Compilateur NI LabVIEW : sous le capot
Aperçu
Contenu
- Compilation et interprétation
- Perspectives historiques du compilateur LabVIEW
- Processus de compilation actuel
- La DFIR et la LLVM fonctionnent en tandem
Ce tutoriel est une introduction au compilateur LabVIEW, qui explique brièvement son évolution depuis 1986 avec LabVIEW 1.0 et décrit sa forme actuelle. Par ailleurs, il présente les innovations récentes en matière de compilateurs et met en évidence les avantages de ces nouvelles caractéristiques pour l’architecture LabVIEW et pour vous.
Compilation et interprétation
LabVIEW est un langage compilé, ce qui peut être surprenant, car il n’y a aucune étape de compilation explicite au cours d’un développement G typique. Au lieu de cela, il suffit à l’utilisateur de modifier son VI et d’appuyer sur le bouton Exécuter. La compilation signifie que le code G que vous écrivez est traduit en code machine natif et qu’il est ensuite exécuté directement par l’ordinateur hôte. L’interprétation est une alternative à cette approche dans laquelle les programmes sont indirectement exécutés par un autre programme logiciel (appelé l’interpréteur) et non pas directement par l’ordinateur.
Rien dans le langage LabVIEW ne nécessite qu’il soit compilé ou interprété ; en fait, la première version de LabVIEW utilisait un interpréteur. Dans les versions suivantes, le compilateur a remplacé l’interpréteur afin d’améliorer les performances d’exécution des VI, point sur lequel les compilateurs se démarquent des interpréteurs. Les interpréteurs sont généralement plus faciles à écrire et à maintenir au prix de performances d’exécution plus lentes, tandis que les compilateurs tendent à être plus complexes à mettre en œuvre mais, en contrepartie, ils offrent des temps d’exécution plus rapides. L’un des principaux avantages du compilateur LabVIEW est que les améliorations qui lui sont apportées touchent tous les VI sans nécessiter le moindre changement. Dans les faits, l’une des principales priorités pour la version 2010 de LabVIEW consistait à optimiser le compilateur afin d’accélérer les temps d’exécution des VI.
Perspectives historiques du compilateur LabVIEW
Avant de voir plus en détail les secrets du compilateur actuel, il est utile de résumer le développement du compilateur depuis ses toutes premières formes il y a plus de 20 ans. Certains des algorithmes présentés ici, comme la propagation de type, la création de blocs et la réutilisation des buffers, sont décrits plus en détail dans la discussion sur la nouvelle version du compilateur LabVIEW.
LabVIEW 1.0 a été commercialisé en 1986. Comme mentionné précédemment, la première version de LabVIEW utilisait un interpréteur et avait pour seule cible le Motorola 68000. Le langage LabVIEW était alors beaucoup plus simple, ce qui allégeait les exigences envers le compilateur (qui était alors un interpréteur). Par exemple, il n’y avait pas de polymorphisme et le seul type numérique disponible était la virgule flottante à précision étendue. LabVIEW 1.1 a vu l’introduction de l’algorithme de réutilisation des buffers appelé « inplacer ». Cet algorithme identifie les allocations de mémoire que vous pouvez réutiliser au cours de l’exécution, ce qui évite des copies superflues de données et, par conséquent, accélère les performances d’exécution de façon souvent spectaculaire.
Dans LabVIEW 2.0, l’interpréteur a été remplacé par un véritable compilateur. Avec toujours pour seule cible le Motorola 68000, LabVIEW pouvait générer du code machine natif. Autre ajout de la version 2.0, l’algorithme de propagation de type gère, entre autres, la vérification de syntaxe et la résolution de type au niveau du langage LabVIEW. L’introduction du « clumper » ou créateur de blocs est une autre innovation majeure dans LabVIEW 2.0. L’algorithme de création de blocs identifie le parallélisme au niveau du diagramme LabVIEW et regroupe les nœuds en blocs capables de s’exécuter en parallèle. Les algorithmes de propagation de type, de réutilisation des buffers et de création de blocs sont toujours des éléments importants de la nouvelle version du compilateur LabVIEW et ont connu bon nombre d’améliorations incrémentielles au fil du temps. La nouvelle infrastructure du compilateur dans LabVIEW 2.5 a ajouté le support de différentes cibles, plus particulièrement les processeurs Intel x86 et Sparc. LabVIEW 2.5 a également introduit l’éditeur de liens, qui gère les dépendances entre les VI pour savoir s’il convient de les recompiler.
