Estructura interna del formato de archivo TDMS
Información general
Contenido
- Estructura lógica
- Diseño binario
- Propiedades predefinidas
- Optimización
- Conclusión
- Recursos adicionales
Estructura lógica
Los archivos TDMS organizan los datos en una jerarquía de objetos de tres niveles. El nivel superior se compone de un único objeto que contiene información específica del archivo, como, por ejemplo, el autor o título. Cada archivo puede contener un número ilimitado de grupos y cada grupo puede contener un número ilimitado de canales. En la siguiente ilustración, el archivo de ejemplo events.tdms contiene dos grupos, cada uno de los cuales contiene dos canales.
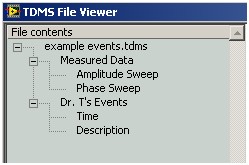
Cada objeto TDMS se identifica de forma exclusiva por medio de una ruta. Cada ruta es una cadena que incluye el nombre del objeto y el nombre de su propietario en la jerarquía TDMS, separados por una barra diagonal. Cada nombre va entre comillas. Todas las comillas simples que van dentro de un nombre de objeto se reemplaza con comillas dobles. La tabla siguiente ilustra ejemplos de formato de ruta para cada tipo de objeto TDMS:
| Nombre de objeto | Objeto | Ruta |
| -- | Archivo | / |
| Datos medidos | Grupo | /'Measured Data' |
| Barrido de amplitud | Canal A | /'Measured Data'/'Amplitude Sweep' |
| Dr. Eventos de T | Grupo | /'Dr. T''s Events' |
| Tiempo | Canal A | /'Dr. T''s Events'/'Time' |
Para que todas las aplicaciones cliente TDMS funcionen correctamente, cada archivo TDMS debe contener un objeto de archivo. Un objeto de archivo debe contener un objeto de grupo para cada nombre de grupo utilizado en una ruta de canal. Además, un objeto de archivo puede contener un número arbitrario de objetos de grupo sin canales.
Cada objeto TDMS puede tener un número ilimitado de propiedades. Cada propiedad TDMS consta de una combinación de un nombre (siempre una cadena), un identificador de tipo y un valor. Los tipos de datos típicos para las propiedades incluyen tipos numéricos como enteros o números de punto flotante, registros de tiempo o cadenas. Las propiedades TDMS no admiten matrices. Si un archivo TDMS se encuentra dentro de un área de búsqueda del DataFinder de NI, todas las propiedades están automáticamente disponibles para la búsqueda.
Solo los objetos de canal en archivos TDMS pueden contener matrices de datos sin procesar. En las versiones actuales de TDMS, solo se admiten matrices unidimensionales.
Diseño binario
Cada archivo TDMS contiene dos tipos de datos: metadatos y datos sin procesar. Los metadatos son datos descriptivos almacenados en objetos o propiedades. Las matrices de datos adjuntas a los objetos del canal se denominan datos sin procesar. Los archivos TDMS contienen datos sin procesar para múltiples canales en un bloque contiguo. Para poder extraer datos sin procesar de ese bloque, los archivos TDMS usan un índice de datos sin procesar, que incluye información sobre la composición del bloque de datos, incluido el canal que corresponde a los datos, la cantidad de valores que contiene el bloque para ese canal y el orden en el que se almacenaron los datos.
Diseño de segmento TDMS
Los datos se escriben en archivos TDMS en segmentos. Cada vez que se agregan datos a un archivo TDMS, se crea un nuevo segmento. Consulte las secciones Metadatos y Datos sin procesar de este artículo para ver las excepciones a esta regla. Un segmento consta de las siguientes tres partes:
- Introducción: contiene información básica, como una etiqueta que identifica los archivos como TDMS, un número de versión y la información sobre la extensión de los metadatos y los datos sin procesar.
- Metadatos: contiene nombres y propiedades de todos los objetos del segmento. Para los objetos que incluyen datos sin procesar (canales), la parte de metadatos también contiene información de índice que se utiliza para ubicar los datos sin procesar para este objeto en el segmento.
- Datos sin procesar: un bloque contiguo de todos los datos sin procesar asociados con cualquiera de los objetos incluidos en el segmento. La parte de datos sin procesar puede contener valores de datos intercalados o una serie de fragmentos de datos contiguos. La parte de datos sin procesar también puede contener datos sin procesar de DAQmx.
Todas las cadenas en archivos TDMS, como rutas de objetos, nombres de propiedad, valores de propiedad y valores de datos sin procesar, están codificadas en UTF-8 Unicode. Todos ellos, excepto los valores de datos sin procesar, van precedidos por un entero sin signo de 32 bits que contiene la extensión de la cadena en bytes, sin incluir el valor de la longitud en sí. Las cadenas en archivos TDMS pueden tener terminación nula, pero como se almacena la información de extensión, el terminador nulo se ignorará cuando se lea el archivo.
