Développement d’applications avec le protocole Modbus
Aperçu
Contenu
- Choix du protocole et remarques sur la conception
- Structure de messagerie Modbus
- Fiabilité des interactions Modbus
- Communication non sollicitée
- Contrôle et déterminisme du réseau
- Communication orientée balises et organisation des données
- Utilisation du réseau
- Remarques concernant la sécurité
- Remarques sur l’implémentation
- Application ou Bibliothèque
- Planification des requêtes
- Disponibilité de types
- Protocole Modbus avec NI OPC Servers
- Protocole Modbus avec serveurs d’E/S
- Protocole Modbus avec des API bas niveau
- Avantages et inconvénients du protocole Modbus
Pourquoi utiliser le protocole Modbus ?
Le Modbus est un protocole ouvert, très répandu et relativement simple d’utilisation. Son application ne comporte que peu de restrictions, mais il présente tout de même quelques inconvénients. Dans la plupart des cas, ce sont les matériels (capteurs ou autres) qui imposent l’usage du Modbus à l’utilisateur. Que vous soyez obligé de l’utiliser ou que vous ayez d’autres alternatives, il est important que vous preniez connaissance des avantages et des inconvénients inhérents à ce protocole.
Si le Modbus convient à votre projet, alors vous devez savoir l’utiliser. Quelles sont les options d’implémentation possibles ? Comment concevoir une application qui permette de tirer le meilleur parti de ce protocole ?
Choix du protocole et remarques sur la conception
La couche application Modbus est implémentée comme une conception de type maître-esclave basée sur un système de requête-réponse, servant à transmettre des données point à point dans différentes couches réseau. Cette conception fondamentale est efficace, mais peut présenter des inconvénients dans le cadre de certaines applications.
Structure de messagerie Modbus
Le Modbus est un protocole de type requête-réponse qui permet aux systèmes de supervision et d’acquisition de données (SCADA) d’interagir avec des matériels d’automatisation. Le matériel cible doit envoyer une réponse à chaque requête envoyée. Il y a donc une réponse par requête. De plus, les requêtes proviennent souvent d’une seule source qui cible un seul matériel. Ces systèmes se distinguent par le fait qu’ils contiennent d’une part un dispositif client qui génère une requête et attend sa réponse, et d’autre part un serveur qui analyse les requêtes du client, les gère, puis renvoie une réponse (cf. Figure 1). Dans le jargon relatif au Modbus, le client est souvent appelé « maître », étant donné qu’il est généralement l’hôte SCADA. Le serveur, quant à lui, est appelé « esclave », et correspond généralement à un capteur ou à un contrôleur d’automatisation.
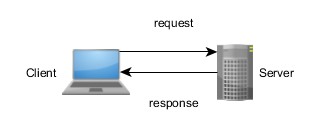
Figure 1: Un modèle de type serveur-client basé sur un système de requête-réponse
Fiabilité des interactions Modbus
La structure de messagerie Modbus est similaire à celle définie par le protocole HTTP. Elle présente l’avantage de ne pas nécessiter de couche réseau particulièrement fiable. Si le client (le maître) envoie une requête et ne reçoit pas de réponse, celui-ci en déduit qu’un problème est survenu et renvoie la requête. En protocole HTTP, cela reviendrait à cliquer sur le bouton « Actualiser » dans un navigateur Web. Si vous envoyez plusieurs requêtes répétées sans recevoir de réponse du serveur, vous devez envisager la possibilité que ce dernier soit en panne et suspendre temporairement vos tentatives d’accès à celui-ci. Ce comportement est similaire à celui que présentent certains serveurs OPC tels que KEPServerEX ou NI OPC Servers lorsque la communication Modbus est perdue. Bien que ce procédé ne protège pas d’une éventuelle perte de contrôle, il permet néanmoins de s’assurer que les matériels maîtres en soient informés si la situation se présente, afin qu’ils puissent prendre les mesures appropriées (comme procéder à une interruption avec protection simultanée ou utiliser un matériel redondant pour maintenir le contrôle). En revanche, cela ne vaut ni pour l’esclave, ni pour le serveur.
Étant donné que toutes les requêtes doivent provenir du matériel maître, un esclave intelligent ne peut pas être informé avec certitude que la communication a été perdue. Si l’esclave ne reçoit aucune requête, cela peut vouloir dire que le réseau ou le maître n’est pas opérationnel, ou que ce dernier a décidé d’arrêter d’envoyer des requêtes. Ce manque de fiabilité concernant les informations sur l’état peut être corrigé de différentes façons, mais il faut pour cela que le développeur du système en reconnaisse la nécessité.
La solution la plus courante à ce problème consiste à utiliser des matériels équipés d’horloges de surveillance (watchdogs). Si aucune requête n’est reçue dans un délai imparti, le matériel esclave estime qu’une action a échoué et se met en état de sécurité. Selon le matériel et l’application en question, cela peut être soit bénéfique, soit préjudiciable au contrôle global du système.