Outre la réduction des constantes, deux nouveaux microprocesseurs cibles, PowerPC et HP PA-RISC, ont été ajoutés dans LabVIEW 3.1. LabVIEW 5.0 et 6.0 ont amélioré le générateur de code et ajouté GenAPI, une interface commune à plusieurs microprocesseurs cibles. GenAPI effectue une compilation croisée, ce qui est important pour le développement en temps réel. Les développeurs d’applications temps réel écrivent généralement leurs VI sur un PC hôte, mais les déploient sur (et les compilent pour) une cible temps réel. De plus, une forme restreinte d’extraction de code invariant des boucles a été ajoutée. Enfin, le système d’exécution multitâche LabVIEW a été étendu pour prendre en charge plusieurs threads.
LabVIEW 8.0 s’est appuyé sur l’infrastructure GenAPI introduite dans la version 5.0 pour ajouter un algorithme d’allocation de registres. Avant l’introduction de GenAPI, les registres étaient figés dans le code généré pour chaque nœud. Des formes réduites d’élimination du code mort et du code non accessible ont également été introduites. LabVIEW 2009 a introduit LabVIEW 64 bits et la DFIR (Dataflow Intermediate Representation ou représentation intermédiaire du flux de données). La DFIR a immédiatement été utilisée pour construire des formes plus avancées de mouvement de code invariant des boucles, de réduction des constantes, d’élimination de code mort et de code inaccessible. De nouvelles caractéristiques propres au langage introduites en 2009, comme la parallélisation des boucles For, s’appuyaient elles aussi sur la DFIR.
Enfin, dans LabVIEW 2010, la DFIR offre de nouvelles optimisations du compilateur comme la ré-association algébrique, l’élimination de sous-expressions redondantes, le déroulage de boucle et l’inlining de sous-VI (c’est à dire l’incorporation du code d’un sous-VI dans le code des VI appelants). Cette nouvelle version comprend également l’adoption d’une LLVM (Low-Level Virtual Machine ou machine virtuelle bas niveau) dans la chaîne du compilateur LabVIEW. La LLVM est une infrastructure de compilateur libre largement utilisée dans l’industrie. Avec elle, de nouvelles fonctionnalités ont été ajoutées comme l’ordonnancement des instructions, le loop unswitching (décomposition d’une boucle contenant une condition en plusieurs boucles s’exécutant en fonction de la condition), la combinaison d’instructions, la propagation conditionnelle et un allocateur de registres plus sophistiqué.
Processus de compilation actuel
Avec cette connaissance élémentaire de l’histoire du compilateur LabVIEW, vous pouvez désormais étudier le processus de compilation de la nouvelle version du logiciel. Commençons avec un aperçu rapide des différentes étapes de compilation, puis voyons chaque partie plus en détail.
La première étape de la compilation d’un VI est l’algorithme de propagation de type. Cette étape complexe est responsable de la résolution des types implicites pour les terminaux qui peuvent s’adapter au type, ainsi que de la détection des erreurs de syntaxe. Toutes les erreurs de syntaxe possibles dans le langage de programmation G sont détectées au cours de l’algorithme de propagation de type. Si celui-ci détermine que le VI est valide, alors la compilation se poursuit.
Après la propagation de type, le VI est d’abord converti à partir du modèle utilisé par l’éditeur de diagramme en DFIR qui va être utilisée par le compilateur. Une fois cette conversion effectuée, le compilateur exécute plusieurs transformations sur le graphe DFIR afin de le décomposer, de l’optimiser et de le préparer pour la génération de code. Plusieurs des optimisations du compilateur,par exemple, la réutilisation des buffers et la création de blocs, sont mises en œuvre sous la forme de transformations et sont exécutées au cours de cette étape.
Une fois le graphe DFIR optimisé et simplifié, il est traduit dans la représentation intermédiaire LLVM. Une série de passes de la LLVM est exécutée sur la représentation intermédiaire pour l’optimiser et la réduire davantage, jusqu’au code machine.
Propagation de type
Comme nous l’avons vu précédemment, l’algorithme de propagation de type résout les types et détecte les erreurs de programmation. Dans les faits, plusieurs tâches lui incombent, notamment :
- Résoudre les types implicites pour les terminaux qui peuvent s’adapter au type
- Résoudre des appels de sous-VI et déterminer leur validité
- Calculer la direction des fils
- Vérifier les cycles du VI
- Détecter et reporter les erreurs de syntaxe
Cet algorithme s’exécute après chaque modification apportée à un VI afin de déterminer si celui-ci est toujours valide. On est donc en droit de se demander si cette étape fait réellement partie de la « compilation ». Toutefois, il s’agit de l’étape dans la chaîne de compilation LabVIEW qui correspond le mieux aux étapes d’analyse lexicale, syntaxique ou sémantique dans un compilateur traditionnel.
