエンドが生成し全てのバックエンドが消費する共通のIRとしてDFIRを使用することで、さまざまな組み合わせでの再利用が容易になります。たとえば、DFIRグラフ上で実行する定数畳み込み最適化は、一度作成すれば、デスクトップ、リアルタイム、FPGA、組込の各種ターゲットに実装することができます。
DFIRの分解
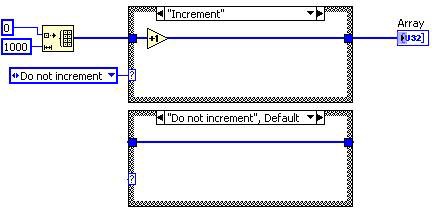
DFIRでは、VIはまず一連の分解変換を実行します。分解変換の目的は、DFIRグラフを縮小または正規化することです。たとえば、配線されていない出力トンネルの分解により、ケースストラクチャまたはイベントストラクチャの配線されていない出力トンネルが検出され、「配線されていない場合、デフォルトを使用」するように構成されます。 それらの端子については、デフォルト値の定数を端子に配線しますので、「配線されていない場合、デフォルトを使用」する動作がDFIRグラフで明示的になります。後続のコンパイラパスは、全ての端子を同一に処理し、全て配線された入力があると仮定します。この場合、この言語の「配線されていない場合、デフォルトを使用」機能は、表現をより基本的な形式に縮小することで、コンパイルにより取り除かれたことになります。
この考え方は、より複雑な言語機能にも適用できます。たとえば、分解変換を使用して、フィードバックノードをWhileループのシフトレジスタに縮小することができます。別の分解では、並列Forループを、一部ロジックを追加した複数の逐次Forループとして実装して、逐次ループで入力を並列化可能な部分に分解し後でまた戻します。
LabVIEW 2010の新機能であるサブVIインライン化も、DFIR分解として組み込まれています。コンパイルのこの段階では、サブVIの“inline”と印の付いたDFIFグラフは、発呼者のDFIRグラフに直接配置されます。サブVI呼び出しのオーバーヘッドを回避するため、インライン化により発呼者と被発呼者を1つのDFIRグラフに結合することで、さらなる最適化を行います。例として、vi.libから空白文字を削除.viを呼び出すシンプルなVIについて見てみます。
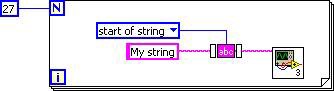
図4.DFIR最適化を行うシンプルなVIサンプル
空白文字を削除.viは、vi.libで下記のように定義されています。
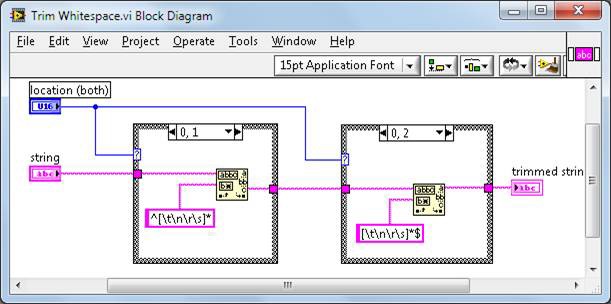
図5.空白文字を削除.viのブロックダイアグラム
サブVIは発呼者にインラインするため、下記のGコードに相当するDFIRグラフとなります。
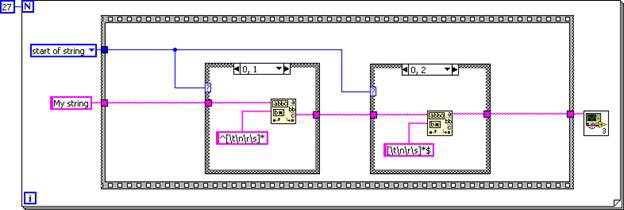
図6.インラインされた空白文字を削除.viのDFIRグラフに相当するGコード
サブVIのダイアグラムが発呼者のダイアグラムにインラインされたので、到達不能コードとデッドコードの除去によりコードを簡素化することができます。常に最初のケースストラクチャが実行し、2つ目のケースストラクチャは一切実行されません。
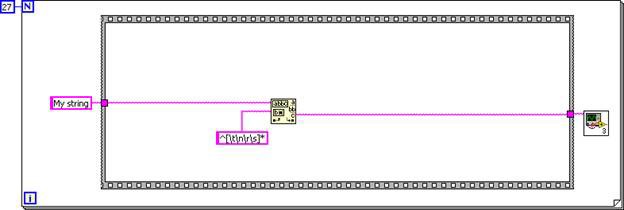
図7.入力ロジックが一定なのでケースストラクチャは削除可能
同様に、ループ不変式削除は、マッチパターン関数をループ外に移動します。最終的なDFIRグラフは、下記のGコードに相当します。
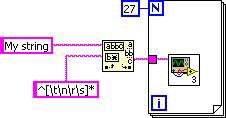
図8.最終的なDFIRグラフに相当するGコード
LabVIEW 2010では空白文字を削除.viがデフォルトでインラインとして扱われますので、このVIのクライアントは全てこのようなメリットを受けることができます。
DFIR最適化
DFIRグラフが完全に分解されると、DFIR最適化パスが開始します。LLVMコンパイル時にも、さらに最適化が行われます。このセクションでは、多くの最適化のうちの一部を紹介します。それぞれの変換はLabVIEWに限らず一般的なコンパイラ最適化と同様であるため、特定の最適化に関する詳細情報を簡単に見つけることができます。