La solution de l’horloge de surveillance a néanmoins ses limites, puisqu’elle ne fait que confirmer la bonne réception des requêtes. Vous pouvez utiliser des schémas de plus en plus complexes, mais l’une des méthodes les plus simples et les plus efficaces consiste à implémenter un « heartbeat » (battement régulier) au niveau registre. Si le matériel le supporte, ou si vous développez un nouveau matériel en partant de rien, cette méthode garantit une communication constante entre le maître et l’esclave au niveau de l’application. En outre, si le code de contrôle sur le maître est chargé de changer la valeur des « heartbeats » et que le code de contrôle sur l’esclave doit la lire, la valeur des « heartbeats » constitue un moyen simple de confirmer le fonctionnement normal du système. Les fonctionnalités du système, du code de contrôle du maître à travers les couches réseaux jusqu’à la boucle de contrôle de l’esclave, sont vérifiées par ce test de « heartbeat » au niveau registre. Un autre registre, modifié sur l’esclave et lu sur le maître, peut également être utilisé pour indiquer qu’une communication a lieu dans l’autre sens.
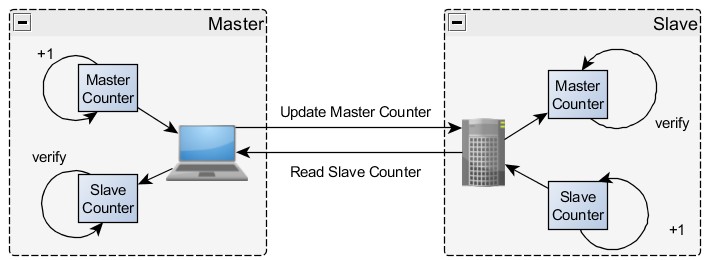
Figure 2: Implémentation simple d’un « heartbeat »
Communication non sollicitée
La nature de cette architecture maître-esclave implique également que les esclaves Modbus ne peuvent fournir aucune donnée non sollicitée à un maître. Bien que ce dernier puisse implémenter une architecture en fonction d’événements pour envoyer des données à l’esclave, il doit sans arrêt interroger les esclaves à une fréquence donnée pour récupérer de nouvelles données. Cette opération nécessite un temps système considérable si les changements sont limités en termes de bande passante du réseau et d’utilisation du processeur du maître.
Cette conception est particulièrement efficace dans le cas où des informations doivent être fréquemment mises à jour (si celles-ci proviennent d’un capteur de température, par exemple). Comme ces données varient constamment, il est logique de scruter régulièrement l’application. En revanche, dans le cas d’éléments de données peu sujets aux variations – tels que les bits d’alarmes ou les commutateurs physiques d’état – la surveillance est plus efficace si l’on attend qu’un changement de valeur se produise avant de mettre le maître à jour. Le protocole Modbus requiert malgré tout que chaque valeur soit consultée périodiquement.
Contrôle et déterminisme du réseau
Puisque l’esclave est incapable d’envoyer des données non sollicitées à un maître, Modbus permet un niveau de contrôle sur le réseau en fonction des besoins de certaines applications. Sur un réseau fragile, un protocole de requête-réponse peut garantir que le maître est le seul matériel en mesure de déterminer le moment auquel la communication a lieu. S’il est correctement configuré, cela signifie que le maître peut éliminer les collisions de paquets et garantir un meilleur déterminisme.
Cela peut également présenter des avantages plus globaux, puisqu’un système de contrôle dans une communication réseau de ce type est toujours à un état de sécurité. Si des informations en fonction d’événements sont transmises sur le réseau par l’un des esclaves, il est probable que du jitter soit introduit dans le système. Bien que certaines applications le tolèrent, l’usage d’un mécanisme strict de scrutation pour transférer des données peut réduire ce risque.
Communication orientée balises et organisation des données
Les données Modbus s’appuient sur le concept de balises ou variables. Ces éléments de données (registres de maintien, registres d’entrée, coils et entrées discrètes) sont nommés différemment dans le protocole, mais l’idée est la même. Ces balises sont des éléments de données sur lesquels il est possible d’écrire et qui sont lisibles à tout moment, mais qui fournissent uniquement leur valeur actuelle. Cela est parfaitement cohérent pour de nombreuses applications. Cependant, l’implémentation de concepts comme les événements, les messages ou les buffers de mémoire de type « premier entré, premier sorti » (FIFO) peut être difficile.
Le Modbus définit quatre banques de données – les quatre types cités plus haut – qui stockent la grande majorité des informations transmises par le protocole. Chaque requête envoyée par un maître ne peut effectuer qu’une seule opération sur une seule banque de données, c’est à dire qu’une requête peut soit lire la banque de coils, soit y écrire, mais pas les deux. Il existe toutefois des exceptions : le code fonctionnel 23 permet notamment à un maître d’écrire et de lire des registres de maintien pendant un même cycle de requête-réponse, mais ce code n’est pas couramment implémenté. Il est nécessaire de consulter la documentation des matériels maître et esclave pour vérifier si ce code fonctionnel est exploitable.
Il est également important de comprendre que l’accès aux données contenues dans une banque particulière ne peut se faire que de manière séquentielle, et selon la limite de taille de paquets définie par le protocole Modbus. Cette limite correspond généralement à 240, voire 250 octets de données de charge, mais dépend de la fonction utilisée. Il est donc extrêmement important de concevoir soigneusement les banques de registres.
Une application donnée peut par exemple nécessiter le transfert de grandes quantités de données à une fréquence élevée. Dans ce cas, il est préférable de limiter le nombre de requêtes requises. Étant donné que l’accès aux données doit se faire de manière séquentielle, il serait logique que cette application concentre le plus de données possible dans une seule banque de registres et réunisse ces données en laissant un minimum d’éléments de données inutilisés.