Un exemple simple de terminal qui s’adapte au type est la primitive « additionner » dans LabVIEW. Si vous additionnez deux entiers, vous obtenez un entier, mais si vous additionnez deux nombres à virgule flottante, vous obtenez un nombre à virgule flottante. Il en va de même pour les types composés comme les tableaux et les clusters. D’autres éléments, comme les registres à décalage, suivent des règles plus complexes en termes de type. Dans le cas de la primitive « additionner », le type de sortie est déterminé à partir des types d’entrées, et on dit que le type se « propage » à travers le diagramme, d’où le nom de l’algorithme.
Cet exemple de la primitive « additionner » illustre également la tâche de vérification de syntaxe qui incombe à l’algorithme de propagation de type. Supposons que vous câbliez un entier et une chaîne à une primitive « additionner » : que se passerait-il ? Dans ce cas, l’addition de ces valeurs n’a aucun sens. Par conséquent, l’algorithme de propagation de type renvoie une erreur et indique que le VI est incorrect. La flèche d’exécution de celui-ci devient alors une flèche brisée.
Représentations intermédiaires : quoi et pourquoi
Une fois que la propagation de type a décidé qu’un VI était valide, la compilation se poursuit et le VI est traduit en DFIR. Examinons dans un premier temps les représentations intermédiaires (IR) de manière générale avant de rentrer dans les détails de la DFIR.
Une IR est une représentation du programme de l’utilisateur manipulée à mesure que la compilation passe par différentes phases. La notion d’IR est largement répandue dans la littérature consacrée aux compilateurs modernes et peut s’appliquer à tous les langages de programmation.
Prenons quelques exemples. Il existe à l’heure actuelle toute une variété d’IR populaires. L’arbre de syntaxe abstraite (AST) et le code à trois adresses sont deux exemples courants.
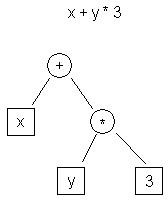 | t0 <- y t1 <- 3 t2 <- t0 * t1 t3 <- x t4 <- t3 + t2 |
| Figure 1. Exemple de l’IR de l’arbre de syntaxe abstraite | Tableau 1. Exemple de l’IR du code à trois adresses |
La Figure 1 montre la représentation d’un arbre de syntaxe abstraite de l’expression « x + y * 3, » tandis que le Tableau 1 montre la représentation de l’IR d’un code à trois adresses.
Une différence évidente entre ces deux représentations est que l’arbre de syntaxe abstraite est de niveau plus élevé. Il est plus proche de la représentation source du programme (C) que de la représentation cible (code machine). Par opposition, le code à trois adresses est bas niveau et ressemble à un assembly.
Les représentations haut niveau et bas niveau présentent toutes deux des avantages qui leur sont propres. Par exemple, des analyses comme l’analyse de dépendance peuvent être plus faciles à effectuer sur une représentation haut niveau comme l’arbre de syntaxe abstraite que sur une représentation bas niveau comme le code à trois adresses. D’autres optimisations, comme l’allocation de registres ou la planification d’instructions, sont le plus souvent effectuées sur une représentation bas niveau comme le code à trois adresses.
Comme les diverses IR ont des faiblesses et des points forts différents, de nombreux compilateurs (y compris celui de LabVIEW) ont recours à plusieurs d’entre elles. Dans le cas de LabVIEW, la DFIR est utilisée en tant qu’IR de haut niveau, tandis que celle de la LLVM est utilisée comme IR de bas niveau.
DFIR
Dans LabVIEW, la représentation haut niveau est la DFIR ; hiérarchique et graphique, elle ressemble au code G lui-même. Comme le G, la DFIR est composée de différents nœuds qui contiennent chacun des terminaux. Ces terminaux peuvent être connectés les uns aux autres. Certains nœuds comme les boucles contiennent des diagrammes, qui à leur tour peuvent contenir d’autres nœuds.
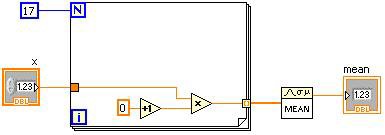
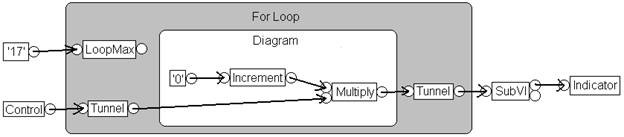
Figure 2. Code G LabVIEW et graphe DFIR correspondant
La Figure 2 montre un VI simple accompagné de sa représentation DFIR initiale. Lors de sa création, le graphe DFIR d’un VI est une traduction directe du code G, et les nœuds qu’il contient correspondent généralement élément par élément aux nœuds dans le code G. À mesure que la compilation progresse, les nœuds DFIR peuvent être déplacés ou séparés, ou encore de nouveaux nœuds de DFIR peuvent être insérés. L’un des avantages clés de la DFIR est qu’elle préserve les caractéristiques telles que le parallélisme inhérent au code G. Le parallélisme représenté dans le code à trois adresses, en revanche, est plus difficile à discerner.
