LabVIEW シェア変数の使用
概要
LabVIEWでは、分散アプリケーションを作成するためのさまざまなテクノロジーが採用されています。シェア変数により、そのようなアプリケーションに必要なプログラミングが簡素化されます。ここでは、シェア変数とはどのようなものか、また、その機能やパフォーマンスについて説明します。
シェア変数を使用すると、1つのダイアグラム上にあるループ間またはネットワーク上のVI間でデータを共有できます。UDP/TCP、LabVIEWキュー、Real-Time FIFOといった他の数多くのLabVIEWデータ共有方法とは異なり、シェア変数は通常、編集時にプロパティダイアログを使用して構成します。そのため、アプリケーションに構成コードを含める必要がありません。
シェア変数には、単一プロセスとネットワークで共有の2種類があります。このドキュメントでは、単一プロセスシェア変数とネットワーク共有シェア変数について説明します。
内容
シェア変数を作成する
シェア変数を作成するには、LabVIEWプロジェクトを開く必要があります。プロジェクトエクスプローラで、ターゲット (プロジェクトライブラリ) またはプロジェクトライブラリ内のフォルダを右クリックして、ショートカットメニューから新規→変数を選択し、シェア変数プロパティダイアログボックスを表示します。シェア変数構成オプションを選択して、OKボタンをクリックします。
プロジェクトライブラリにないターゲットまたはフォルダを右クリックし、ショートカットメニューから新規→変数を選択してシェア変数を作成した場合は、新規のプロジェクトライブラリが作成され、そのライブラリにシェア変数が配置されます。変数とライブラリについては、「シェア変数の寿命」セクションを参照してください。
図1では、シェア変数プロパティダイアログボックスで単一プロセスシェア変数を設定しています。LabVIEW Real-TimeモジュールとLabVIEW Datalogging and Supervisory Control (DSC: データロギング/監視制御) モジュールを使用することにより、シェア変数の機能がさらに向上し、プロパティの構成が可能になります。この例では、LabVIEW Real-TimeモジュールとLabVIEW DSCモジュールの両方がインストールされていますが、LabVIEW DSCモジュールで追加される機能はネットワーク共有シェア変数のみに対して使用できます。
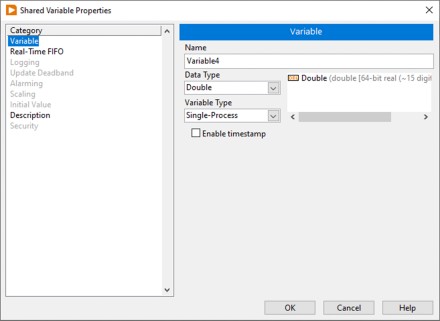
図1.単一プロセスシェア変数プロパティ
データタイプ
新しいシェア変数は、多くの標準データタイプの中から選択できます。これらの標準データタイプのほかに、データタイプからカスタム制御器から...を選択してカスタム制御器にアクセスすると、カスタムデータタイプを指定することもできます。ただし、スケールやReal-Time FIFOなどの一部の機能は、カスタムデータタイプによっては機能しない場合があります。 また、LabVIEW DSCモジュールがインストールされている場合、カスタムデータタイプの使用時には警告は不正状態の通知のみに限られます。
シェア変数プロパティの構成後、OKボタンをクリックすると、図2に示すようにプロジェクトエクスプローラウィンドウでライブラリまたは選択したターゲットの下にシェア変数が表示されます。
図2.プロジェクトの下に表示されたシェア変数
シェア変数が属するターゲットは、LabVIEWがシェア変数をデプロイおよびホストするターゲットです。シェア変数のデプロイとホスティングについては、「デプロイとホスティング」セクションを参照してください。
変数リファレンス
シェア変数をLabVIEWプロジェクトに追加すると、図3に示すように、そのシェア変数をVIのブロックダイアグラムにドラッグして読み取りや書き込みを行うことができます。ブロックダイアグラムでの読み取りおよび書き込みのノードは、シェア変数ノードと呼ばれます。
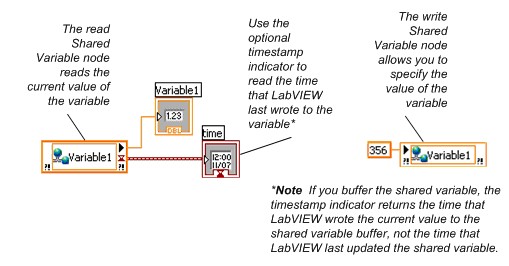
図3.シェア変数ノードを使用したシェア変数の読み取りおよび書き込み
ノードをどのように変数に接続するかによって、シェア変数ノードを絶対またはターゲット相対に設定することができます。絶対シェア変数ノードは変数を作成したターゲットにあるシェア変数に接続します。ターゲット相対シェア変数ノードは常にノードを含むVIを実行するターゲット上のシェア変数に接続します。
ターゲット相対シェア変数ノードを含むVIを新規ターゲットに移動する場合、シェア変数も新規ターゲットに移動する必要があります。VIおよび変数を他のターゲットに移動する可能性がある場合は、ターゲット相対シェア変数ノードを使用してください。
シェア変数ノードはデフォルトで絶対シェア変数ノードです。シェア変数ノードとシェア変数の接続方法を変更する場合は、ノードを右クリックして、リファレンスモード→ターゲット相対またはリファレンスモード→絶対を選択します。
プロジェクトエクスプローラウィンドウ内のシェア変数を右クリックすると、いつでもシェア変数プロパティを編集することができます。LabVIEWプロジェクトによって、新しい設定がメモリ内のすべてのシェア変数リファレンスに反映されます。変数ライブラリを保存すると、変更はディスク上に保存されている変数定義にも適用されます。
単一プロセスシェア変数
単一プロセス変数を使用すると、同じVI上の並列ループなど、ワイヤで配線できない同一のVI内の異なる2点間で、または同じアプリケーションインスタンス内の異なる2つのVI間で、データ転送が行えます。単一プロセスシェア変数の実装方法は、LabVIEWグローバル変数に似ています。従来型グローバル変数と比較した単一プロセスシェア変数の主なメリットは、単一プロセスシェア変数を、ネットワーク上のどのノードでもアクセス可能なネットワーク共有シェア変数に変換できるという点です。
単一プロセスシェア変数とLabVIEW Real-Time
リアルタイムアプリケーションにおいて確定性を保持するには、非ブロックの確定的メカニズムを使用して、優先度の高いタイミングループやタイムクリティカルな優先度の高いVIなどのコードの確定的部分から非確定的部分へデータを転送する必要があります。LabVIEW Real-Timeモジュールをインストールする際に、シェア変数プロパティダイアログボックスでReal-Time FIFO機能を有効にすることで、Real-Time FIFOを使用するようシェア変数を構成できます。タイムタイムクリティカルなループと優先度の低いループ間でのデータ転送にはReal-Time FIFOを使用することを推奨します。単一プロセスシェア変数でReal-Time FIFOを有効にすると、低レベルのReal-Time FIFO VIを使用せずに済みます。
LabVIEWでは、VIが実行用に予約されている場合 (通常はアプリケーションのトップレベルVIが実行を開始する場合) にReal-Time FIFOが作成されるため、シェア変数ノードの最初の実行については特別な考慮は必要ありません。
