From 11:00 PM CST Friday, Apr 11th - 1:30 PM CST Saturday, Apr 12th, ni.com will undergo system upgrades that may result in temporary service interruption.
We appreciate your patience as we improve our online experience.
From 11:00 PM CST Friday, Apr 11th - 1:30 PM CST Saturday, Apr 12th, ni.com will undergo system upgrades that may result in temporary service interruption.
We appreciate your patience as we improve our online experience.
Cet article présente les types de données de tableaux et de clusters et vous propose une introduction à la création et à la manipulation de tableaux et de clusters.
Un tableau, constitué d'éléments et de dimensions, est soit une commande, soit un indicateur. Il ne peut pas combiner commandes et indicateurs. Les éléments sont les données ou valeurs qui constituent le tableau. Une dimension est la longueur, la hauteur ou la profondeur d'un tableau. Les tableaux peuvent être très utiles lorsque vous travaillez avec un ensemble de données similaires et que vous souhaitez enregistrer un historique de calculs répétitifs.
Les éléments d'un tableau sont ordonnés. Chaque élément d'un tableau dispose d'une valeur d'indice correspondante, et vous pouvez utiliser l'indice du tableau pour accéder à un élément particulier du tableau. Dans le logiciel NI LabVIEW, l'indice de tableau commence à zéro. Cela signifie que si un tableau à une dimension (1D) contient n éléments, la gamme d'indices va de 0 à n – 1, où l'indice 0 pointe vers le premier élément du tableau et l'indice n – 1 pointe vers le dernier élément du tableau.
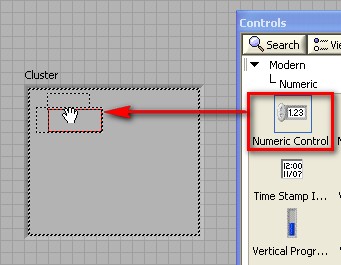
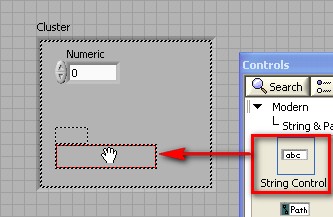
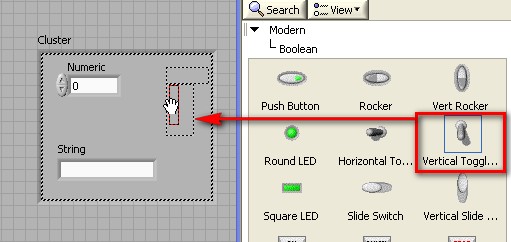
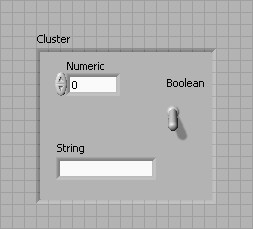
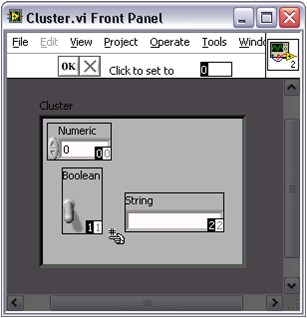
Les clusters regroupent des éléments de données de types différents. Le cluster d'erreur LabVIEW est un exemple de cluster ; il comprend une valeur booléenne, une valeur numérique et une chaîne. Les clusters sont semblables aux « record » et « struct » des langages de programmation textuels.
Tout comme les tableaux, un cluster peut être une commande ou un indicateur, mais il ne peut pas combiner des commandes et des indicateurs. La différence entre les clusters et les tableaux est qu'un cluster a une taille fixe, tandis qu'un tableau peut avoir une taille variable. De plus, un cluster peut contenir des types de données mixtes, alors qu'un tableau ne peut contenir qu'un seul type de données.
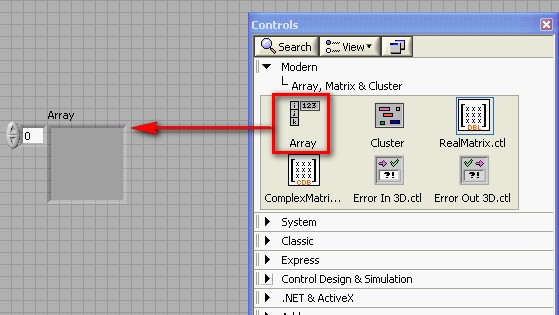
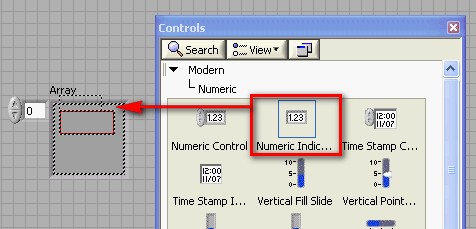
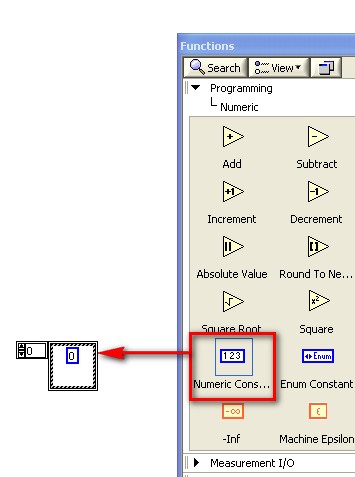
Pour créer un tableau dans LabVIEW, vous devez ajouter une enveloppe de tableau sur la face-avant puis ajouter un élément, comme une commande ou indicateur de type numérique, booléen ou waveform dans l'enveloppe du tableau.