Une autre application pourrait disposer d’un esclave plus complexe qui permettrait un contrôle local. Dans ce cas, certaines données seraient lues à une fréquence élevée et d’autres seraient surveillées de manière périodique. Les données seraient alors regroupées par vitesse de transfert : celles à mise à jour rapide devraient être réunies en un seul endroit, tandis que celles à mise à jour lente devraient être organisées par blocs pour faciliter la lecture ou la mise à jour d’un ensemble de données particulier par une seule requête.
Prenons l’exemple d’un ensemble de cinq valeurs de données à mise à jour rapide (F1-F5) et de cinq valeurs à mise à jour lente (S1-S5). Ajoutons que S1, S2 et S3 correspondent à un module de code donné, et S4 et S5 à un autre – ce qui implique qu’ils ne sont pas mis à jour en même temps. La Figure 3 montre que l’organisation idéale dans ce cas donne au maître la possibilité de lire les données à mise à jour rapide au cours d’une seule requête, puis de lire les ensembles de données à mise à jour lente, si nécessaire.
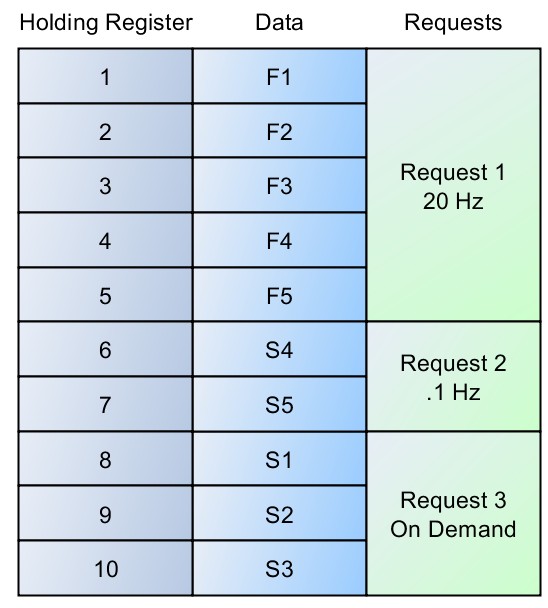
Figure 3: Bonne organisation de données
Si l’on n’y prend garde, un ensemble de données pourrait facilement être organisé comme le montre la figure 4. Dans ce cas, on est passé d’un peu plus de 20 requêtes par seconde à plus de 80 requêtes par seconde. En fait, un petit ensemble de données lit plus efficacement tout en un seul bloc. Cependant, ces méthodes peuvent rapidement s’avérer incompatibles avec un système complexe.
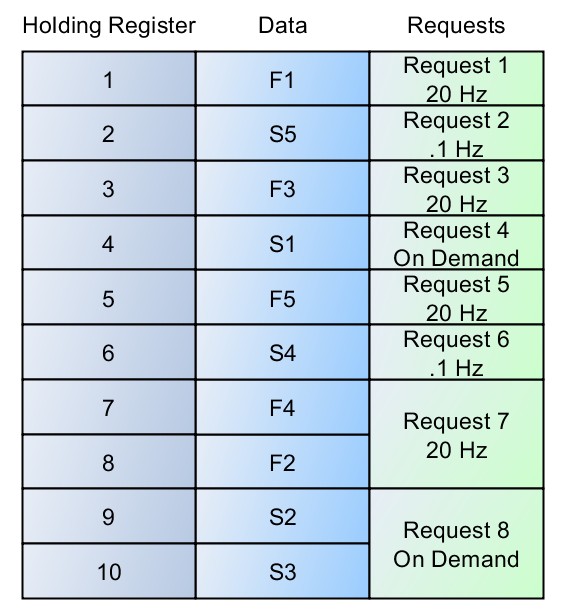
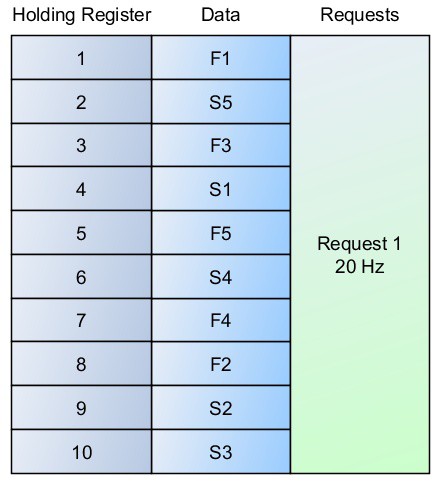
Figure 4: Mauvaise organisation des données
Numérotage de balises
Bien qu’en interne, il soit possible d’accéder aux données de chaque banque Modbus en utilisant une valeur d’adresse allant de 0 à 65 535, la documentation fait plus souvent référence aux éléments de données qui utilisent un schéma d’adressage courant. Dans ce type de schémas, l’adresse de l’élément de données est précédée d’un nombre qui indique la banque à laquelle accéder. Le Tableau 1 indique les préfixes en question.
| Bloc de données | Préfixe |
| Bobines | 0 |
| Entrées discrètes | 1 |
| Registres d’entrée | 3 |
| Registres internes | 4 |
Tableau 1: Préfixes d’accès aux données
En fonction de la documentation consultée, l’adressage commence soit à zéro, soit à un, et utilise une largeur fixe dont la valeur se situe entre quatre et six. Autrement dit, différents documents peuvent tous faire référence au même registre interne d’entiers comme 4005, 40004 et 400005. La documentation doit définir le schéma d’adressage utilisé. Cette information doit être mentionnée pour tout développement de système.