La DFIR présente deux avantages significatifs pour le compilateur LabVIEW. Tout d’abord, la DFIR sépare l’éditeur de la représentation du VI utilisée par le compilateur. Ensuite, La DFIR sert de hub commun pour le compilateur qui a plusieurs transformations haut et bas niveaux. Examinons de plus près chacun de ces avantages.
Le graphe DFIR sépare l’éditeur de la représentation utilisée par le compilateur
Avant l’introduction de la DFIR, LabVIEW disposait d’une seule représentation du VI qui était partagée par l’éditeur et le compilateur. Cela empêchait le compilateur de modifier la représentation au cours du processus de compilation, ce qui, par conséquent, rendait toute optimisation du compilateur difficile à apporter.

Figure 3. La DFIR fournit un framework grâce auquel le compilateur optimise votre code
La Figure 3 montre un graphe DFIR pour le VI introduit précédemment. Ce graphe correspond à un stade plus avancé du processus de compilation, après décomposition et optimisation résultant de plusieurs transformations. Comme vous pouvez le constater, l’aspect de ce graphe est assez différent du précédent. Par exemple :
- Les transformations de décomposition ont supprimé les nœuds de commande, indicateur et sous-VI et les ont remplacé par de nouveaux nœuds (UIAccessor, UIUpdater, FunctionResolver et FunctionCall)
- L’extraction de code invariant des boucles a déplacé l’incrément et les nœuds « multiplier » à l’extérieur du corps de la boucle
- Le créateur de blocs (clumper) a injecté un nœud YieldIfNeeded à l’intérieur de la boucle For. En conséquence, le thread en cours partage l’exécution avec d’autres éléments en concurrence
Les transformations seront traitées plus en détail ultérieurement.
La représentation intermédiaire de la DFIR sert de hub commun pour les multiples transformations haut et bas niveaux du compilateur
LabVIEW fonctionne avec des cibles diverses et variées, qui, pour certaines, sont radicalement différentes les unes des autres : par exemple, un PC de bureau x86 et un FPGA de Xilinx. De même, LabVIEW propose plusieurs modèles de calcul à l’utilisateur. Outre la programmation graphique en G, LabVIEW offre des mathématiques textuelles en MathScript, par exemple. Cela se traduit par de nombreuses transformations haut et bas niveaux, qui ont toutes besoin de travailler avec le compilateur LabVIEW. Recourir à la DFIR en tant que représentation intermédiaire commune que toutes les transformations haut niveau produisent et que toutes les transformations bas niveau utilisent facilite la réutilisation entre les différentes combinaisons. Par exemple, une amélioration de la réduction des constantes qui s’exécute sur un graphe DFIR peut être écrite une seule fois et ensuite être appliquée sur des cibles de bureau, temps réel, FPGA et embarquées.
Les décompositions de la DFIR
Une fois dans la DFIR, le VI subit dans un premier temps une série de transformations de décomposition. Les transformations de décomposition ont pour objectif de réduire ou normaliser le graphe DFIR. Par exemple, la décomposition de tunnels de sortie non câblés trouve des tunnels de sortie sur les structures Conditions et Événement qui ne sont pas câblés et qui sont configurés sur « Utiliser la valeur par défaut si non câblé ». Pour ces terminaux, la transformation dépose une constante avec la valeur par défaut et la relie au terminal, rendant ainsi le comportement « Utiliser la valeur par défaut si non câblé » explicite dans le graphe DFIR. Des passes ultérieures du compilateur peuvent ensuite traiter tous les terminaux de manière identique et assumer qu’ils ont tous des entrées câblées. Dans ce cas de figure, la caractéristique « Utiliser la valeur par défaut si non câblé » du langage a été « supprimée par compilation » en réduisant la représentation à une forme plus fondamentale.
Cette idée peut également être appliquée à des caractéristiques de langage plus complexes. Par exemple, une transformation de décomposition est utilisée pour réduire le nœud de rétroaction en registres à décalage sur une boucle While. Une autre décomposition met en œuvre la boucle For parallèle sous la forme de plusieurs boucles For séquentielles avec de la logique supplémentaire pour diviser les entrées en éléments parallélisables pour les boucles séquentielles et réunir à nouveau les éléments après coup.