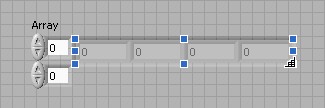
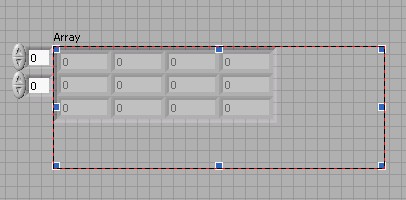
Ces étapes vous ont montré comment créer un tableau 1D. Un tableau 2D stocke des éléments dans une grille ou matrice. Chaque élément de tableau 2D dispose de deux valeurs d'indice correspondantes, un indice de ligne et un indice de colonne. Comme pour le tableau 1D, les indices de ligne et de colonne d'un tableau 2D commencent à zéro.
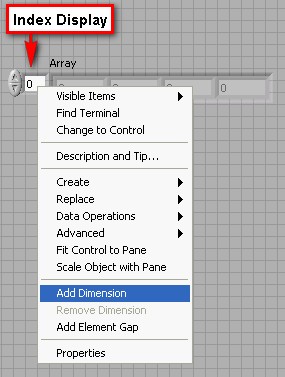
Pour créer un tableau à deux dimensions (2D), vous devez d'abord créer un tableau 1D, puis y ajouter une dimension. Revenez au tableau 1D que vous avez créé précédemment.
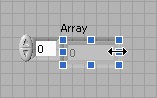
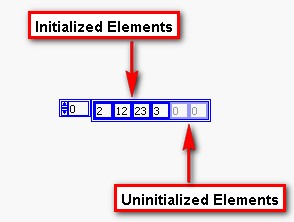
Jusque-là, les éléments numériques que vous avez créés dans le tableau sont des zéros grisés. Un élément de tableau grisé indique que l'élément est non initialisé. Pour initialiser un élément, cliquez dans l'élément et remplacez le 0 grisé par un nombre de votre choix.
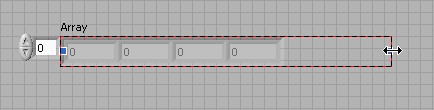
Les éléments peuvent être initialisés avec n'importe quelle valeur de votre choix. Vous pouvez choisir des valeurs différentes de celles indiquées ci-dessus.
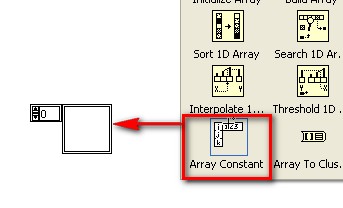
Vous pouvez utiliser une constante tableau pour stocker les données d'une constante ou pour effectuer une comparaison avec un autre tableau.
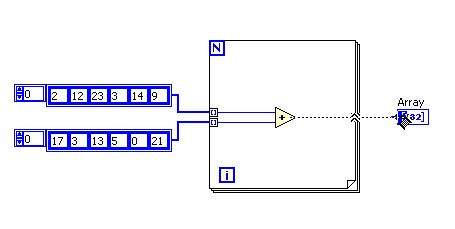
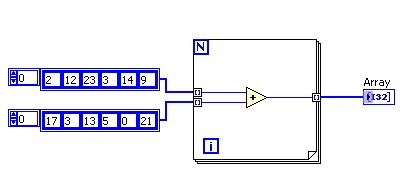
Si vous câblez un tableau comme entrée d'une boucle, LabVIEW fournit l'option de définir automatiquement le terminal de décompte de la boucle For en fonction du dimensionnement du tableau à l'aide de la fonctionnalité Auto-indexation. Vous pouvez activer ou désactiver la fonctionnalité Auto-indexation en cliquant avec le bouton droit sur le tunnel de boucle câblé au tableau et en sélectionnant Activer l'indexation (Désactiver l'indexation).
Si vous activez l'Auto-indexation, chaque itération de la boucle For reçoit l'élément correspondant du tableau.