メモ: 旧バージョンのLabVIEW (8.6より前のバージョン) では、シェア変数ノードがシェア変数からの書き込みまたは読み込みを最初に試みたときにReal-Time FIFOが作成されます。この動作が行われると、シェア変数を最初に使用したときの実行時間が、以降に使用した場合に比べて少し長くなります。非常に正確なタイミング制御が求められる場合には、タイムクリティカルループにおける初回の「ウォームアップ」反復を含めて呼び出し時間の変動に対応するか、タイムクリティカルループの外で少なくとも1回はその変数の読み取りを行います。
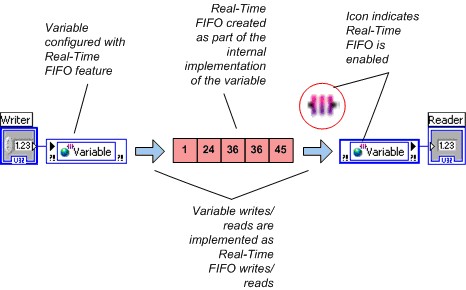
図4.Real-Time FIFO有効のシェア変数
LabVIEWでは、シェア変数に複数の書き込みまたは読み取りがある場合でも、それぞれの単一プロセスシェア変数に対して1つのReal-Time FIFOが作成されます。データの整合性を保持するため、複数の書き込みは複数の読み取りと同様に互いにブロックします。ただし、書き込みと読み取りの間では互いにブロックしません。NIでは、タイムクリティカルループで使用される単一プロセスシェア変数の複数書き込みまたは複数読み取りを避けることを推奨します。
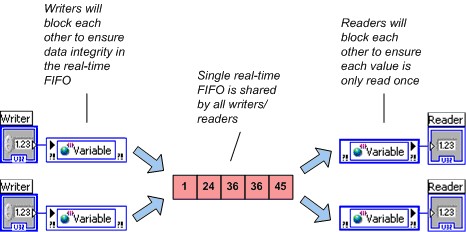
図5.単一FIFOを共有している複数書き込みと複数読み取り
Real-Time FIFOを有効にすると、単一の要素を持つバッファと複数の要素を持つバッファという、タイプが多少異なるFIFOが有効な2つの変数から選んで使用することができます。これら2つのバッファ間の違いの1つは、単一要素FIFOではオーバーフローやアンダーフローの警告が報告されないことです。もう1つの違いは、複数読み取りが空のバッファを読み取った場合にLabVIEWが返す値です。単一要素FIFOの複数読み取りは同じ値を受信し、単一要素FIFOは書き込みが再度変数を書き込むまで同じ値を返します。空のマルチ要素FIFOの複数読み取りは、それぞれバッファから読み取った最新の値、または変数から読み取ったことがない場合は変数のデータタイプのデフォルト値を取得します。この動作を以下に示します。
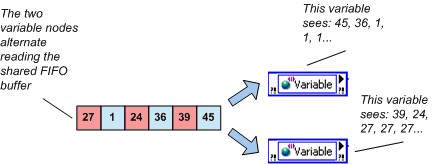
図6.最後に読み取られた動作およびマルチ要素Real-Time FIFOシェア変数
それぞれの読み取り側が複数の要素を持つFIFOのシェア変数に各データ点を書き込む必要のあるアプリケーションの場合は、読み取り側ごとに別々のシェア変数を使用してください。
ネットワーク共有シェア変数
ネットワーク共有シェア変数を使用すると、イーサネットネットワーク経由でシェア変数への読み書きが可能になります。ネットワークの実装は、ネットワーク共有シェア変数によってすべて処理されます。
ネットワーク共有シェア変数には、ネットワーク上でデータを使用可能にする機能のほか、単一プロセスシェア変数にはない多くの機能があります。それらの追加機能が搭載されているため、ネットワーク共有シェア変数の内部実装は単一プロセスシェア変数よりはるかに複雑となっています。以降のセクションでは、この実装の各部分について説明するとともに、ネットワーク共有シェア変数のパフォーマンスを最大限に引き出すための推奨事項についても解説します。
NI-PSP
NI Publish and Subscribe Protocol (NI-PSP) は、ネットワークシェア変数用に最適化されたネットワークプロトコルです。 NI-PSPの下にある一番低レベルのプロトコルはTCP/IPです。TCP/IPは、デスクトップシステムとNIのRTターゲット (下のベンチマーク比較を参照) の両方でパフォーマンスが向上するように調整されています。
LogosXTの動作理論
図7は、ネットワークシェア変数のソフトウェア階層を示しています。 この例の動作理論では、LogosXTと呼ばれる特別な階層があり、これを理解しておくことが重要です。 LogosXTは、シェア変数のスループット最適化を制御する層です。
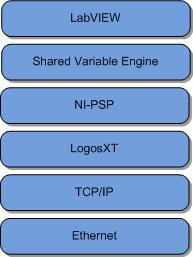
図7.シェア変数ネットワーク層
図8は、LogosXT伝送アルゴリズムの基本コンポーネントを示しています。 基本的に大変シンプルな構成です。 2つの重要な動作機構があります。
- 8キロバイト (KB) 転送バッファ
- 10ミリ秒 (ms) タイマスレッド
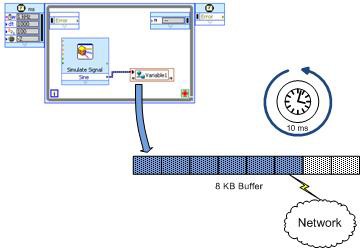
図8.LogosXTの動作機構。 バッファは、満杯になるか10 msが経過すると転送される
これらの数値は、データスループットを最適化するためにさまざまなパケットサイズや時間をプロファイルした結果です。 アルゴリズムは以下のとおりです。
- 転送バッファが10 msでタイムアウトする前にバッファの容量 (8KB) が満杯になった場合、そのバッファ内のデータは書き込みを開始した同じスレッド上のTCPに直ちに送信されます。 シェア変数の場合、このスレッドはシェア変数エンジンスレッドになります。
- バッファが満杯になる前に10 msが経過すると、データはタイマのスレッドに送信されます。
重要事項: 2つの各エンドポイント間においてすべての接続で使用される転送バッファは1つです。 つまり、2つの異なるマシン間で接続に相当するすべての変数が1つのバッファを共有することになります。 この転送バッファとシェア変数のバッファプロパティを混同しないようにしてください。 この転送バッファは低レベルのバッファで、複数の変数を1つのTCP接続に多重化し、ネットワークのスループットを最適化するものです。
ネットワーク階層でのこの層における機能を理解することが重要です。これはLabVIEWダイアグラムのコード上で副次的影響を与えるためです。 アルゴリズムで10 ms間待機している理由は、1回の送信動作でできるだけ多く送信する方がスループットの点で常に効率が良いからです。 あらゆるネットワーク動作には、時間とパケットサイズについて固定のオーバーヘッドが伴います。 合計Bバイトになる多数の小さいパケット (N個のパケット) を送信すると、ネットワークにN回オーバーヘッドが生じます。 その代わりに、Bバイトを含む1つの大きなパケットを送信すると、固定のオーバーヘッドが1回生じるだけで済み、全体のスループットが大きく向上します。
このアルゴリズムは、可能な限り最高のスループットでデータをターゲットとストリーム送受信したい場合に、最適に機能します。 反対に、小さなパケットを低い頻度で送信して (たとえば、コマンドをターゲットに送信してリレー (1バイトのブールデータ) を開くといった動作を行う場合など)、それもできるだけ早く実行したい場合には、最適化するために「レイテンシ」と呼ばれる機能が必要になります。
アプリケーションでレイテンシの最適化の方が重要な場合は、「シェア変数データを排出」VIを使用する必要があります。 このVIは、LogosXTの送信バッファを、シェア変数エンジンを介してネットワーク全体にわたって強制的にフラッシュします。 これによりレイテンシは著しく短くなります。
メモ: LabVIEW 8.5では、LogosXTのバッファを強制的にフラッシュさせるフックがなく、「シェア変数データを排出」VIもありませんでした。 その代わりに、最低10 msのレイテンシがシステムに組み込まれており、プログラムは転送バッファが貯まるまで待機して10 ms毎にバッファ内にあるデータを送信します。