Utilisation du réseau
Les protocoles de type requête-réponse ne font pas forcément très bon usage de la bande passante du réseau. Si une requête envoyée par le maître demandant la lecture de certaines données nécessite évidemment une réponse, ce n’est pas le cas des requêtes demandant l’écriture de données. Cependant, le protocole d’application Modbus requiert qu’une réponse soit donnée à chaque requête. Cela implique qu’un paquet Modbus complet soit formé, et qu’il comprenne des données de protocole, des données d’application, ainsi que toutes les données de réseau requises. Cela signifie également que le processus de requête de données et leur réception sous forme de réponse peut prendre beaucoup plus de temps qu’une simple opération de diffusion de données, en raison de la latence du réseau, de la durée du traitement par l’esclave, et des éventuelles collisions ou interférences sur le réseau.
L’organisation des données dont il est question plus haut influence d’autant plus ce comportement. Si les données sont mal organisées dans l’espace mémoire Modbus, le nombre de cycles de requête-réponse peut considérablement augmenter. En raison des problèmes de latence, il existe une vitesse limite à laquelle peuvent se dérouler les cycles de requête-réponse, même sans interférences sur le réseau. En conséquence, la réduction du nombre de requêtes requises pour que le maître et l’esclave interagissent est l’un des moyens les plus efficaces pour améliorer les performances du système.
Remarques concernant la sécurité
Le protocole Modbus garantit un niveau de sécurité très faible, voire nul. Auparavant, de par leur nature confinée, la seule façon d’infiltrer les réseaux industriels était de porter physiquement atteinte à leur sécurité. Maintenant que les réseaux sont de plus en plus interconnectés, la sécurité représente un problème beaucoup plus sérieux. Au cours des dernières années, plusieurs schémas ont été établis pour sécuriser la communication du protocole Modbus. Cependant, ces derniers provoquent généralement des problèmes de compatibilité entre les réseaux Modbus et les matériels.
Remarques sur l’implémentation
La fonctionnalité globale d’un système donné varie également en fonction de l’implémentation de drivers spécifiques choisie. Généralement, les maîtres Modbus sont intégrés à une application soit par l’intermédiaire d’une bibliothèque, soit via un outil autonome tel qu’un serveur OPC. Les esclaves Modbus sont quant à eux souvent intégrés dans un matériel par l’intermédiaire d’une sorte de bibliothèque, ou développés dans le cadre du micrologiciel d’un matériel. Dans tous les cas, il est important de connaître la variété d’implémentations possibles pour choisir la mieux adaptée à une application donnée.
Application ou Bibliothèque
Généralement, les applications comme KEPServerEX ou NI OPC Servers sont plus complètes que les bibliothèques, mais permettent moins de contrôle. Les applications de serveur OPC peuvent par exemple être configurées pour fournir des éléments de données spécifiques à une vitesse déterminée, et toutes deux peuvent convertir des données Modbus brutes en un type de données défini. Elles sont cependant limitées dans le sens où il est impossible de générer et d’envoyer directement des requêtes Modbus. Toutes les requêtes passent par l’application et les options de configuration sont restreintes. En revanche, une bibliothèque fournit généralement des données brutes et requiert que vous initialisiez vous-même les requêtes. Cela permet une certaine souplesse et vous donne un contrôle strict de l’ensemble du trafic.
Planification des requêtes
Qu’il s’agisse de l’implémentation d’une application ou d’une bibliothèque, certains éléments du système global sont responsables de la planification des requêtes et de la détermination de leur format. En général, les implémentations peuvent se présenter sous deux formes. La première possibilité consiste à demander que toutes les requêtes et réponses s’effectuent de manière séquentielle. Cette méthode de conception synchrone est couramment adoptée puisque son code est simple à écrire et sans réseau privilégié, mais elle peut conduire à une sous-utilisation considérable d’un réseau TCP/IP. Dans une conception synchrone, le maître doit effectuer les opérations suivantes : générer une requête, l’envoyer sur le réseau, attendre que le serveur ait le temps de la traiter et de générer une réponse, attendre que celle-ci traverse le réseau, et enfin traiter la réponse – tout cela avant de générer une nouvelle requête. Avec un matériel esclave lent ou une couche réseau lente, la durée de ce cycle peut être relativement importante.
L’alternative à cette méthode consiste en une conception asynchrone, dans laquelle un processus sur le maître est chargé de générer des requêtes tandis qu’un autre se charge de réceptionner les réponses et de les acheminer en interne vers le code qui nécessite les données en question. Cette conception est beaucoup plus efficace puisque plusieurs requêtes peuvent être en transit sur le réseau en même temps, mais elle nécessite non seulement que l’esclave ait un buffer assez grand pour gérer les requêtes entrantes, mais aussi que le développeur de l’implémentation du maître s’investisse beaucoup dans ce processus. La Figure 5 illustre la différence entre ces deux schémas de transmission de messages. Les flèches pointant vers la droite indiquent les requêtes ; celles pointant vers la gauche indiquent les réponses.

Figure 5: Comparaison entre les méthodes de transmission de messages synchrones et asynchrones
Certaines applications telles que KEPServerEX et NI OPC Servers proposent un compromis en implémentant un schéma d’enfilage (threading) qui permet de bénéficier des avantages des deux types d’implémentations. Les balises et les matériels peuvent notamment être organisés de telle sorte que toutes les requêtes se fassent de manière synchrone, en un seul fil d’exécution, ou qu’elles puissent être réparties dans différents fils d’exécution. Dans ce cas, toutes les balises dans un fil donné sont demandées de manière synchrone, mais il est possible d’accéder à plusieurs matériels en même temps. Cela permet de maintenir un contrôle strict du réseau, tout en améliorant les performances globales du système.