到達不能コードの除去
実行されないコードのことを到達不能コードといいます。到達不能コードを削除しても実行時間が大幅に短縮されるわけではありませんが、一度削除しておけば、それ以降のコンパイルパスで再度走査されないため、コードが小さくなり、コンパイル時間が短縮されます。
到達不能コードの除去前

到達不能コードの除去後
図9.DFIR到達不可能コード除去による分解に相当するGコード
この場合、ケースストラクチャの「増分」ダイアグラムは実行されないため、変換によってそのケースが削除されます。ケースストラクチャにはケースが1つしか残っていないため、シーケンスストラクチャに置き換えられます。デッドコードの除去により、後でフレームと列挙定数が削除されます。
ループ不変式削除
ループ不変式削除は、ループの本体内部にあるコードのうち、外に移動させても支障のない部分を特定し移動させます。移動されたコードは実行される回数が少なくなるため、全体の実行速度が向上します。
ループ不変式削除 変換前 | ループ不変式削除 変換後 |
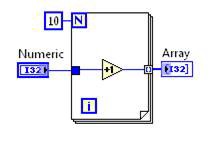
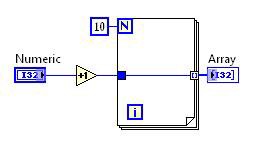
図10.DFIRループ不変式削除による分解に相当するGコード
ここでは、増分操作がループの外に移動されます。配列を作成できるようループの本体はそのままになっていますが、各反復で計算を繰り返す必要はありません。
共通式の除去
共通式の除去により、計算の繰り返しを特定し、計算を1回のみ実行して、結果を再利用します。
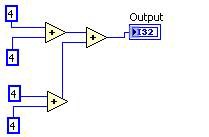
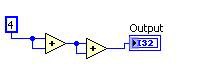
実行前 実行後
図11.DFIR共通式の除去による分解に相当するGコード
定数の畳み込み
定数畳み込みでは、コンパイル時に定数であるダイアグラムの部分を識別するため、早期に単純化することができます。
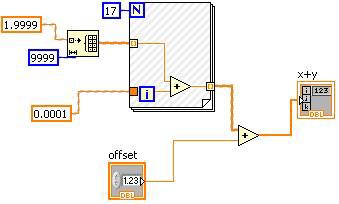
図12.定数の畳み込みをLabVIEWブロックダイアグラムで可視化する
図12のVIの斜線部は定数の畳み込みの部分を示します。この場合、「offset」制御器は定数畳み込みができませんが、Forループなどプラスプリミティブの他のオペランドは定数値になります。
ループの展開
ループの展開では、生成コードでループ本体を複数回繰り返し、ループの合計反復数を同じ係数で減らし、ループのオーバーヘッドを取り除くことができます。これにより、ループのオーバーヘッドが減少し、実行速度が最適化されますが、コードのサイズは大きくなります。
デッドコードの除去
デッドコードとは、必要のないコードのことです。デッドコードを取り除くことで、そのコードは実行されなくなるため実行時間を短縮できます。
デッドコードが発生するのは、一般にユーザが直接作成していない変換によるDFIRグラフの操作が原因です。以下の例について検証します。到達不能コードの除去を行うことで、ケースストラクチャを削除できることがわかります。これによりデッドコードができますので、デッドコード除去変換により削除します。
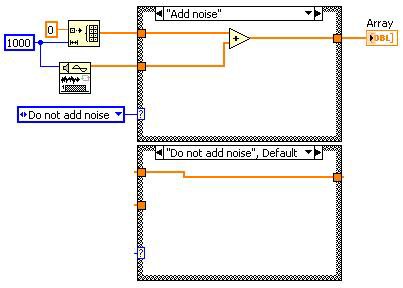
前
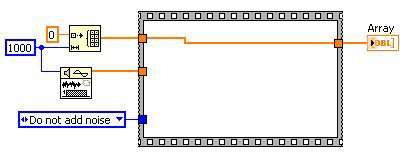
到達不能コードの除去後
デッドコードの除去後
図13.デッドコードの除去により走査するコード量を減らすことが可能
このセクションで紹介した変換の多くは上記のような関係性があり、1つの変換を行うと他の変換の実行が可能になることがあります。
DFIRバックエンド変換
DFIRグラフの分解と最適化が終わったら、いくつかのバックエンド変換が行われます。それらの変換では、最終的にDFIRグラフをLLVM中間表現に変換する準備として、DFIRグラフを評価し注釈を付けます。