しかし、前述のように、1つのマシンから別のマシンに接続しているすべてのシェア変数が同じ転送バッファを共有しているため、「シェア変数データを排出」VIを呼び出すことでシステム中にある多くのシェア変数に影響を与えることになります。 高スループットに依存している変数がある場合、「シェア変数データを排出」VI (図9) を呼び出すことでそれらの変数に悪影響を及ぼすことになります。
図9.「シェア変数データを排出」VI
デプロイとホスティング
ネットワーク共有シェア変数は、ネットワークでシェア変数値をホストしているシェア変数エンジン (SVE) にデプロイする必要があります。シェア変数ノードへ書き込みを行う際、その変数をデプロイしてホストするSVEへ新しい値が送信されます。すると、SVEの処理ループは値をネットワーク共有し、サブスクライバは更新された値を受信します。図10は、この処理を示します。クライアント/サーバという用語を使用して説明すると、SVEはシェア変数のサーバになり、すべてのリファレンスは変数との間で書き込みまたは読み取りのどちらを行う場合でもクライアントになります。SVEクライアントは、各シェア変数ノードの実装の一部で、このドキュメントでのクライアントとサブスクライバは同義語です。
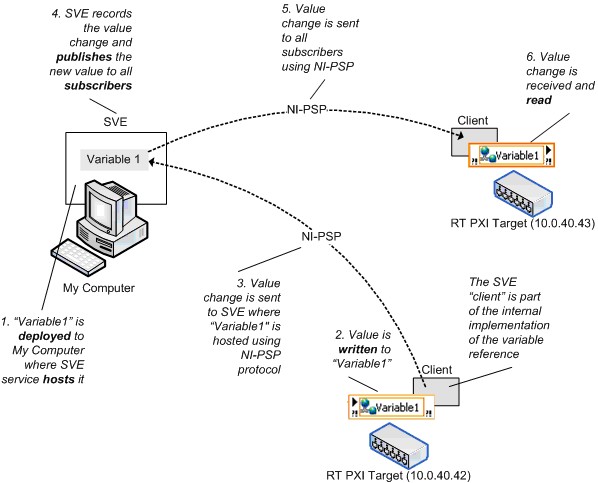
図10.シェア変数エンジンとネットワーク共有シェア変数の値変更
ネットワーク共有シェア変数とLabVIEW Real-Time
ネットワーク共有シェア変数のReal-Time FIFOは有効にできますが、FIFOが有効なネットワーク共有シェア変数とFIFOが有効なリアルタイムの単一プロセスシェア変数の動作には重大な違いがあります。単一プロセスシェア変数では、すべての書き込み側と読み取り側が1つのReal-Time FIFOを共有しますが、ネットワーク共有シェア変数の場合はそうではありません。ネットワーク共有シェア変数の各読み取り側は、下の図のように、単一の要素を持つ場合と複数の要素を持つ場合という両方において、独自のReal-Time FIFOを持つことができます。
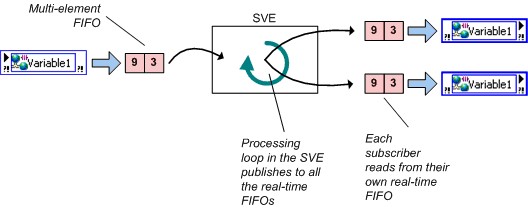
図11.Real-Time FIFO有効のネットワーク共有シェア変数
ネットワークバッファ
ネットワーク共有シェア変数ではバッファを使用することができます。下の図12で示すように、シェア変数プロパティダイアログボックスでバッファを構成できます。
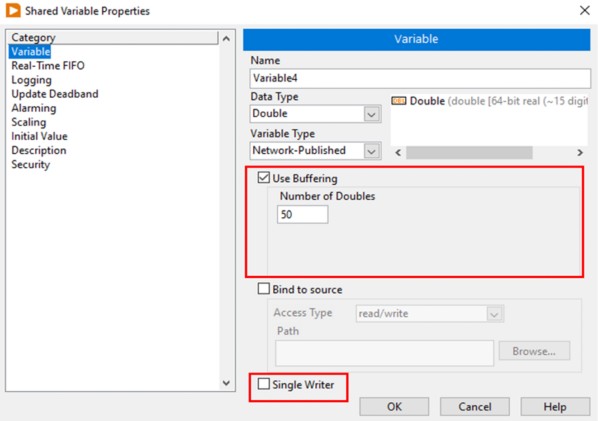
図12.ネットワーク共有シェア変数でバッファを有効にする
バッファリングを有効にすると、バッファのサイズをデータタイプの単位で (この例では倍精度浮動小数で) 指定できます。
バッファを使用すると、変数の読み取りレートと書き込みレートの間に生じる一時的な変動を補償できます。変数を読み取る速度が書き込み側より遅くなりがちな読み取り側は、更新を受け損なう可能性があります。データ点をいくらか失っても支障がないアプリケーションでは、読み取りレートが遅くてもそのアプリケーションに影響を及ぼすことはなく、バッファを有効にする必要はありません。ただし、読み取り側がすべての更新を受ける必要がある場合には、バッファを有効にしてください。バッファサイズは、シェア変数プロパティダイアログボックスの変数ページで設定できます。これを設定すると、古いデータが上書きされる前にいくつの更新を保持するかを決定できます。
前述のダイアログボックスでネットワークバッファを構成すると、実際には「2つの異なるバッファ」のサイズが構成されます。 下の図13でシェア変数エンジン (SVE) の中のバッファであるサーバ側バッファは、自動的に作成され、クライアント側バッファ (詳細は後述) と同じサイズに構成されます。 シェア変数のバッファを有効化するとき、通常はこのクライアント側バッファを有効化していると考えます。 クライアント側バッファ (図13で右側) は、前の値のキューを保持します。 このバッファによって、シェア変数がループ速度やネットワークトラフィックの変動から保護されます。
FIFOが有効なリアルタイムの単一プロセス変数では、すべての書き込み側と読み取り側が同じReal-Time FIFOを共有します。一方、ネットワーク共有シェア変数の各読み取り側は独自のバッファを使用できるため、読み取り側同士でやり取りすることはありません。
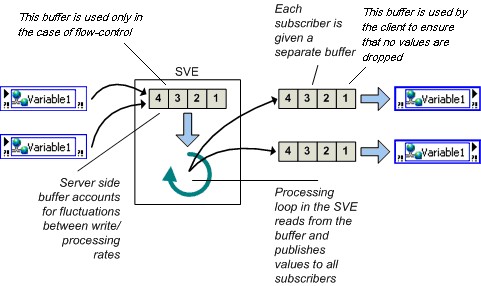
図13.バッファ
バッファが役に立つのは、読み取りレートや書き込みレートが一時的に変動する状況においてのみです。アプリケーションの実行時間が無限の場合、読み取りレートが書き込みより常に遅ければ、どのようなバッファサイズを指定したとしても結局はデータを喪失することになります。バッファ処理を行うとバッファがすべてのサブスクライバに割り当てられます。したがって、不要なメモリ使用を避けるために必要時のみバッファを使用するようにしてください。
ネットワークおよびReal-Timeバッファ
ネットワークバッファとReal-Time FIFOの両方を有効にすると、シェア変数でその両方が使用できます。Real-Time FIFOを有効にすると、各書き込み側と読み取り側に新しいReal-Time FIFOが作成されることに注意してください。つまり、書き込み側と読み取り側が複数個ある場合でも、書き込みと読み取り間で互いにブロックすることはありません。
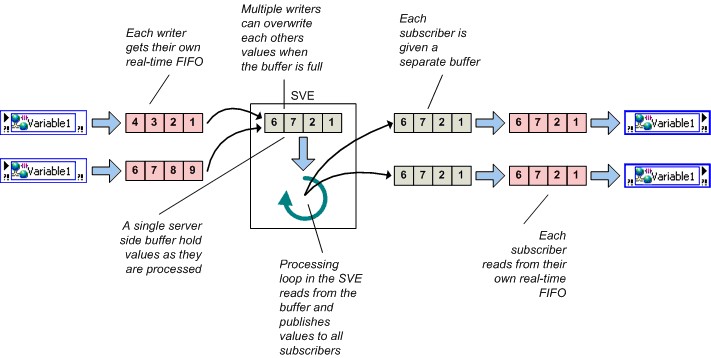
図14.ネットワークバッファとReal-Time FIFO
これらの2つのバッファサイズを個別に設定することは可能ですが、NIでは同じサイズに保持することを推奨します。Real-Time FIFOを有効にすると、書き込み側と読み取り側のそれぞれに新しいReal-Time FIFOが作成されます。そのため、複数の書き込みと読み取り間で互いにブロックし合うことはありません。
バッファの寿命
初回書き込み時もしくは読み取り時に、バッファの位置に応じてネットワークバッファとReal-Time FIFOバッファが作成されます。
- サーバ側のバッファは、書き込み側が最初にシェア変数に書き込みを行ったときに作成されます。
- クライアント側のバッファは、サブスクリプションが確立されたときに作成されます。
これらの動作は、シェア変数ノードを含むVIが起動したときに発生します。 読み取り側がシェア変数へのサブスクライブを行う前に書き込み側がその変数にデータを書き込んだ場合、サブスクライバは最初のデータ値を利用できません。
メモ: 8.6より前のLabVIEWでは、読み取りまたは書き込みのシェア変数ノードが初めて実行されたときにバッファの作成が発生していました。
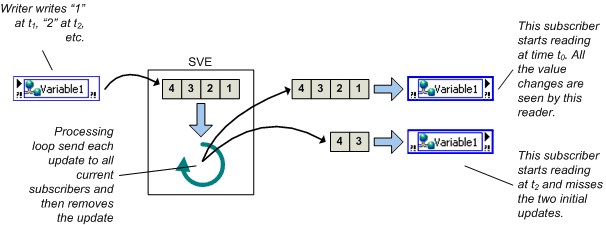
図15.バッファの寿命
バッファのオーバーフロー/アンダーフロー
ネットワーク共有シェア変数は、ネットワークバッファのオーバーフローとアンダーフローの状態を報告します。いずれのバージョンでもReal-Time FIFOは、FIFOがオーバーフローもしくはアンダーフローになるとエラーを返します。