Disponibilité de types
Le protocole Modbus est partiellement souple, puisque qu’il n’applique quasiment aucune restriction aux données du système. À la place, ces données se présentent sous forme de quatre blocs maximum contenant 65 635 registres d’éléments booléens. Elles peuvent être stockées soit dans des éléments de types différents (U16 ou booléens), soit en tant que valeurs de sous-registres, soit en tant que données traversant les limites de plusieurs registres.
Malheureusement, cette souplesse ne s’applique pas à l’utilisation du protocole. Comme dans le cas des protocoles TCP et série, où les données sont transférées en flux d’octets, le code d’application utilisant le Modbus est nécessaire pour formater ces données de telle sorte qu’elles soient cohérentes avec le reste du système. La conversion de données 32 bits qui constituent le premier et le deuxième registre en type de données en virgule flottante simple précision dépend intégralement du code d’application. Pour rendre les choses encore plus complexes, l’ordonnancement de ces données n’est pas déterminé par le protocole. Ce dernier définit les registres qui seront transférés sur le réseau dans l’ordre big-endian, mais de nombreux matériels gèrent les limites entre les registres différemment.
Il est donc important de prendre ce fait en considération dans le cadre d’une implémentation, quelle qu’elle soit, puisque, selon les matériels, des variations peuvent se présenter. Une bibliothèque génère généralement des données brutes sous forme de registre, ce qui implique qu’il faille remanier des données selon les besoins de votre application. Si une bibliothèque génère des données typées, il est important de consulter la documentation pour s’informer sur le format demandé. En revanche, les applications prennent généralement la variabilité en compte. Par exemple, KEPServerEX et NI OPC Servers vous donnent la possibilité de changer l’architecture des octets (endianness) des types de données à registres multiples sur chaque matériel. Si cette option n’est pas disponible, il se peut que vous deviez l’implémenter vous-même en traitant les registres comme des données brutes.
Adressage
Comme expliqué précédemment, le Modbus complique l’adressage en raison de la variété de schémas qu’il utilise. Bien que les spécifications définissent strictement un schéma d’adressage (c’est-à-dire que le registre de maintien 5 est lu en demandant l’adresse 0x04 avec le code fonctionnel 0x03), les matériels convertissent généralement ces informations en un nombre unique. Selon l’origine de la documentation, le même nombre peut faire référence à différentes valeurs. Il est essentiel de prendre cela en compte lorsque vous utilisez une bibliothèque standard ou une application.
D’ordinaire, les bibliothèques ne fournissent pas d’abstraction pour convertir un schéma d’adressage courant (comme « 400005 ») en requête pour les données stockées par le registre de maintien 5. Certaines le font cependant, en particulier celles qui supportent les types.
Par contre, les serveurs OPC et les autres applications sont plus susceptibles d’utiliser les schémas d’adressage les plus courants. Les applications telles que NI OPC Servers et KEPServerEX permettent même de couvrir la plupart des permutations des schémas d’adressage (comme une indexation commençant à zéro ou à un). Néanmoins, ces applications peuvent présenter des spécifications inhabituelles – notamment en ce qui concerne l’interprétation des registres comme étant des types de données différents –, et il est important de toujours consulter la documentation relative à l’application en question pour s’assurer que les données sont correctement transférées et interprétées.
Choisir une implémentation et une architecture Modbus
Si vous choisissez le Modbus comme protocole privilégié d’une application, NI propose trois outils essentiels à la communication Modbus. Au niveau le plus bas, de nombreuses bibliothèques d’API différentes sont disponibles. Celles-ci supportent généralement à la fois le maître et l’esclave. Les modules LabVIEW Datalogging and Supervisory Control (DSC) et LabVIEW Real-Time proposent un outil appelé serveur d’E/S Modbus, qui offre une partie de la souplesse et de la simplicité d’utilisation caractéristiques des bibliothèques bas niveau. Les serveurs d’E/S supportent également les maîtres et les esclaves. Enfin, NI OPC Servers est un serveur OPC parfaitement fonctionnel qui peut inclure un support de driver pour les maîtres Modbus.
Protocole Modbus avec NI OPC Servers
NI OPC Servers est une application de serveur OPC autonome et complète qui peut servir d’élément principal à un système SCADA. Comme tous les serveurs OPC antérieurs à la sortie d’OPC UA, NI OPC Servers est un programme pour Windows uniquement. Il est donc plus approprié de l’utiliser en tant que système de supervision plutôt qu’en tant que système destiné au contrôle haute vitesse de matériels esclaves. NI OPC Servers fournit un large éventail de drivers pour permettre la communication non seulement avec des matériels Modbus, mais également avec des matériels utilisant une vaste gamme de protocoles spécifiques au fournisseur ou standard comme OPC UA. Un système standard ressemblerait à la Figure 6.
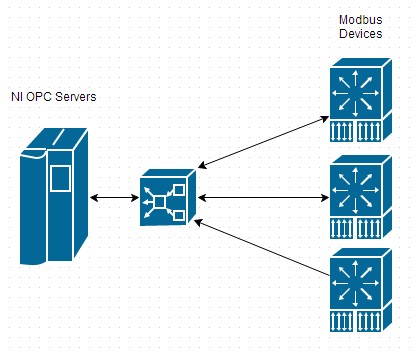
Figure 6: Cette application SCADA standard utilise un ensemble de matériels Modbus TCP/IP ainsi qu’un hôte NI OPC Servers.