Nouvelle caractéristique de LabVIEW 2010, l’inlining de sous-VI (ou incorporation de sous-VI), est également implémentée en tant que décomposition DFIR. Au cours de cette phase de compilation, le graphe DFIR des sous-VI désignés comme « inline » est inséré directement dans le graphe DFIR du VI appelant. Outre l’économie du temps système correspondant à l’appel des sous-VI, l’inlining offre des opportunités d’optimisation supplémentaires en réunissant l’appelant et l’appelé dans un seul et même graphe DFIR. Prenons comme exemple ce VI simple qui appelle le TrimWhitespace.vi depuis vi.lib.
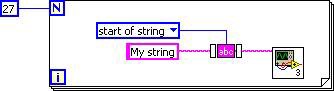
Figure 4. Exemple de VI simple pour mettre en évidence les optimisations liées à la DFIR
Le TrimWhitespace.vi est défini dans vi.lib ainsi :
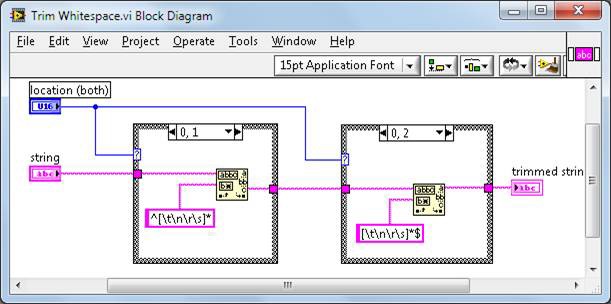
Figure 5. Diagramme TrimWhitespace.vi
Le sous-VI est incorporé au VI appelant, ce qui se traduit par un graphe DFIR équivalant au code G suivant.
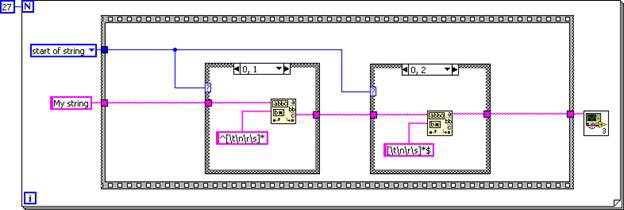
Figure 6. Code G correspondant au graphe DFIR du TrimWhitespace.vi incorporé
Maintenant que le diagramme des sous-VI est incorporé dans le diagramme de l’appelant, l’élimination du code non accessible et du code mort peuvent simplifier le code en général. La première structure Condition s’exécute toujours, tandis que la seconde ne s’exécute jamais.
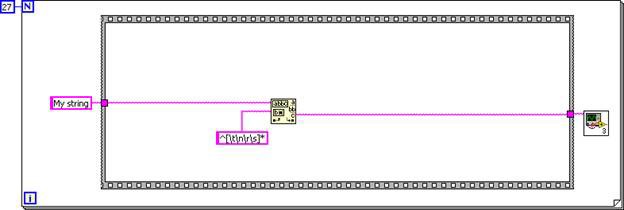
Figure 7. Les structures Condition peuvent être supprimées, car la logique d’entrée est constante
De même, l’extraction de code invariant des boucles déplace la primitive du filtre hors de la boucle. Le graphe DFIR final correspond au code G suivant.
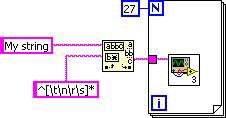
Figure 8. Code G correspondant au graphe DFIR final
Comme le TrimWhitespace.vi est désigné par défaut comme étant incorporé en LabVIEW 2010, tous les VI l’utilisant bénéficient automatiquement de cette optimisation.
Optimisations au niveau de la DFIR
Une fois que le graphe DFIR est entièrement décomposé, les passes de l’optimisation DFIR commencent. Et davantage d’optimisations sont effectuées plus tard au cours de la compilation LLVM. Ce paragraphe n’aborde que quelques-unes des nombreuses optimisations. Chacune de ces transformations est une optimisation de compilateur courante, il devrait donc être facile de trouver de plus amples informations sur l’une de ces optimisations en particulier.
Élimination du code non accessible
Le code qui ne peut jamais s’exécuter est non accessible. Supprimer le code non accessible n’accélère pas directement votre temps d’exécution, mais cela rend votre code plus compact et améliore les temps de compilation, car le code supprimé n’est plus jamais traversé lors des passes de compilation ultérieures.
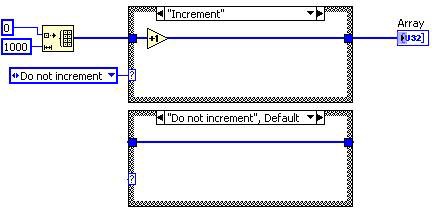
Avant l’élimination du code non accessible

Après l’élimination du code non accessible
Figure 9. Code G correspondant à la décomposition au niveau de la DFIR de l’élimination du code non accessible
Le diagramme du cas « Ne pas incrémenter » de la structure Condition n’est jamais exécuté. C’est la raison pour laquelle la transformation supprime cette condition. Comme la structure Condition n’a plus qu’un seul cas, elle est remplacée par une structure Séquence. L’élimination du code mort supprime ensuite le cadre et la constante d’énumération.