メモ: 旧バージョンのLabVIEWは、ネットワークバッファのオーバーフロー/アンダーフロー状態を報告しません。 LabVIEW 8.0もしくは8.0.1で作成されたアプリケーションでは、ネットワークバッファの状態がアンダーフローかどうかを2つの方法で確認できます。シェア変数のタイムスタンプ分解能は1 msであるため、1 kHz未満でシェア変数を更新する際にシェア変数のタイムスタンプと次に読み取るタイムスタンプを比較することで、バッファのアンダーフローを検出します。または、読み取りでデータのシーケンス番号を使用してバッファのオーバーフロー/アンダーフローを検知できます。2番目の方法は、データタイプが配列の場合、タイムクリティカルループ内で使用されているシェア変数では使用できません。これは、クラスタの要素の1つが配列の場合、Real-Time FIFOが有効なシェア変数ではカスタム制御 (クラスタ) データタイプがサポートされていないためです。
シェア変数の寿命
前述のように、シェア変数はプロジェクトライブラリの一部です。これらの変数が必要になると、SVEはライブラリに含まれているシェア変数とプロジェクトライブラリを登録します。デフォルトでは、SVEは変数をリファレンスするVIが実行されると、すぐにその変数を含むシェア変数のライブラリをデプロイしてネットワーク共有します。SVEは、シェア変数を持つ全ライブラリをデプロイするため、実行中のVIがそれらすべてをリファレンスするかどうかにかかわらず、ライブラリ内のシェア変数をすべてネットワーク共有します。プロジェクトエクスプローラウィンドウでライブラリを右クリックすると、プロジェクトライブラリをいつでも手動でデプロイすることができます。
シェア変数をホストしているコンピュータを再起動したりVIを停止したりしても、そのシェア変数がネットワーク上で使用できなくなることはありません。ネットワークからシェア変数を削除する場合、プロジェクトエクスプローラウィンドウでそのシェア変数が含まれているライブラリを確実にデプロイ解除する必要があります。または、ツール→分散システムマネージャを選択してシェア変数またはシェア変数を含むプロジェクトライブラリ全体をデプロイ解除することができます。
メモ: 旧バージョンのLabVIEWでは、分散システムマネージャの代わりに変数マネージャ (ツール→シェア変数→変数マネージャ) を使用して、シェア変数のデプロイメントを制御します。
フロントパネルのデータバインディング
ネットワーク共有シェア変数でのみ使用可能な追加機能の1つに、フロントパネルのデータバインディングがあります。シェア変数にバインドされた制御器を作成するには、シェア変数をプロジェクトエクスプローラウィンドウからVIのフロントパネルへドラッグします。制御器のデータバインディングを有効にした場合、制御器の値を変更すると、制御器をバインドしたシェア変数の値も変更されます。図16に示すように、VIの実行中にSVEへの接続が成功すると、VIのフロントパネルオブジェクトの隣に小さい緑色のインジケータが表示されます。

図16.フロントパネル制御器をシェア変数にバインディング
プロパティダイアログボックスのデータバインディングページで、制御器または表示器のバインディングにアクセスおよび変更を加えることができます。LabVIEW Real-TimeモジュールまたはLabVIEW DSCモジュールを使用すると、ツール→シェア変数→フロントパネルバインディング一括構成を選択してフロントパネルバインディング一括構成ダイアログボックスを表示し、制御器とシェア変数をバインドするオペレータインタフェースを作成できます。
LabVIEW Real-Timeで実行するアプリケーションでは、フロントパネルがない場合があるため、フロントパネルのデータバインディングの使用は推奨していません。
プログラミングでのアクセス
前述のように、シェア変数はLabVIEWプロジェクトで対話的に作成、構成、デプロイすることができます。また、ブロックダイアグラム上で、またはフロントパネルデータバインディングによって、シェア変数ノードでシェア変数に対する読み取りや書き込みを行うことができます。LabVIEW 2009以降では、こうした機能のすべてにプログラミングでアクセスすることができます。
多数のシェア変数を作成する必要のあるアプリケーションでは、VIサーバを使用してプロジェクトライブラリとシェア変数をプログラム的に作成できます。さらに、LabVIEW DSCモジュールでは、包括的なVIセットを利用して、プロジェクトライブラリやシェア変数の作成および編集をプログラム的に行ったり、SVEを管理したりできます。シェア変数ライブラリのプログラムによる作成は、Windowsで実行するシステム上でのみ可能ですが、これらの新規ライブラリへのプログラムによるデプロイは、WindowsまたはLabVIEW Real-Timeシステムで可能です。
アプリケーションで、VIが読み取りおよび書き込みを行うシェア変数を動的に変更する必要がある場合、または多数の変数を読み書きする必要がある場合は、プログラム的シェア変数APIを使用します。プログラミングでURLを構築することで、シェア変数を動的に変更することができます。
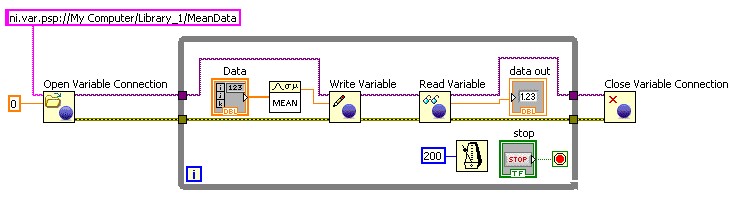
図17.プログラム的シェア変数APIを使用したシェア変数の読み取りおよび書き込み
さらに、NI LabWindows/CVI 8.1やNI Measurement Studio 8.1のネットワーク変数ライブラリを使用すれば、ANSI C、Visual Basic .NET、Visual C#でシェア変数に対する読み書きが行えます。
シェア変数エンジン
SVEとは、ネットワーク共有シェア変数を有効にし、ネットワーク経由で値を送信するソフトウェアフレームワークのことです。Windowsでは、LabVIEWはSVEをサービスとして構成し、システム起動時にSVEを起動します。Real-Timeターゲットでは、SVEはシステムの起動時に起動するインストール可能なコンポーネントです。
ネットワーク共有シェア変数を使用するには、SVEが分散システム上の少なくとも1つのノードで実行されている必要があります。ネットワーク上のいずれのノードでも、SVEによってネットワーク共有されるシェア変数に対して読み書きが行えます。表1に示すように、SVEがインストールされていなくても、ノードは変数をリファレンスできます。アプリケーション要件に基づいてさまざまな場所にシェア変数をデプロイする必要がある場合、複数のSVEを複数のシステムにインストールすることができます。
シェア変数のホスト場所に関する詳細事項
ネットワーク共有シェア変数を分散システムで使用する場合、シェア変数をどのコンピュータデバイスにデプロイ、ホストさせるかを決定するには、多くの要因を考慮する必要があります。
コンピュータデバイスはSVEと互換性がありますか。
次の表はSVEが使用できるプラットフォームをまとめたもので、どのプラットフォームでリファレンスノードまたはDataSocket APIを介してネットワーク共有シェア変数を使用できるか示しています。すべてのプラットフォームにおいて、SVEの使用には32 MB以上のRAMが必須であり、64 MB以上を推奨します。
シェア変数のホスティングはLinuxでもMacintoshでもまだサポートされていません。