Comme de nombreux serveurs OPC, NI OPC Servers est conçu pour gérer un large éventail de types de données, de paramètres des modes de représentation des octets (endianness) sur chaque matériel, de capacités de planification des requêtes, ainsi que beaucoup d’autres fonctions permettant l’abstraction de quelques détails bas niveau du Modbus. Une fois que l’application contient les données, celles-ci peuvent être transférées vers les enregistreurs, les interfaces homme-machine (IHM) ou d’autres applications Windows par l’intermédiaire du protocole OPC ou OPC UA.
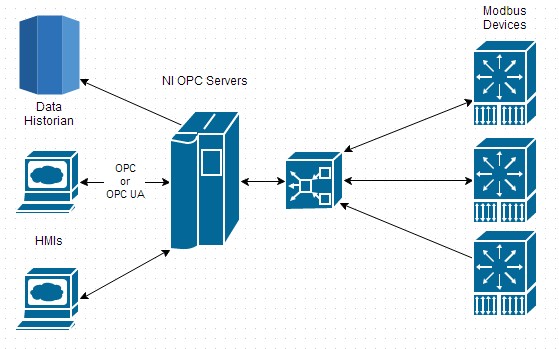
Figure 7: Cette vue étendue d’une application SCADA standard inclut des interactions entre des systèmes d’historisation sous Windows et des IHM.
Protocole Modbus avec serveurs d’E/S
Les serveurs d’E/S Modbus inclus dans LabVIEW constituent une solution intermédiaire entre la simplicité des serveurs OPC et la puissance des bibliothèques bas niveau qui permettent un contrôle total du protocole. Comme les serveurs OPC, les serveurs d’E/S permettent à une interface simple basée configuration de communiquer avec un matériel Modbus. Ils disposent également de leur propre système de planification de requêtes et gèrent une bonne partie des mises en garde bas niveau dans le protocole Modbus, comme les modes de représentation des octets (endianness). Cependant, ils proposent une interface simple dans LabVIEW et permettent aux programmes d’accéder rapidement et facilement aux données traitées (les valeurs en virgule flottante simple précision des registres 45 et 46) ou aux données brutes (les entiers 16 bits non signés du registre 45). Tout comme les serveurs OPC, les serveurs d’E/S sont généralement utilisés dans le cadre d’applications où la supervision est importante, tandis que les microcontrôleurs distribués sont chargés du contrôle haute vitesse du système.
Serveurs d’E/S maîtres Modbus
Les serveurs d’E/S peuvent être considérés comme des serveurs OPC basiques qui s’exécutent dans votre application. Pour un usage normal, le serveur d’E/S maître Modbus est déployé comme un élément inhérent à l’application, qui devient ensuite directement responsable du transfert des données à une IHM ou à une base de données. Dans certains cas, le degré d’implication du développeur peut réduire la souplesse d’utilisation du système final – un serveur OPC complet est plus adaptable. En revanche, il est parfaitement logique d’éliminer les serveurs OPC intermédiaires des systèmes plus petits et de créer une seule application simple pour tout gérer.
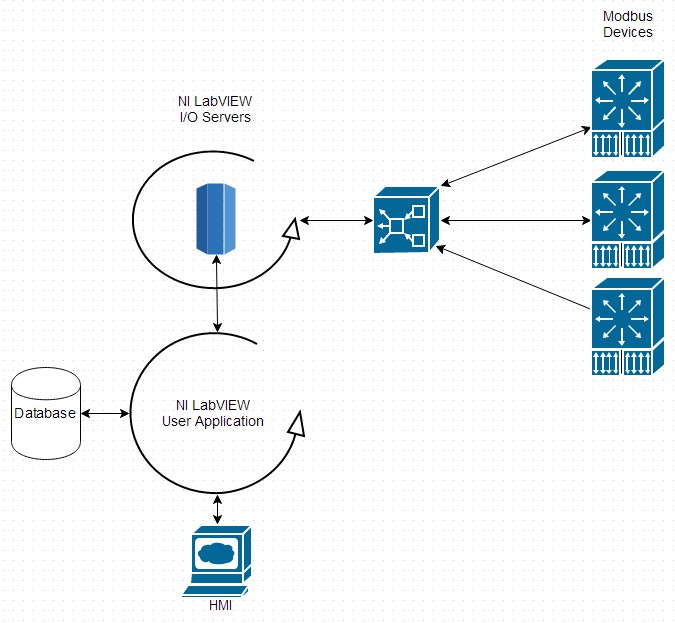
Figure 8: Un exemple d’application de contrôle utilisant un serveur d’E/S maître Modbus
Serveurs d’E/S esclaves Modbus
Tout comme les serveurs d’E/S maîtres, les serveurs esclaves doivent être utilisés exclusivement pour les opérations de supervision. Étant donné que les serveurs d’E/S constituent un processus en arrière-plan, le code d’utilisateur ne peut en aucun cas être informé du moment où une requête a été reçue. Cela rend les serveurs d’E/S particulièrement adaptés aux applications dans lesquelles le contrôle est assuré par un matériel plus performant, tel qu’un PAC, avec des mises à jour basse priorité occasionnelles venant d’un concentrateur (« central hub »). Dans ce type d’applications, les données Modbus du serveur d’E/S sont balayées à chaque itération d’une boucle de contrôle, puis utilisées dans le cadre du processus de prise de décision ; mais ces données ne sont pas utilisées dans le cadre de communications critiques (telles qu’une demande d’arrêt d’urgence).