Los registros de tiempo en los archivos TDMS se almacenan como una estructura de dos componentes:
- (i64) segundos: desde la fecha 01/01/1904 00:00:00.00 UTC (en calendario gregoriano e ignorando los segundos intercalares).
- (u64) fracciones positivas: (2^-64) de segundo.
Los valores booleanos se almacenan como 1 byte cada uno, donde 1 representa VERDADERO y 0 representa FALSO.
Introducción
La introducción contiene información utilizada para validar un segmento. La introducción también contiene información utilizada para el acceso aleatorio a un archivo TDMS. El siguiente ejemplo muestra la huella binaria de la parte de introducción de un archivo TDMS:
| Diseño binario (hexadecimal) | Descripción |
| 54 44 53 6D | Etiqueta “TDSm”. |
| 0E 00 00 00 | Máscara de ToC 0x1110 (el segmento contiene una lista de objetos, metadatos, datos sin procesar). |
| 69 12 00 00 | Número de versión (4713). |
| E6 00 00 00 00 00 00 00 | Desfase del siguiente segmento (valor: 230). |
| DE 00 00 00 00 00 00 00 | Desfase de datos sin procesar (valor: 222). |
La parte de introducción de la tabla anterior contiene la siguiente información:
- La introducción comienza con una etiqueta de 4 bytes que identifica un segmento TDMS (“TDSm”).
- Los siguientes cuatro bytes se usan como una máscara de bits para indicar qué tipo de datos contiene el segmento. Esta máscara de bits se denomina ToC (Tabla de contenido). Cualquier combinación de los siguientes indicadores se puede codificar en ToC:
Indicador Descripción #define kTocMetaData (1L<<1) El segmento contiene metadatos. #define kTocRawData (1L<<3) El segmento contiene datos sin procesar. #define kTocDAQmxRawData (1L<<7) El segmento contiene datos sin procesar DAQmx. #define kTocInterleavedData (1L<<5) Los datos sin procesar en el segmento están intercalados (si el indicador no está configurado, los datos son contiguos). #define kTocBigEndian (1L<<6) Todos los valores numéricos en el segmento, incluidos la introducción, los datos sin procesar y los metadatos, tienen formato big endian (si no se establece el indicador, los datos son little endian). La ToC no se ve afectada por orden de bytes; siempre es little endian. #define kTocNewObjList (1L<<2) El segmento contiene una lista de objetos nueva (por ejemplo, los canales en este segmento no son los mismos canales que contiene el segmento anterior). - Los cuatro bytes siguientes contienen un número de versión (entero sin signo de 32 bits), que especifica la revisión de TDMS más antigua que cumple un segmento. Al momento de redactar este documento, el número de versión es 4713. La única versión anterior de TDMS tiene el número 4712.
Nota: El número de versión 4713 corresponde al formato de archivo TDMS versión 2.0 en LabVIEW. El número de versión 4712 corresponde al formato de archivo TDMS versión 1.0 en LabVIEW.
- Los siguientes ocho bytes (entero sin signo de 64 bits) describen la longitud del segmento restante (longitud total del segmento menos la longitud de la introducción). Si se agregan más segmentos al archivo, este número se puede usar para ubicar el punto de partida del siguiente segmento. Si una aplicación ha encontrado un problema grave al escribir en un archivo TDMS (bloqueo, corte de energía), todos los bytes de este entero pueden ser 0xFF. Esto solo puede sucederle al último segmento de un archivo.
- Los últimos ocho bytes (entero sin signo de 64 bits) describen la longitud total de la metainformación en el segmento. Esta información se utiliza para el acceso aleatorio a los datos sin procesar. Si el segmento no contiene metadatos (propiedades, información de índice, lista de objetos), este valor será 0.
Metadatos
Los metadatos TDMS consisten en una jerarquía de tres niveles de objetos de datos que incluye un archivo, grupos y canales. Cada uno de estos tipos de objeto puede incluir una cantidad ilimitada de propiedades. La sección de metadatos tiene el siguiente diseño binario en el disco:
- Número de nuevos objetos en este segmento (entero sin signo de 32 bits).
- Representación binaria de cada uno de estos objetos.
El diseño binario de un único objeto TDMS en disco consta de los componentes en el siguiente orden. En función de la información almacenada en un segmento particular, el objeto puede contener solo un subconjunto de estos componentes.
- Ruta del objeto (cadena).
- Índice de datos sin procesar.
- Si este objeto no tiene datos sin procesar asignados en este segmento, se almacenará un entero sin signo de 32 bits (0xFFFFFFFF) en lugar de la información del índice.
- Si este objeto contiene datos sin procesar DAQmx en este segmento, entonces los primeros cuatro bytes del índice de datos sin procesar es “69 12 00 00” (que significa que los datos sin procesar contienen el escalador de cambio de formato DAQmx) o “69 13 00 00” (que significa que los datos sin procesar contienen el escalador de línea digital DAQmx). Después de estos primeros cuatro bytes hay información sobre el índice de datos sin procesar DAQmx. Consulte el elemento de viñeta siguiente para obtener más información sobre el índice de datos sin procesar DAQmx.