アプリケーションでデータロギング/監視機能が必要ですか。
LabVIEW DSCモジュールの機能を使用する場合には、Windows上でシェア変数をホストしてください。LabVIEW DSCモジュールにより、ネットワーク共有シェア変数に以下の機能が追加されます。
・ NI Citadelデータベースへの履歴ロギング。
・ ネットワークアラームおよびアラームロギング。
・ スケール。
・ ユーザベースのセキュリティ。
・ 初期値。
・ カスタムI/Oサーバの作成機能。
・ LabVIEWイベントストラクチャとシェア変数の統合
・ シェア変数とシェア変数エンジンを全面的にプログラミングで制御するLabVIEW VI。これらのVIは、特に多数のシェア変数を制御する場合に便利です。
コンピュータデバイスには適切なプロセッサとメモリが搭載されていますか。
SVEは、処理能力とメモリリソースの両方を必要とする追加のプロセスです。分散システムで最大のパフォーマンスを実現するには、メモリ容量が大きくより優れたプロセッサを搭載したコンピュータにSVEをインストールしてください。
どのシステムが常にオンラインですか。
時々オフラインになるシステムを含む分散アプリケーションを構築するには、常にオンラインのシステム上でSVEをホストします。
シェア変数エンジンの追加機能
図18はSVEの機能を示します。ネットワーク共有シェア変数の管理に加え、SVEは以下の管理も行います。
・ I/Oサーバから受信したデータを収集する。
・ OPCサーバやPSPサーバを介してサブスクライバにデータを送信する。
・ 構成されたスケール、アラーム、ロギングサービスをシェア変数に提供する。これらのサービスはLabVIEW DSCモジュールでのみ使用できます。
・ アラーム状態の有無を監視して適切に応答する
I/Oサーバ
I/Oサーバは、シェア変数エンジン (SVE) のプラグインであり、プログラムがSVEを使用してデータを公開できるようにします。NI-DAQmxには、従来のDAQ OPCサーバおよびリモートデバイスアクセス (RDA) の代わりに、NI-DAQmxのグローバル仮想チャンネルをSVEに自動的に公開できるI/Oサーバが含まれています。LabVIEWがインストールされていなくても、NI-DAQmxはSVEを独立してインストールできます。
SVEはOPC DAサーバとして機能するため、SVEとNI-DAQmx I/Oサーバの組み合わせはNI-DAQmxデータのOPC DAサーバとして動作します。OPC UAをサポートするには、LabVIEW OPC UAツールキットが必要です。
LabVIEW DSCモジュールを使用すると、追加のプロトコルおよびデータソース向けのカスタムI/Oサーバを作成できます。
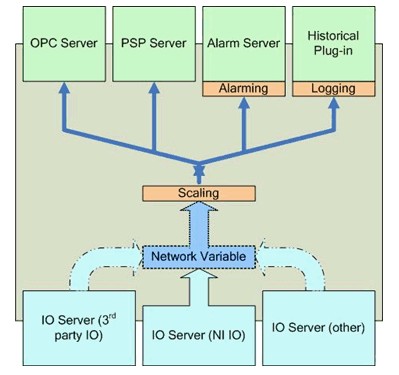
図18.シェア変数エンジン (SVE)
OPC
SVEは3.0に準拠しており、Windowsマシン上でOPCサーバとして動作できます。すべてのOPCクライアントはWindowsマシン上にホストされているシェア変数への書き込み、およびシェア変数からの読み取りを行うことができます。WindowsマシンにLabVIEW DSCモジュールをインストールすると、SVEもOPCクライアントとして動作することができます。Windowsマシンがホストしているシェア変数を、DSCを使用して変数とOPCデータ項目間で書き込み、読み取りを行うことでバインドします。
OPCはWindows APIであるCOMをベースとしたテクノロジであるため、Real-TimeターゲットはOPCと直接連携して動作しません。しかし、図19で示すように、Windowsマシンでシェア変数をホストすることで、Real-TimeターゲットからOPCデータ項目へアクセスすることができます。
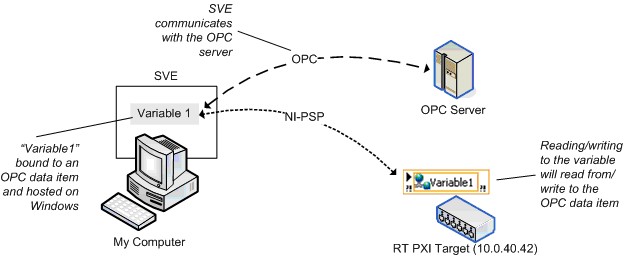
図19.OPCデータ項目へのバインディング
パフォーマンス
このセクションでは、シェア変数を使用して高性能アプリケーションを作成する際の一般的なガイドラインについて説明します。
単一プロセスシェア変数の実装は、LabVIEWグローバル変数およびReal-Time FIFOと類似しているため、単一プロセスシェア変数については高パフォーマンス実現のための推奨事項は特にありません。以降のセクションではネットワーク共有シェア変数を中心に説明します。
プロセッサの共有
ネットワーク共有シェア変数は、ネットワークプログラミングの実装詳細を隠すことができるので、LabVIEWのブロックダイアグラムをシンプルに保てます。アプリケーションは、LabVIEW VI、およびSVEとSVEクライアントコードで構成されています。シェア変数のパフォーマンスを最大限発揮させるには、SVEスレッドが実行されるようにプロセッサの使用を定期的に放棄するアプリケーションを開発します。そのための方法の1つとして、処理ループ内で数か所待機を設け、アプリケーションがタイミングを無視してループを使用しないようにします。必要となる正確な待機時間は、アプリケーション、プロセッサ、ネットワークによって異なります。最大限のパフォーマンスを達成するには、すべてのアプリケーションで経験に基づいた何らかのチューニングが必要になります。
SVEの場所に関する注意事項
「シェア変数のホスト場所に関する詳細事項」セクションで、SVEのインストール場所を決める際に注意すべきいくつかの条件について説明しています。図20は、シェア変数のパフォーマンスに大きな影響を与えるもう1つの要件を示しています。この例ではReal-Timeターゲットを使用していますが、基本的な原則はリアルタイムでないシステムにも適用されます。図20は、ネットワーク共有シェア変数の効率の悪い使用例を示しています。ここでは、データをReal-Timeターゲットで生成し、処理されたデータをローカルでログしてリモートマシンで監視しています。変数のサブスクライバはSVEからデータを受信しなければならないため、高優先度ループでの書き込みと標準優先度ループの読み取り間のレイテンシが長くなり、ネットワーク内でデータが2回転送されます。
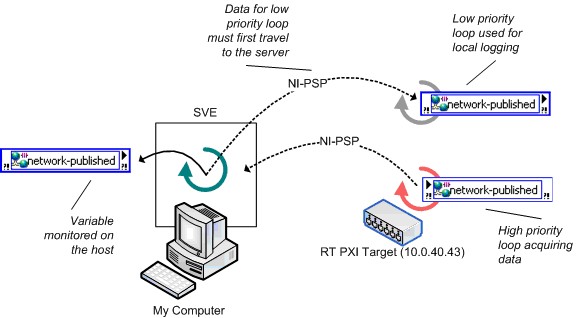
図20.Real-Timeでのネットワーク共有シェア変数の効率の悪い使用例
図21は、このアプリケーションにおける効率の良いアーキテクチャを示します。このアプリケーションでは、単一プロセスシェア変数を使用して、高優先度ループと低優先度ループ間でデータ転送を行うことで、レイテンシを大幅に短縮しています。低優先度ループは、ホストのサブスクライバのためにデータをログしてネットワーク共有シェア変数へ更新を書き込みます。
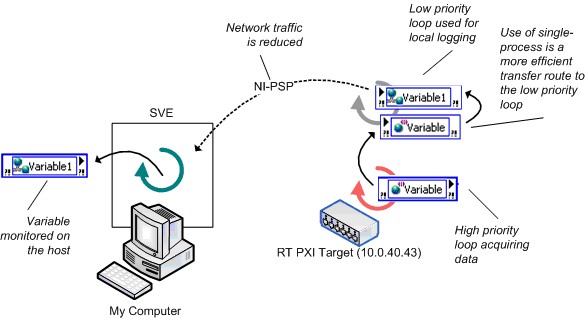
図21.Real-Timeでのネットワーク共有シェア変数の効率の良い使用例
ベンチマーク
このセクションでは、シェア変数のパフォーマンスを、LabVIEWでの他のデータ共有方法 (LabVIEWグローバル変数、Real-Time FIFO、TCP/IPなど) と比較します。次の表はテストの概要を示しています。詳細は以降のセクションで説明します。
テスト | 説明 | SVEの場所 | メモ |