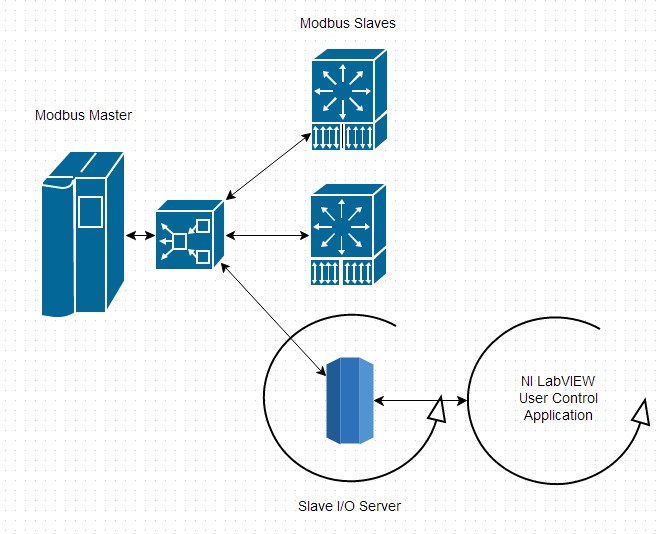
Figure 9: Un exemple d’application de serveur d’E/S esclave Modbus
Protocole Modbus avec des API bas niveau
De nombreux drivers Modbus bas niveau sont disponibles dans différentes langues. Les modules LabVIEW 2014 DSC et LabVIEW 2014 Real-Time proposent une API Modbus bas niveau pour compléter les fonctionnalités de NI OPC Servers et de serveurs d’E/S Modbus.
Avec ces drivers, vous pouvez explicitement définir ce qui se passe lorsqu’une requête Modbus est envoyée ou reçue. Ils permettent généralement des performances optimales plus élevées que les drivers plus haut niveau. En contrepartie, vous devez développer une grande partie du code de traitement des données, ce qui permet à votre application d’interagir efficacement avec les autres matériels du système. La fonctionnalité et le comportement de ce code varie selon que le matériel est maître ou esclave.
La Figure 10 illustre la manière dont un maître bas niveau (l’API Modbus LabVIEW) permet un contrôle strict des requêtes spécifiques envoyées et de leur planification.
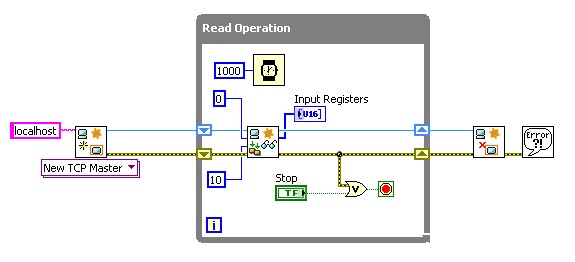
Figure 10: Un maître bas niveau contrôle le moment d’envoi et le contenu d’une requête de lecture.
Maître bas niveau
Utilisé en tant que maître, un PAC hautes performances utilisant un driver Modbus bas niveau peut servir à contrôler efficacement un système nécessitant rapidité et fiabilité. Ces requêtes étant générées directement par le code d’application, tout échec est immédiatement rapporté, ce qui permet au système de passer en état de sécurité ou de prendre les mesures correctives nécessaires.
De plus, l’application exerce un contrôle strict sur le moment précis auquel les données sont transmises, ce qui permet au code d’utiliser efficacement la bande passante du réseau. Différentes fréquences de balayage peuvent être appliquées à différents matériels esclaves. Si nécessaire, l’application peut même utiliser des chemins d’accès réseau complètement différents (deux connexions TCP, des lignes série différentes) pour satisfaire aux exigences de l’application en termes de performances.
La Figure 11 montre un exemple d’application pour laquelle le développeur a choisi de concevoir une boucle de supervision en fonction d’événements à basse vitesse, similaire à ce que pourrait présenter un système SCADA sous Windows. Dans un processus parallèle, une boucle de contrôle déterministe est utilisée pour communiquer avec une pompe à haute vitesse.
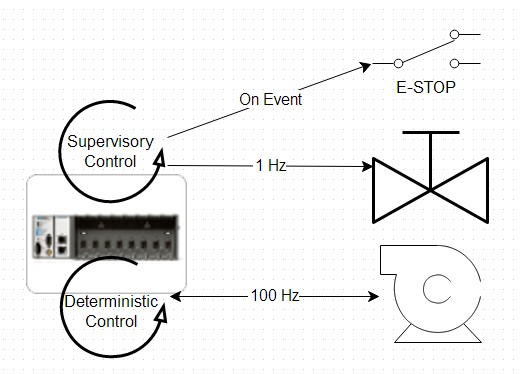
Figure 11: Cet exemple d’application PAC NI CompactRIO utilise un driver maître Modbus bas niveau.
De plus, vous pouvez tirer parti de la grande souplesse des drivers bas niveau pour recréer certaines fonctionnalités d’une interface haut niveau, comme un serveur d’E/S, tout en gardant le contrôle des priorités dont dépend le comportement du système. Dans cet exemple d’application, une boucle de communication a été développée pour gérer la planification de toutes les requêtes et réponses de manière à satisfaire aux besoins de l’application. Il est possible de développer une boucle de contrôle déterministe pour connaître la disponibilité de nouvelles données de la boucle de communication, ce qui permet de tirer parti de certains avantages du premier système sans pâtir des inconvénients potentiels dus aux erreurs de communication.