クラスタ化
クラスタ化アルゴリズムは、DFIRグラフ内で並列性を識別し、ノードを並列で実行可能なクラスタに分割します。このアルゴリズムは、マルチスレッド協調型マルチタスクを使用するLabVIEWのランタイム実行システムと密接な関係があります。クラスタ化で生成する各クラスタ箇所は、実行システムで個別のタスクとしてスケジューリングされています。クラスタ箇所内のノードは、固定された順番に実行されます。各クラスタの実行順が予め決められていることで、置換処理がデータ割り当てを共有し、性能を劇的に高めることができます。また、クラスタはその他にも、ループやI/Oなどの長い操作にyield処理を挿入して、他のクランプと協調的にマルチタスクを実行できるようにします。
置換処理
置換処理は、DFIRグラフを解析し、データの再利用やコピー作成の判断をします。LabVIEWのワイヤは、シンプルな32ビットスカラまたは32 MB配列のいずれかです。データの再利用は、LabVIEWのようなデータフロー言語では重要なことです。
下記の例について考えてみます (最高のパフォーマンスとメモリ使用量を実現するために、VIのデバッグは無効になっていることに注意してください)。
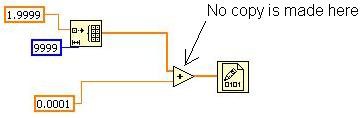
図14.置換処理アルゴリズムを実行する簡易例
このVIは、配列を初期化し、各要素にスカラ値を追加して、その値をバイナリファイルに書き込みます。配列のコピーはいくつ必要でしょうか。LabVIEWは、最初に配列を用意しますが、加算演算の際、その配列を置き換える形で結果を格納します。そのため配列のコピーは1つで済みます。各ワイヤに1つの配列を割り当てる必要はありません。配列が大きければ、メモリ消費量と実行時間の両方で大きな違いが出ます。このVIでは、加算演算のプロセスに置換処理が適用されています。
作成したVIでこの動作を検証するには、ツール→プロファイルにある「バッファ割り当てを表示」ツールを使用します。このツールでは、加算プリミティブにメモリ割り当てが表示されません。つまりデータのコピーは作成されず、加算操作が置換処理で実行されたことを示します。
これが可能なのは、他のどのノードも元の配列を必要としないからです。VIを図15に示すように変更すると、置換処理では加算プリミティブで配列のコピーが必要になります。これは、2つ目のバイナリファイルに書き込むプリミティブが元の配列を必要としており、最初のバイナリファイルに書き込むプリミティブの後に実行する必要があるためです。この変更を行うことで、「バッファ割り当てを表示」ツールは加算プリミティブに割り当てを表示します。
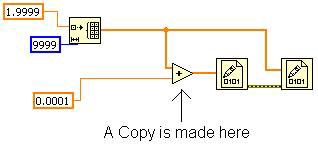
図15.元の配列のワイヤを分岐すると、メモリにコピーが作成される
アロケータ
置換処理により他のノードとメモリ位置を共有できるノードが特定されたら、アロケータが動作し、必要となる“メモリ割り当て”が用意されます。これは、各ノードおよび端子にアクセスすることで実装されます。他の端子に対し置換処理された端子は、新たな割り当てを作成せず割り当てを再利用します。
コード生成器
コード生成器とは、DFIRグラフをターゲットプロセッサ用の実行可能なマシン命令に変換するコンパイラのコンポーネントです。LabVIEWはDFIRグラフの各ノードをデータフロー順で実行し、各ノードはGenAPIというインタフェースに読み込まれます。GenAPIは、DFIRグラフをそのノードの機能を記述する逐次中間言語 (IL) に変換するのに使用されます。この中間言語 (IL) は、プラットフォームに依存しない方法でノードの低レベル動作を記述します。ILのさまざまな命令により、演算、メモリへの読み書き、比較や条件分岐の実行などを行います。IL命令は、メモリ上か、あるいは中間値の保存に使用する仮想レジスタに含まれる値上で実行できます。IL命令の例としては、GenAdd、GenMul、GenIf、GenLabel、GenMoveなどがあります。