|---|---|---|---|
T1 | 単一プロセスシェア変数 vs. グローバル変数 | N/A | 最高の読み取り/書き込みレートを確立。 |
T2 | Real-Time FIFOを使用した単一プロセスシェア変数 vs. real-time FIFO VI | N/A | Real-Time FIFOの使用時に最高の読み取り/書き込みレートを確立。 タイミングループでシェア変数またはReal-Time FIFOに書き込み、同時に標準優先度ループからデータの読み取りを行うことができる、持続可能な最高レートを決定します。 |
T3 | Real-Time FIFOが有効化されたネットワーク共有シェア変数 vs. TCPが有効化された2ループのReal-Time FIFO | LV RTを実行しているPXI | シングルポイントデータをネットワークでストリーミングできる最大レートを確立。 シェア変数: 読み取りVIは常にホスト上にあります。RT-FIFO + TCP: 追加のTCP通信/IPネットワーキングを使用したT2に類似。 |
T4 | ネットワーク共有シェア変数フットプリント | RTシリーズターゲット | デプロイ後のシェア変数のメモリ使用量を確立。 |
T5 | 8.2ネットワーク共有シェア変数と8.5変数間の比較 (ストリーミング) | RTシリーズターゲット | NI-PSPの新しい8.5実装と8.20以前の実装を比較。 このベンチマークは、波形データをcRIOデバイスからデスクトップホストへストリーミングするアプリケーションのスループットを測定します。 |
T6 | 8.2ネットワーク共有シェア変数と8.5変数間の比較 (高チャンネルカウント) | RTシリーズターゲット | NI-PSPの新しい8.5実装と8.20以前の実装を比較。 このベンチマークは、cRIOデバイスでチャンネル数の多いアプリケーションにおけるスループットを測定します。 |
表2. ベンチマーク概要
以降のセクションでは、NIが各ベンチマーク用に作成したコードと、実際のベンチマーク結果について説明しています。各ベンチマークに対して選択した方法と、ベンチマークを実行したハードウェアおよびソフトウェアの詳細構成については、「方法と構成」セクションで詳しく説明します。
単一プロセスシェア変数 vs.LabVIEWグローバル変数
単一プロセスシェア変数は、LabVIEWグローバル変数に類似しています。実際、単一プロセスシェア変数の実装は、LabVIEWグローバル変数にタイムスタンプ機能が付いたものです。
単一プロセスシェア変数とLabVIEWグローバル変数のパフォーマンスを比較するために、NIではベンチマークVIを作成してLabVIEWグローバル変数または単一プロセスシェア変数で読み取りおよび書き込みを1秒につき何回行えるか測定できるようにしました。図22は、単一プロセスシェア変数の読み取りベンチマークを示しています。単一プロセスシェア変数の書き込みベンチマークと、LabVIEWのグローバル読み取り/書き込みベンチマークは、同じパターンに従っています。
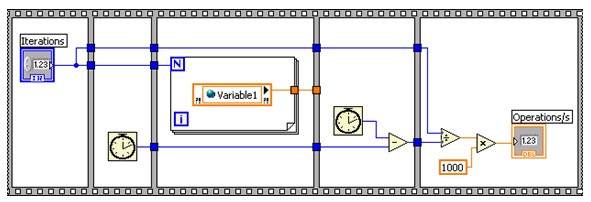
図22.単一プロセスシェア変数の読み取りベンチマークVI
読み取り/書き込みの組み合わせテストには、各書き込みポイントでデータの破損なく同じループ反復で読み取りも行えるかどうか確認するコードも含まれています。
T1テストの結果
図23は、テストT1の結果を示しています。これを見ると、単一プロセスシェア変数の読み取りパフォーマンスはLabVIEWグローバル変数のパフォーマンスよりも低くなっています。単一プロセスシェア変数の書き込みパフォーマンスもLabVIEWグローバル変数のパフォーマンスよりやや低くなっています。つまり、読み取り/書き込み両方のパフォーマンスが低くなっています。単一プロセスシェア変数のパフォーマンスはタイムスタンプ機能の有効/無効に左右されるため、利用目的がない場合はタイムスタンプをオフにすることを推奨します。
「方法と構成」セクションでは、このテストセットの具体的なベンチマーク方法と構成の詳細について説明しています。
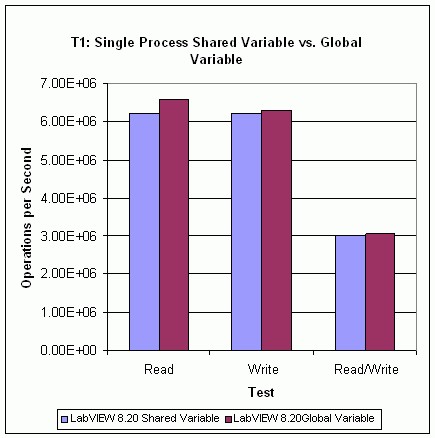
図23.単一プロセスシェア変数 vs. グローバル変数のパフォーマンス
単一プロセスシェア変数 vs.Real-Time FIFO
NIでは、FIFOが有効化された単一プロセスシェア変数のパフォーマンスについて、従来型Real-Time FIFO VIと比較するため、持続可能なスループットのベンチマークを測定しました。ベンチマークでは、実装した2つのReal-Time FIFOのそれぞれについて、転送されたデータ (ペイロード) のサイズの影響についても調べています。
このテストは、データを生成するタイムクリティカルループ (TCL) とデータを消費する標準優先度ループ (NPL) で構成されています。 ペイロードサイズによる影響は、倍精度スカラと配列データタイプの範囲を詳細に調査したうえで決定しました。スカラタイプはペイロードが1倍精度時のスループットを決定し、配列タイプは残りのペイロードのスループットを決定します。テストでは、両方のループでデータ損失なしに実行できる持続可能な最高速度を決定することで、持続可能な最高スループットを記録しています。
図24は、Real-Time FIFOベンチマークの簡略化したダイアグラムを示しており、FIFOの作成と破棄に必要なコードの多くを省略しています。LabVIEW 8.20の時点では、ここに示したFIFOサブVIを置き換える新しいFIFO関数が導入されています。FIFO関数は、このドキュメントのグラフデータに使用されており、従来のLabVIEW 8.0.xのサブVIよりも優れた結果を示しています。
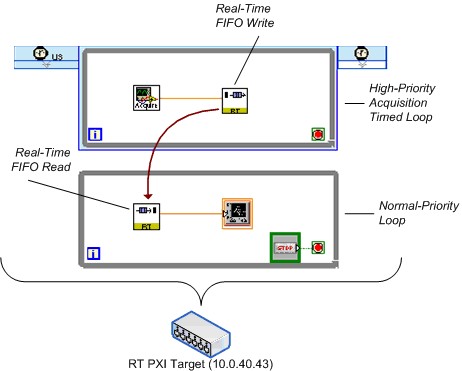
図24.簡略化したReal-Time FIFOベンチマークVI
単一プロセスシェア変数を使用した同様のテストです。図25は、そのダイアグラムを簡略化したものです。
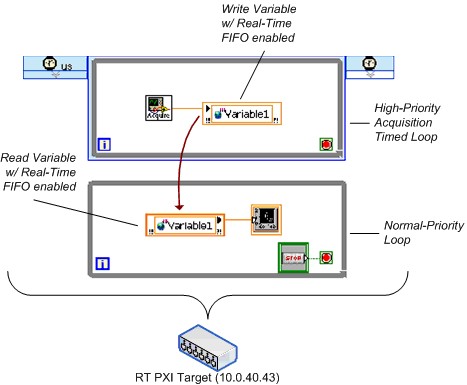
図25.簡略化したFIFO有効の単一プロセスシェア変数ベンチマークVI
T2テストの結果
図26と図27は、テストT2の結果を示しており、FIFO有効の単一プロセスシェア変数とReal-Time FIFO関数のパフォーマンスを比較しています。これらの結果から、単一プロセスシェア変数はReal-Time FIFOに比べてやや遅いことがわかります。
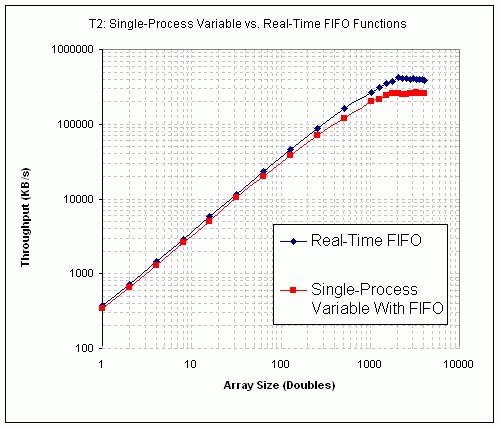
図26.単一プロセスシェア変数 vs. Real-Time FIFO VIのパフォーマンス (PXI)
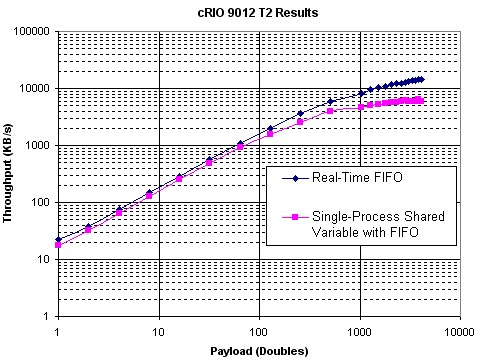
図27.単一プロセスシェア変数 vs. Real-Time FIFO VIのパフォーマンス (cRIO 9012)
ネットワーク公開シェア変数とReal-Time FIFOおよびTCP/IP