Extraction de code invariant des boucles
L’extraction de code invariant des boucles identifie le code à l’intérieur d’une boucle que vous pouvez déplacer en toute sécurité vers l’extérieur. Comme le code déplacé est moins souvent exécuté, la vitesse d’exécution globale s’en trouve améliorée.
Transformation d’extraction de code invariant des boucles | Après la transformation d’extraction de code invariant des boucles |
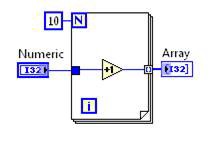
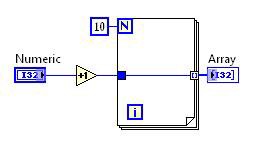
Figure 10. Code G correspondant à la décomposition au niveau de la DFIR d’extraction de code invariant de boucles
Dans ce cas de figure, l’opération d’incrémentation est déplacée à l’extérieur de la boucle. La boucle subsiste de façon à ce que le tableau puisse être construit, mais le calcul n’a pas besoin d’être répété à chaque itération.
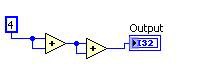
Élimination de sous-expressions redondantes
L’élimination de sous-expressions redondantes identifie les calculs qui se répètent, effectue le calcul une fois pour toutes et réutilise les résultats obtenus.
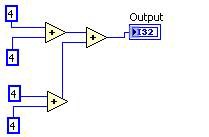
Avant Après
Figure 11. Code G correspondant à la décomposition au niveau de la DFIR d’élimination de sous-expressions redondantes
Réduction des constantes
La réduction des constantes détermine les parties du diagramme qui sont constantes au cours de l’exécution et qui peuvent donc être déterminées à l’avance.
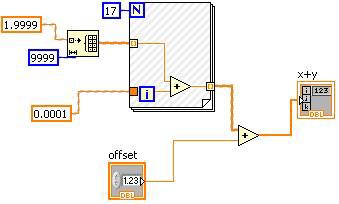
Figure 12. La réduction des constantes peut être visualisée dans le diagramme LabVIEW
Les hachures sur le VI de la Figure 12 indiquent la portion soumise à la réduction des constantes. Dans ce cas, la commande « offset » ne peut pas être soumise à l’algorithme de réduction des constantes, mais l’autre opérande de la primitive plus, y compris la boucle For, peut être remplacé par une valeur constante.
Déroulage de boucle
Le déroulage de boucle réduit le temps système des boucles en répétant plusieurs fois le code contenu dans une boucle dans le code généré et en réduisant d’autant le nombre total d’itérations. Outre la réduction du temps système des boucles, cela offre de nouvelles opportunités d’optimisation en contrepartie d’une certaine augmentation de la taille du code.
Élimination du code mort
Le code mort est du code superflu. La suppression du code mort accélère le temps d’exécution, car le code supprimé n’est plus exécuté.
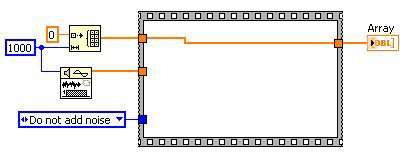
Le code mort est généralement produit par la manipulation du graphe DFIR par des transformations que vous n’avez pas écrites directement. Prenons l’exemple suivant. L’élimination du code non accessible détermine que la structure Condition peut être supprimée. Cela « crée » du code mort que la transformation d’élimination du code mort devra supprimer.
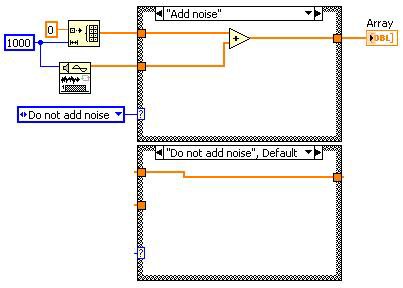
Avant
Après l’élimination du code non accessible
Après l’élimination du code mort
Figure 13. L’élimination du code mort peut réduire la quantité de code que le compilateur doit traverser
La plupart des transformations traitées ici sont interdépendantes les unes des autres ; exécuter une transformation est susceptible d’ouvrir des opportunités pour d’autres transformations.
Les transformations bas niveau de la DFIR
Une fois que le graphe DFIR est décomposé et optimisé, un certain nombre de transformations bas niveau s’exécutent. Ces transformations évaluent et annotent le graphe DFIR en préparation à la transformation finale du graphe DFIR en représentation intermédiaire LLVM.