LabVIEW 2009以前のバージョンでは、このIL形式をターゲットプラットフォーム用のマシン命令 (80X86、PowerPCなど) に直接変換していました。LabVIEWではシンプルなワンパスレジスタアロケータを使用して、仮想レジスタを実際のマシンレジスタにマッピングし、各IL命令はハードコードされた特定のマシン命令を発して、各ターゲットプラットフォームに実装します。それは極めて高速ですが、コードの改善の余地があり、最適化には適していませんでした。プラットフォームに依存しない高レベル表現であるDFIRは、サポートできるコード変換の種類が限られています。最新の最適化コンパイラでコード最適化の完全なセットのサポートを追加するために、LabVIEWは最近、LLVMと呼ばれるサードパーティのオープンソース技術を採用しました。
LLVM
LLVM (Low-Level Virtual Machine) とは、イリノイ大学の研究プロジェクトとして開発された多用途の高性能オープンソースコンパイラフレームワークです。柔軟性に優れたわかりやすいAPIと非制限的ライセンスを採用しているため、学術界と産業界の両方で広く利用されるようになっています。
LabVIEW 2010では、LabVIEWコード生成器のリファクタリングを行い、ターゲットマシンコードを生成するためLLVMを採用しました。既存のLabVIEW IL表現を活用したので、LabVIEWでは多数のDFIRノードやプリミティブがサポートされているにもかかわらず、約80種類のIL命令を作成し直しただけですみました。
VIのDFIRグラフからのILコードのストリーミングを作成したら、LabVIEWは各IL命令にアクセスし、相当するLLVMアセンブリ表現を作成します。それによりさまざまな最適化パスが呼び出され、次にLLVMジャストインタイム (JIT) フレームワークを使用して、実行可能なマシン命令がメモリ内に作成されます。LLVMのマシン再配置情報はLabVIEW表現に変換されますので、VIをディスクに保存して別のメモリベースアドレスにリロードすると、正しく修復し新しい配置で実行することが可能です。
LabVIEWがLLVMを使用して実行する標準のコンパイラ最適化には、以下のようなものがあります。
- 命令合成
- 分岐スレッディング
- 集合のスカラ置換
- 条件付き伝搬
- 末尾再帰除去
- 式の再結合
- ループ不変式削除
- ループと条件文の入れ替えやインデックス分割
- 帰納変数の簡略化
- ループの展開
- グローバル変数番号付け
- デッドコードの除去
- 積極的デッドコード除去
- 定数伝播
これらの最適化の詳細については、このホワイトペーパーでは説明しませんが、コンパイラに関する教材やインターネットで多くの情報を得ることができます。
社内ベンチマークでは、LLVMの導入によりVIの実行時間が平均20%短縮されたことが示されています。個々の結果はVIが実行する演算の種類により異なります。VIによってはその結果より大きな改善が見られるものもありますし、性能に全く変化がないものもあります。たとえば、上級解析ライブラリを使用するVIや、最適化されたC言語で実装済みのコードに強く依存するVIでは、性能にほとんど変化はありません。LabVIEW 2010は、LLVMを導入した最初のバージョンであり、今後のバージョンでさらなる改良を予定しています。
DFIRとLLVMをともに活用
ループ不変式削除やデッドコード除去など、一部の最適化がDFIRで実行されていることはすでに紹介しました。実際に、一部の最適化パスはコンパイラの異なるレベルで複数回実行するのが有益です。それは、一部の最適化パスでは別の最適化が行えるように、コードを変換している場合があるからです。DFIRは高レベルIRでLLVMは低レベルIRであり、これら2つのIRをともに活用することで、コード実行用のプロセッサアーキテクチャ向けに作成したLabVIEWコードを最適化することが可能となります。