シェア変数の柔軟性を利用すると、構成を多少変更するだけで、単一プロセスシェア変数を迅速にネットワーク共有することができます。特にReal-Timeアプリケーションでは、同じ転送を旧バージョンのLabVIEWで実行する場合、RTシリーズのコントローラでReal-Time FIFOを読み取るために多くのコードを導入する必要があり、その後にアプリケーションは利用可能なネットワーキングプロトコルの1つを使用してデータをネットワーク経由で送信することができます。この2つの方法のパフォーマンスを比べるために、このテストでも、ペイロード範囲内でデータ損失なく持続可能な各スループットを測定できるベンチマークVIを作成しました。
事前に変更が可能なアプローチとするため、ベンチマークVIではReal-Time FIFOとTCP/IPを使用しています。TCLでデータを生成してReal-Time FIFOに配置します。NPLでFIFOからデータを読み取り、TCP/IPを使用してネットワーク経由で送信します。ホストPCでデータを受信し、データ損失がないか確認します。
図28は、Real-Time FIFOとTCP/IPベンチマークの簡略化したダイアグラムを示しています。このダイアグラムでも実際のベンチマークVIを大幅に簡略化しています。
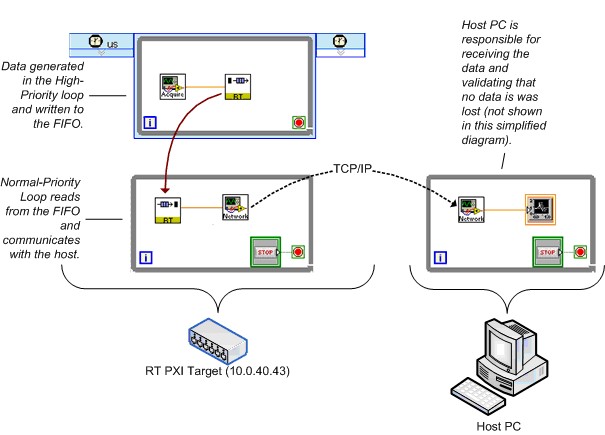
図28.簡略化したReal-Time FIFOとTCP/IPベンチマークVI
NIでは、ネットワーク共有シェア変数を使用した同様のテストを作成しました。図29は、簡略化したダイアグラムを示しています。
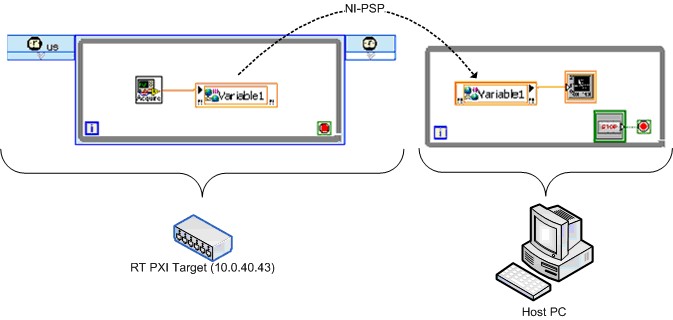
図29.簡略化したReal-Time FIFO有効のネットワーク共有シェア変数ベンチマークVI
T3テストの結果
このセクションはテストT3の結果を示しています。ここでは、Real-Time FIFOが有効になったネットワーク共有シェア変数のパフォーマンスと、Real-Time FIFO VIおよびLabVIEW TCP/IPプリミティブに依存した同等のコードのパフォーマンスとを比較しています。図30は、LabVIEW Real-Timeターゲットが組込RTシリーズPXIコントローラである場合の結果を示しています。
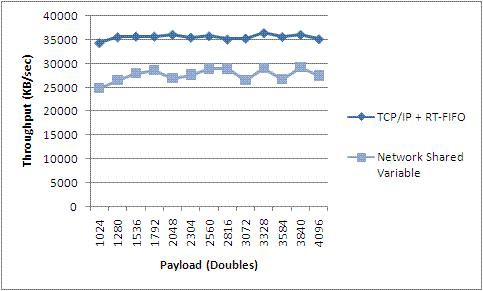
図30.ネットワーク共有シェア変数 vs. Real-Time FIFOおよびTCP VIのパフォーマンス (PXI)
T3の結果は、ネットワーク共有シェア変数のスループットがTCPのスループットに近づき、どちらも中から大のペイロードサイズで一貫していることを示しています。 シェア変数は、プログラミングを容易にしますが、欠点もあります。 ただし、TCPのネイティブ実装を使用した場合、特にNI-PSPの新しい8.5の実装において、シェア変数のパフォーマンスが低下しやすい可能性があることに注意してください。
T4テストの結果
ネットワーク共有シェア変数のメモリフットプリント
LabVIEW 8.5では、変数フットプリントの大きな変化はありませんでした。 したがって、このベンチマークは再実行しませんでした。
シェア変数のメモリフットプリントを決定することは、シェア変数のメモリ使用量が構成によって変化するため困難です。たとえば、バッファを使用するネットワーク共有シェア変数では、必要に応じてプログラムから動的にメモリを割り当てます。また、シェア変数をReal-Time FIFOを使用するように構成した場合もメモリの使用量が増えます。これは、ネットワークバッファに加えてLabVIEWによってFIFO用のバッファが作成されるためです。そのため、このドキュメントのベンチマーク結果は基準となるメモリ測定量のみを表しています。
図31は、LabVIEWが500個および1000個の指定されたタイプのシェア変数をSVEにデプロイした後に、SVEが使用するメモリ使用量を示しています。このグラフから、変数のタイプはデプロイされたシェア変数のメモリ使用量にそれほど影響を与えないことがわかります。これらはバッファを使用しない変数です。
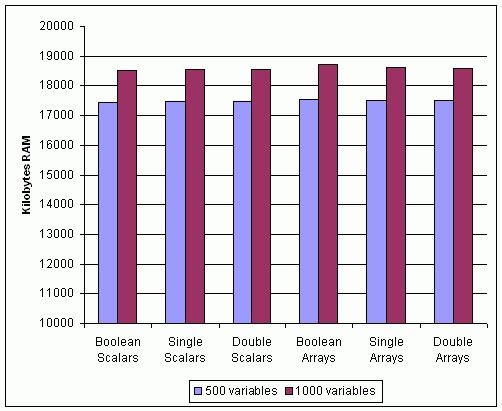
図31.異なるデータタイプでのネットワーク共有シェア変数のメモリ使用量
図32は、メモリ使用量を、デプロイされたシェア変数の個数の関数として示しています。このテストでは1種類の変数 (空のブール配列) のみを使用しています。メモリ使用量は変数の個数の増加に比例して増加します。
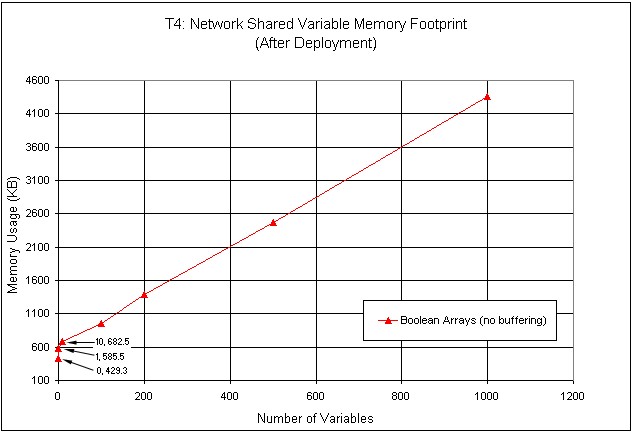
図32.異なるサイズにおけるシェア変数のメモリ使用量
T5テストの結果
8.2ネットワーク共有シェア変数と8.5変数間の比較 (ストリーミング)
LabVIEW 8.5では、シェア変数データのトランスポートに使用されるネットワークプロトコルの最下層を再実装しました。 この結果、パフォーマンスが大幅に向上しています。
この例では、cRIO 9012で単一の変数タイプである倍精度の波形をホストしました。 すべてのデータを生成した後、タイトなループ内でデータをホストに転送しました。ホストでは、別の波形シェア変数ノードからできるだけ速くデータを読み取りました。
図30からわかるように、LabVIEW 8.5ではこの使用例でパフォーマンスが600%以上向上しました。
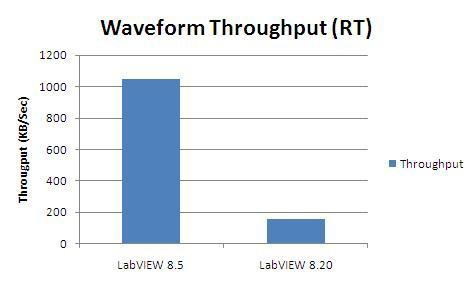
図33.LabVIEW 8.5とLabVIEW 8.20以前の間の波形スループット比較
T6テストの結果
8.2ネットワーク共有シェア変数と8.5変数間の比較 (ストリーミング)
このテストでは、T5と同じ2つのターゲットを使用しましたが、単一の変数を転送する代わりに、データタイプを倍精度浮動小数に変更し、シェア変数の数を1~1,000個の間で変化させて、スループットを測定しました。 ここでも、すべての変数をcRIO 9012でホストし、増分データの生成も同様にcRIO 9012で行い、ホストに送信して読み取りました。
図34を見ても、LabVIEW 8.20と比べてLabVIEW 8.5はパフォーマンスが大きく向上していることがわかります。 ただし、小さな変数を多数使用する場合は、T5のように単一の大きな変数を使用する場合よりもスループットが大幅に低下します。 これは、変数ごとに一定量のオーバーヘッドが伴うためです。 小さな変数を多数使用する場合は、このオーバーヘッドが変数の数だけ倍加するため、非常に顕著になります。
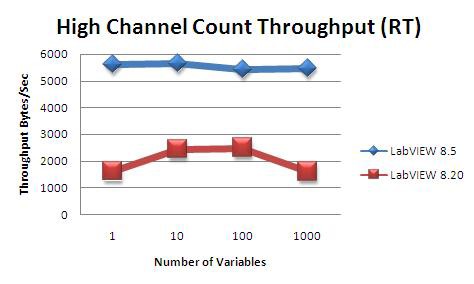
図34.LabVIEW 8.5とLabVIEW 8.20以前の間の高チャンネルカウントスループット比較
方法と構成
このセクションでは、前述のすべてのテストセットにおけるベンチマークプロセスに関する詳細情報を記載しています。
T1の方法と注意事項
テストT1では、シンプルなベンチマークテンプレートを使用して、多数の反復を簡単に平均することで読み取りおよび書き込みレートを決定しています。各テストでは、ほぼ1分程度の合計実行時間中に、合計5億回の反復処理を実行し、ミリ秒の分解能でタイミングをとりました。
T1のハードウェア/ソフトウェア構成
ホストハードウェア
- Dell Precision 450
- Dual Intel Xeon 2.4 GHz Pentiumと同等クラスのプロセッサ
- 1 GB DRAM
ホストソフトウェア