Clumper, outil de création de blocs
L’algorithme de création de blocs analyse le parallélisme au niveau du graphe DFIR et regroupe les nœuds en blocs que vous pouvez exécuter en parallèle. Cet algorithme est étroitement lié au système d’exécution de LabVIEW, qui utilise le multitâche coopératif multithread. Chacun des blocs ainsi produits est planifié comme une tâche indépendante dans le système d’exécution. Les nœuds à l’intérieur des blocs s’exécutent en série selon un ordre défini. Le fait d’avoir un ordre d’exécution prédéterminé pour chaque bloc permet à l’outil de réutilisation des buffers de partager les allocations de données et d’améliorer considérablement les performances. Le créateur de blocs est également chargé d’insérer des interruptions dans les opérations très longues comme les boucles ou les E/S, de façon à ce que ces blocs puissent s’exécuter en mode multitâche avec les autres blocs.
Inplacer, outil de réutilisation des buffers
L’inplacer analyse le graphe DFIR et identifie lorsque vous pouvez réutiliser les allocations de données et lorsque vous devez effectuer une copie. Un fil de liaison dans LabVIEW peut être un simple scalaire 32 bits ou un tableau de 32 Mo. Dans un langage par flux de données tel que LabVIEW, il est indispensable de s’assurer que les données sont réutilisées autant que possible.
Étudions l’exemple suivant (notons que la mise au point du VI est désactivée pour obtenir de meilleures performances et optimiser l’espace mémoire utilisé).
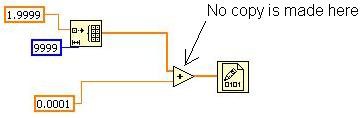
Figure 14. Exemple simple illustrant l’algorithme de réutilisation des buffers
Ce VI initialise un tableau, ajoute une valeur scalaire à chaque élément et l’écrit sur un fichier binaire. Combien devrait-il y avoir de copies du tableau ? LabVIEW doit d’abord créer le tableau, mais seule l’opération additionner utilise ce tableau et peut donc effectuer le calcul sur le même espace mémoire (in place). Ainsi une seule copie du tableau est nécessaire au lieu d’une allocation par fil de liaison. Cela fait une grande différence, aussi bien en termes de mémoire utilisée que de temps d’exécution, en particulier si le tableau est de grande envergure. Dans ce VI, l’inplacer reconnaît cette opportunité de fonctionner « en place » et configure le nœud additionner pour en tirer parti.
Vous pouvez observer ce comportement dans les VI que vous écrivez en utilisant l’outil « Afficher les allocations de buffer » dans Outils»Profil. L’outil ne montre pas d’allocation sur la primitive additionner, indiquant par là qu’aucune copie de données n’est effectuée et que l’opération additionner se fait en place.
C’est possible, car aucun autre nœud n’a besoin du tableau original. Si vous modifiez le VI comme le montre la Figure 15, l’inplacer doit effectuer une copie pour la primitive « additionner ». En effet, la seconde primitive Écrire dans un fichier binaire a besoin du tableau original et doit s’exécuter après la première primitive Écrire dans un fichier binaire. Avec cette modification, l’outil Afficher les allocations de buffer indique une allocation sur la primitive « additionner ».
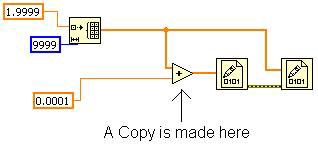
Figure 15. Le câblage du tableau original implique une copie en mémoire
Allocateur
Une fois que l’inplacer a identifié quels nœuds peuvent partager les mêmes emplacements de mémoire avec d’autres, l’allocateur se met en marche pour créer les allocations dont le VI a besoin pour s’exécuter. Cette mise en œuvre s’effectue en examinant chaque nœud et terminal. Les terminaux qui peuvent s’utiliser en place réutilisent des allocations au lieu d’en créer de nouvelles.
Générateur de code
Le générateur de code est le composant du compilateur qui convertit le graphe DFIR en instructions machines exécutables pour le processeur cible. LabVIEW traverse chaque nœud du graphe DFIR en suivant l’ordre du flux de données, et chaque nœud appelle une interface baptisée GenAPI, utilisée pour convertir le graphe DFIR en une forme de langage intermédiaire (IL) séquentiel décrivant les fonctionnalités de ce nœud. Le langage intermédiaire fournit un moyen indépendant de la plate-forme pour décrire le comportement bas niveau du nœud. Différentes instructions dans l’IL sont utilisées pour implémenter de l’arithmétique, lire et écrire dans la mémoire, effectuer des comparaisons et des branchements conditionnels, etc. Les instructions IL peuvent fonctionner soit sur la mémoire soit sur des valeurs conservées dans des registres virtuels qui sont utilisés pour enregistrer des valeurs intermédiaires. Parmi les exemples d’instructions IL, citons GenAdd, GenMul, GenIf, GenLabel et GenMove.