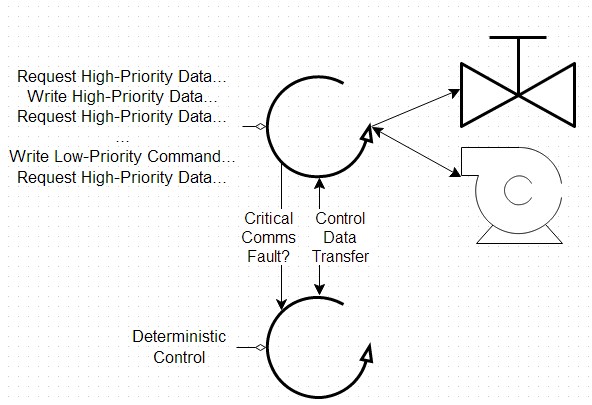
Figure 12: Cette application de contrôle personnalisée déplace les communications vers une boucle secondaire pour réduire l’impact des erreurs de communication tout en maintenant le niveau de performances requis par le système.
Esclave bas niveau
En raison des difficultés à gérer le protocole de requête-réponse du côté du serveur directement avec le code d’application, de nombreuses implémentations d’esclaves Modbus proposent un processus en arrière-plan pour que les requêtes des maîtres reçoivent une réponse. En principe, ce comportement est similaire à celui des esclaves des serveurs d’E/S.
Cependant, dans un driver bas niveau, le code d’application est prévu pour adapter le comportement de ce processus aux besoins du système. Dans certains cas, les esclaves bas niveau fournissent un événement que le code d’application est en mesure de gérer. Cela permet de répondre immédiatement aux données entrantes du maître sans avoir à interroger la mémoire du matériel pour connaître les modifications.
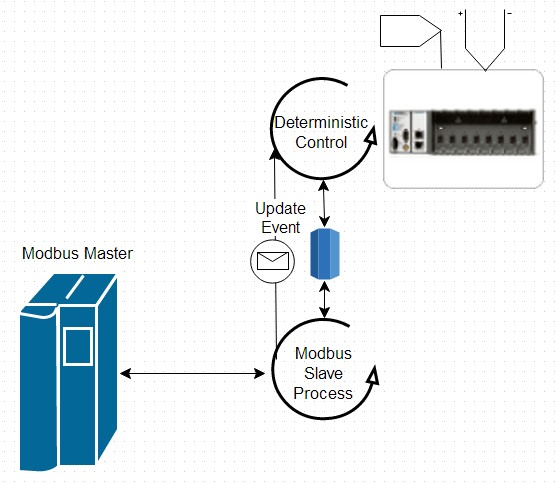
Figure 13: Ce driver esclave bas niveau utilise des événements pour indiquer les changements de données dans un modèle de données partagé.
Dans les cas les plus avancés, le driver bas niveau peut être conçu de telle manière que le code d’application puisse être injecté directement dans le modèle de données de l’API esclave. Ainsi, l’esclave est capable de répondre aux requêtes du maître de la manière la plus adaptée à l’application en question, au lieu de lire simplement un emplacement de mémoire. Cela permet de profiter de nombreux avantages présentés par le maître bas niveau sans avoir à écrire un serveur dans le code d’application.
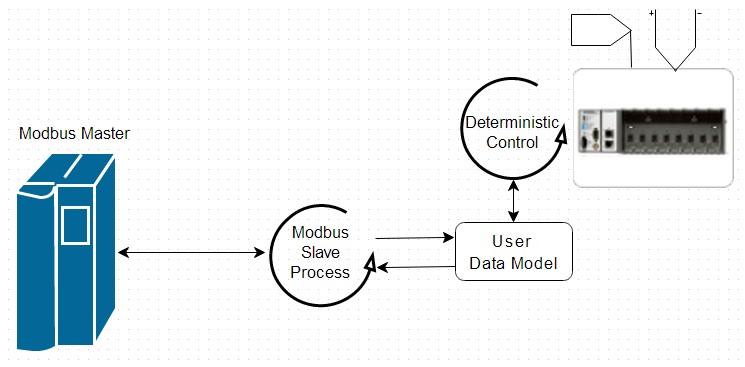
Figure 14: Cette application esclave bas niveau utilise un modèle de données personnalisé pour interagir directement avec un code de contrôle déterministe en s’adaptant à un système spécifique.
Avantages et inconvénients du protocole Modbus
Avantages
- Couramment utilisé, avec plusieurs implémentations disponibles
- Flexible
- Spécifications librement disponibles
- L’architecture de requête-réponse fournit un accusé de réception au niveau application
Inconvénients
- Le processus de requête-réponse sous-utilise le réseau ou complique le code d’application
- Surcharge réseau
- La taille limitée des paquets provoque l’augmentation du temps système et la diminution de la fréquence maximale d’invitations à émettre
- Transfert de données en continu difficile, voire impossible
- Aucun support de type natif à l’exception des entiers non signés 16 bits et un seul bit
- Aucune fonctionnalité de sécurité intégrée
- Nécessite une architecture qui scrute.
Le Modbus est, et continuera d’être un protocole largement répandu, en dépit de la quantité de nouvelles technologies apparues ces dernières années. Bien qu’il présente des contraintes que vous devez connaître, sa simplicité et sa souplesse en font une excellente méthode pour certaines conceptions.