Lorsque vous câblez une valeur en sortie de boucle For, la fonction Auto-indexation produit un tableau en sortie. La taille du tableau est égale au nombre d'itérations exécutées par la boucle For et celui-ci contient les valeurs de sortie de la boucle For.
Diagramme
Face-avant
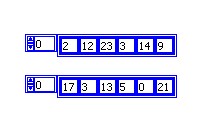
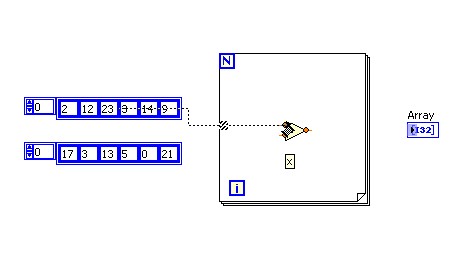
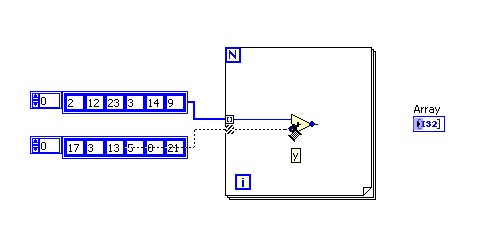
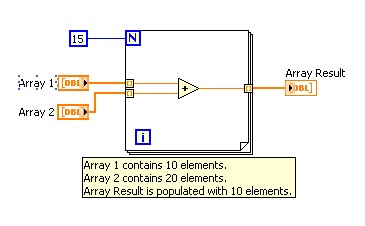
Sachez que si vous activez l'Auto-indexation sur plusieurs tunnels de boucle et câblez le terminal de décompte de la boucle For, le nombre d'itérations est égal à la plus petite des possibilités. Par exemple, dans la figure ci-dessous, le terminal de décompte de la boucle For est paramétré pour exécuter 15 itérations, le Tableau 1 contient 10 éléments et le Tableau 2 contient 20 éléments. Si vous exécutez le VI de la figure ci-dessous, la boucle For s'exécute 10 fois et le Résultat Tableau contient 10 éléments. Faites l'expérience et vérifiez par vous-même.
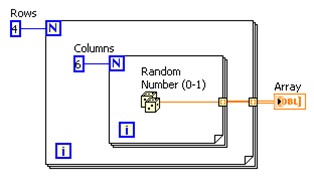
Vous pouvez créer un tableau 2D à l'aide de boucles For imbriquées et de l'Auto-indexation comme indiqué ci-dessous. La boucle extérieure crée les éléments de ligne, tandis que la boucle intérieure crée les éléments de colonne.
Vous pouvez désormais câbler les commandes numériques, de chaîne et booléennes à travers le diagramme avec un fil au lieu d'utiliser trois fils différents.
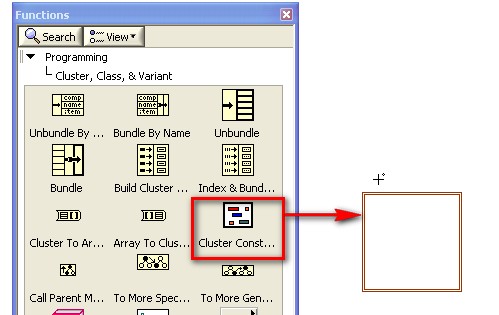
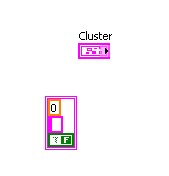
Tout comme les constantes tableau, vous pouvez utiliser une constante cluster pour stocker les données d'une constante ou pour effectuer une comparaison avec un autre cluster. Créez les constantes cluster de la même manière que les constantes tableau comme indiqué précédemment.
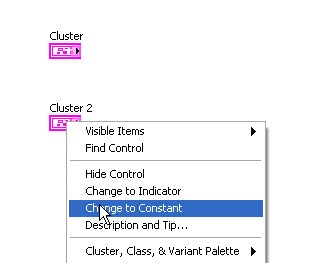
Si vous avez déjà une commande ou un indicateur cluster et souhaitez créer une constante cluster qui contient les mêmes types de données, créez une copie de la commande ou de l'indicateur cluster sur le diagramme. Ensuite, cliquez avec le bouton droit sur la copie et sélectionnez Changer en constante dans le menu local.