- Windows XP SP2
- LabVIEW 8.20
T2の方法と注意事項
テストT2では、異なる優先度で実行されているタスク間の持続可能な最大通信レートを特定することで、スループットを測定しています。マイクロ秒分解能で実行しているタイミングループには、データ生成器が含まれています。データを消費するのは標準優先度の自走ループです。このループでは、Real-Time FIFOや単一プロセスシェア変数から空になるまで読み取りを行い、エラーなく特定の時間が経過するまでこのプロセスを繰り返します。テスト結果は、以下の条件がすべて満たされる場合にのみ有効です。
- バッファのオーバーフローが発生しない
- データの整合性が保たれている。データ損失がなく、データの消費側が送信された順番でデータを受信する
- タイミングループは1秒間のウォームアップ期間の後、問題なく動作する
単一プロセスシェア変数の受信側ループでは簡単なデータ整合性チェックを行い、想定数のデータポイントを確実に受信したかどうか、受信したメッセージパターンで中間値の欠落がないかどうかなどを確認しています。
Real-Time FIFOおよびシェア変数FIFOのバッファサイズを、すべてのテストとそれに関するデータタイプにおいて100要素に構成しました。
T2のハードウェア/ソフトウェア構成
PXIハードウェア
- NI PXI-8196RTシリーズコントローラ
- 2.0 GHz Pentiumと同等クラスのプロセッサ
- 256 MB DRAM
- Broadcom 57xx (1 Gb/s組込イーサネットアダプタ)
PXIソフトウェア
- LabVIEW 8.20 Real-Timeモジュール
- ネットワーク変数エンジン1.2.0
- 変数クライアントサポート1.2.0
- Broadcom 57xxギガビットイーサネットドライバ2.1 (ポーリングモードで構成済み)
CompactRIOハードウェア
- NI cRIO 9012コントローラ
- 400 MHzプロセッサ
- 64 MB DRAM
CompactRIOソフトウェア
- LabVIEW 8.20 Real-Timeモジュール
- ネットワーク変数エンジン1.2.0
- 変数クライアントサポート1.2.0
T3の方法と注意事項
テストT3では、ネットワークで転送されたデータ量と、テストの全体的な継続時間を記録することで直接的にスループットを測定しています。マイクロ秒分解能で実行しているタイミングループには、データ生成器が含まれています。データ生成器は、特定のデータパターンをネットワーク共有シェア変数またはReal-Time FIFO VIへ書き込みます。
ネットワーク共有シェア変数のテストでは、NPLをホストシステムで実行し、自走のWhileループ内の変数から読み取りを行っています。Real-Time FIFO VIのテストでは、NPLをReal-Timeシステムで実行し、特定レートのFIFO状態を確認し、利用可能なすべての変数データを読み取り、TCPを使用してデータをネットワーク経由で送信しています。ベンチマークの結果を見ると、ポーリング期間を1 msまたは10 msに設定した場合の効果がわかります。
テスト結果は、以下の条件がすべて満たされる場合にのみ有効です。
- FIFOでもネットワークでもバッファのオーバーフローが発生しない
- データの整合性が保たれている。データ損失がなく、データの消費側が送信された順番でデータを受信する
- TCL VIのタイミングループは1秒間のウォームアップ期間の後、問題なく動作する
各データポイントでの読み取りの後、ネットワーク変数テスト用のNPLによって、データパターンが正しいかどうか確認しています。Real-Time FIFOのテストでは、Real-Time FIFOのオーバーフローが発生したかどうかに基づく検証をTCLで行っています。
データ損失を防ぐために、バッファサイズをNPLとTCLループ期間の比率よりも小さくならないよう構成し、Real-Time FIFOの最小バッファサイズを100要素に構成しました。
T3のハードウェア/ソフトウェア構成
ホストハードウェア
- Intel Core 2 Duo 1.8 GHz
- 2 GB DRAM
- Intel PRO/1000 (1 Gb/sイーサネットアダプタ)
ホストソフトウェア
- Windows Vista 64
- LabVIEW 8
ネットワーク構成
1Gb/sスイッチネットワーク
PXIハードウェア
- NI PXI-8196 RTコントローラ
- 2.0 GHz Pentiumと同等クラスのプロセッサ
- 256 MB DRAM
- Broadcom 57xx (1 Gb/s組込イーサネットアダプタ)
PXIソフトウェア
- LabVIEW 8.5 Real‐Timeモジュール
- ネットワーク変数エンジン1.2.0
- 変数クライアントサポート1.2.0
- Broadcom 57xxギガビットイーサネットドライバ2.1
T4の方法と注意事項
テストT4では、倍精度、単精度、ブール、倍精度配列、単精度配列、ブール配列の各データタイプにおける、バッファを使用しないネットワーク共有シェア変数を使用しました。
T4のハードウェア/ソフトウェア構成
PXIハードウェア
- NI PXI-8196 RTコントローラ
- 2.0 GHz Pentiumと同等クラスのプロセッサ
- 256 MB DRAM
- Broadcom 57xx (1 Gb/s組込イーサネットアダプタ)
PXIソフトウェア
- LabVIEW Real-Timeモジュール 8.0
- ネットワーク変数エンジン1.0.0
- 変数クライアントサポート1.0.0
- Broadcom 57xxギガビットイーサネットドライバ1.0.1.3.0
T5およびT6の方法と注意事項
テストT5とT6では、倍精度波形のデータタイプにおける、バッファを使用しないネットワーク共有シェア変数を使用しました。
T5およびT6のハードウェア/ソフトウェア構成
ホストハードウェア
- 64ビットIntel Core 2 Duo 1.8 GHz
- 2 GB RAM
- ギガビットイーサネット
ホストソフトウェア
- Windows Vista 64
- LabVIEW 8.20およびLabVIEW 8.5
CompactRIOハードウェア
- cRIO 9012
- 64 MB RAM
CompactRIOソフトウェア
- LabVIEW RT 8.20およびLabVIEW RT 8.5
- ネットワーク変数エンジン1.2 (LabVIEW 8.20)、1.4 (LabVIEW 8.5)
- 変数クライアントサポート1.0 (LabVIEW 8.20)、1.4 (LabVIEW 8.5)
| Windows PC | Mac OS | Linux | PXI Real-Time | CompactRIO | LabVIEW Real-Time ETS搭載の商用PC | Compact Vision System | Compact FieldPoint | |
|---|---|---|---|---|---|---|---|---|
| SVE | — | — | ||||||
| リファレンスノード | — | — | ||||||
| DataSocket API (PSPを含む) |