Dans LabVIEW 2009 et les versions précédentes, cette forme de langage intermédiaire était convertie directement en instructions machines (comme 80X86 et PowerPC) pour la plate-forme cible. LabVIEW utilisait un simple allocateur de registres à une seule passe pour mapper les registres virtuels aux registres machines physiques, et chaque instruction IL émettait un jeu figé dans le code d’instructions machines spécifiques pour l’implémenter dans chaque plate-forme cible supportée. Bien que d’une très grande rapidité, cette façon de procéder ad hoc produisait un code médiocre et ne se prêtait pas à l’optimisation. Représentation de haut niveau indépendante de la plate-forme, la DFIR est limitée dans le genre de transformations de code qu’elle peut supporter. Pour supporter l’ensemble des optimisations du code dans un compilateur moderne, LabVIEW a récemment adopté une technologie tierce libre appelée la LLVM.
LLVM
La LLVM (Low-Level Virtual Machine ou machine virtuelle bas niveau) est un framework de compilateur libre polyvalente et hautes performances, initialement inventée au cours d’un projet de recherche à l’Université de l’Illinois. La LLVM est désormais largement utilisée aussi bien dans l’enseignement que dans l’industrie en raison de son API évolutive et d’une politique de licence non restrictive.
Dans LabVIEW 2010, le générateur de code LabVIEW est refactorisé de façon à utiliser la LLVM pour générer du code machine cible. La représentation IL LabVIEW existante fournit un excellent point de départ, nécessitant la ré-écriture de seulement 80 instructions IL environ au lieu du plus grand nombre de primitives et nœuds DFIR supportés par LabVIEW.
Après la création du flux de code IL à partir du graphe DFIR d’un VI, LabVIEW examine chaque instruction IL et crée une représentation d’assembly LLVM équivalente. Le logiciel invoque différentes passes d’optimisation, puis utilise le framework LLVM Just-in-Time (JIT) afin de créer des instructions machines exécutables dans la mémoire. Les informations de réadressage machine de la LLVM sont converties dans une représentation LabVIEW, de sorte que lorsque vous enregistrez le VI sur disque et que vous le rechargez à une adresse de base mémoire différente, vous pouvez le corriger pour qu’il fonctionne au nouvel emplacement.
Parmi les optimisations de compilateur standards pour lesquelles LabVIEW utilise la LLVM, citons les suivantes :
- Instruction combining (la combinaison d’instructions)
- Jump threading
- Scalar replacement of aggregates
- Conditional propagation (la propagation conditionnelle)
- Tail call elimination
- Expression reassociation (la ré-association d’expression)
- Extraction de code invariant des boucles
- Loop unswitching and index splitting
- Induction variable simplification
- Loop unrolling (le déroulage de boucle)
- Global value numbering
- Dead store elimination
- Aggressive dead code elimination (l’élimination agressive du code mort)
- Sparse conditional constant propagation
Une explication complète de toutes ces optimisations sort du cadre de ce document, mais Internet, comme beaucoup de manuels sur les compilateurs, regorge d’informations à leur sujet.
Des tests de performance internes ont montré que l’introduction de la LLVM a accéléré le temps d’exécution des VI de 20 % en moyenne. Les résultats individuels dépendent de la nature des calculs effectués par le VI ; l’amélioration des performances de certains VI peut être considérablement supérieure, tandis que certains ne connaissent aucun changement. Par exemple, les VI qui utilisent la bibliothèque d’analyse avancée ou qui sont hautement dépendants du code déjà implémenté en C optimisé voient peu de différence en termes de performances. LabVIEW 2010 est la première version à utiliser la LLVM, et il reste un fort potentiel à exploiter pour de prochaines améliorations.
La DFIR et la LLVM fonctionnent en tandem
Vous avez peut-être remarqué que certaines de ces optimisations, comme l’extraction de code invariant des boucles et l’élimination du code mort, ont déjà été décrites comme le fruit de la DFIR. En réalité, il est avantageux d’exécuter certaines passes d’optimisation à maintes reprises et à différents niveaux du compilateur, car d’autres sont susceptibles d’avoir transformé le code de façon à offrir de nouvelles possibilités d’optimisation. Alors que la DFIR est une représentation intermédiaire de haut niveau, la LLVM est une IR de bas niveau, mais en fin de compte, les deux fonctionnent en tandem pour optimiser le code LabVIEW que vous écrivez pour l’architecture du processeur utilisée pour d’exécution du code.