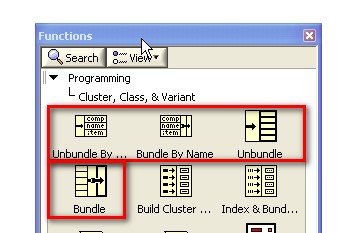
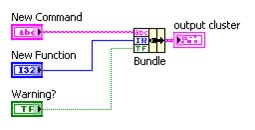
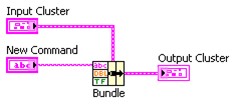
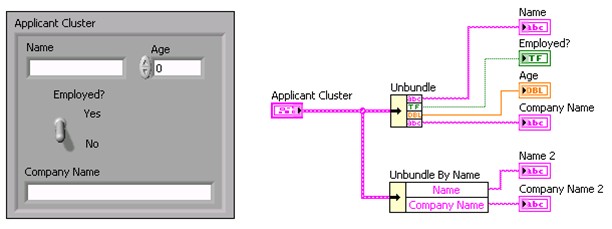
Ce tutoriel concerne quatre grandes fonctions de cluster principales, couramment utilisées pour la manipulation de clusters. Ces fonctions sont les suivantes : Assembler, Désassembler, Assembler par nom et Désassembler par nom.
Utilisez la fonction Assembler pour composer un cluster à partir d'éléments individuels. Pour câbler les éléments à la fonction Assembler, utilisez votre souris pour redimensionner la fonction ou cliquez avec le bouton droit sur la fonction et sélectionnez Ajouter une entrée dans le menu local.
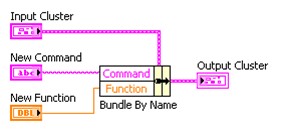
Utilisez la fonction Assembler par nom ou Assembler pour modifier un cluster existant. Vous pouvez redimensionner la fonction Assembler par nom de la même manière que la fonction Assembler.
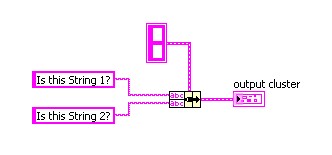
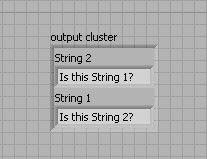
La fonction Assembler par nom est très utile pour modifier les clusters existants car elle vous permet de savoir exactement quel élément du cluster vous modifiez. Prenez l'exemple d'un cluster qui contient deux éléments chaîne appelés « Chaîne 1 » et « Chaîne 2 ». Si vous utilisez la fonction Assembler pour modifier le cluster, les terminaux de la fonction apparaissent sous forme de « abc » de couleur rose. Vous ne savez pas quel terminal modifie la « Chaîne 1 » et quel terminal modifie la « Chaîne 2 ».
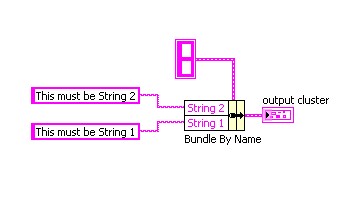
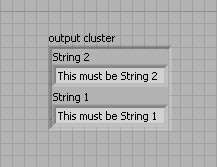
Cependant, si vous utilisez la fonction Assembler par nom pour modifier le cluster, les terminaux de la fonction affichent les noms des éléments, vous permettant ainsi de savoir quel terminal modifie la « Chaîne 1 » et quel terminal modifie la « Chaîne 2 ».
Utilisez la fonction Désassembler pour décomposer un cluster en ses différents éléments. Utilisez la fonction Désassembler par nom pour renvoyer des éléments de cluster dont vous spécifiez le nom. Vous pouvez également redimensionner ces fonctions pour plusieurs éléments comme pour les fonctions Assembler et Assembler par nom.
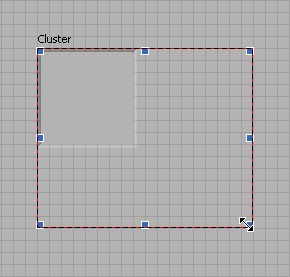
Les éléments du cluster ont un ordre logique indépendant de leur position dans l'enveloppe du cluster. Le premier objet que vous placez dans le cluster est l'élément 0, le deuxième est l'élément 1 et ainsi de suite. Si vous supprimez un élément, l'ordre est automatiquement ajusté. L'ordre du cluster détermine l'ordre dans lequel les éléments apparaissent comme des terminaux sur les fonctions Assembler et Désassembler dans le diagramme. Vous pouvez afficher et modifier l'ordre des éléments d'un cluster en faisant un clic droit sur le cadre du cluster et en sélectionnant Ordonner les commandes dans le cluster dans le menu local.
Les cases blanches sur chaque élément affichent son rang actuel dans l'ordre du cluster. Les cases noires sur chaque élément affichent le nouveau rang de l'élément dans l'ordre du cluster. Pour modifier le rang d'un élément de cluster, entrez le nouveau numéro d'ordre dans le champ Cliquez pour mettre à et cliquez sur l'élément. L'ordre des éléments du cluster est modifié, et l'ordre des autres éléments du cluster est automatiquement ajusté. Sauvegardez les changements en cliquant sur le bouton Confirmer sur la barre d'outils. Rétablissez l'ordre d'origine en cliquant sur le bouton Annuler.
Help us improve your future ni.com experience.
Did you find the documentation you were looking for?