- Si el índice de datos sin procesar de este objeto en este segmento coincide exactamente con el índice que tenía el mismo objeto en el segmento anterior, se almacenará un entero sin signo de 32 bits (0x0000000) en lugar de la información del índice.
- Si el objeto contiene datos sin procesar que no coinciden con la información de índice asignada a este objeto en el segmento anterior, se almacenará un nuevo índice para esos datos sin procesar:
- Longitud del índice de datos sin procesar (entero sin signo de 32 bits).
- Tipo de datos (enum tdsDataType, almacenado como un entero de 32 bits).
- Dimensión de matriz (entero sin signo de 32 bits) (en el formato de archivo TDMS versión 2.0, 1 es el único valor válido).
- Número de valores (entero sin signo de 64 bits).
- Tamaño total en bytes (entero sin signo de 64 bits) (solo almacenado para tipos de datos de longitud variable, por ejemplo, cadenas).
- Si el índice de datos sin procesar es el índice de datos sin procesar DAQmx, el índice contiene la siguiente información:
- Tipo de datos (entero sin signo de 32 bits), donde “FF FF FF FF” indica que los datos sin procesar son datos sin procesar DAQmx).
- Dimensión de matriz (entero sin signo de 32 bits) (en el formato de archivo TDMS versión 2.0, 1 es el único valor válido).
- Número de valores (entero sin signo de 64 bits), también conocido como “tamaño de fragmento”.
- El vector de escaladores de cambio de formato.
- Tamaño del vector (entero sin signo de 32 bits).
Lo siguiente se aplica a la información del primer escalador de Cambio de formato. - Tipo de datos DAQmx (entero sin signo de 32 bits).
- Índice de búfer sin procesar (entero sin signo de 32 bits).
- Desfase de bytes sin procesar dentro del intervalo (entero de 32 bits sin signo).
- Mapa de bits de formato de muestra (entero sin signo de 32 bits).
- ID de escala (entero sin signo de 32 bits).
(Si el tamaño del vector es mayor que 1, el objeto contiene varios escaladores de cambio de formato y la información de los elementos anteriores de la viñeta puede repetirse).
- Tamaño del vector (entero sin signo de 32 bits).
- El vector del ancho de datos sin procesar.
- Tamaño del vector (entero sin signo de 32 bits).
- Elementos en el vector (cada uno es un entero sin signo de 32 bits).
- Número de propiedades (entero sin signo de 32 bits).
- Propiedades. En cada propiedad, se almacena la siguiente información:
- Nombre (cadena).
- Tipo de datos (tdsDataType).
- Valor (binarios numéricos almacenados, cadenas almacenadas tal como se explicó anteriormente).
La tabla siguiente muestra un ejemplo de metainformación para un grupo y un canal. El grupo contiene dos propiedades, una cadena y un número entero. El canal contiene un índice de datos sin procesar y no tiene propiedades.
| Huella binaria (hexadecimal) | Descripción |
| 02 00 00 00 | Número de objetos. |
| 08 00 00 00 | Longitud de la primera ruta del objeto. |
| 2F 27 47 72 6F 75 70 27 | Ruta de objeto (/'Group'). |
| FF FF FF FF | Índice de datos sin procesar (“FF FF FF FF” significa que no hay datos sin procesar asignados al objeto). |
| 02 00 00 00 | Número de propiedades para /'Group'. |
| 04 00 00 00 | Longitud del primer nombre de propiedad. |
| 70 72 6F 70 | Nombre de propiedad (prop). |
| 20 00 00 00 | Tipo de datos del valor de propiedad (tdsTypeString). |
| 05 00 00 00 | Longitud del valor de propiedad (solo para cadenas). |
| 76 61 6C 75 65 | Valor de la propiedad prop (valor). |
| 03 00 00 00 | Longitud del segundo nombre de propiedad. |
| 6E 75 6D | Nombre de propiedad (num). |
| 03 00 00 00 | Tipo de datos del valor de propiedad (tdsTypeI32). |
| 0A 00 00 00 | Valor de la propiedad num (10). |
| 13 00 00 00 | Longitud de la segunda ruta del objeto. |
| 2F 27 47 72 6F 75 70 27 2F 27 43 68 61 6E 6E 65 6C 31 27 | Ruta del segundo objeto (/'Group'/'Channel1'). |
| 14 00 00 00 | Longitud de la información del índice. |
| 03 00 00 00 | Tipo de datos de los datos sin procesar asignados a este objeto. |
| 01 00 00 00 | Dimensión de la matriz de datos sin procesar (debe ser 1). |
| 02 00 00 00 00 00 00 00 | Número de valores de datos sin procesar. |
| 00 00 00 00 | Número de propiedades para /'Group'/'Channel1' (no tiene propiedades). |
La tabla siguiente es un ejemplo del índice de datos sin procesar DAQmx.
| Huella binaria (hexadecimal) | Descripción |
| 03 00 00 00 | Número de objetos. |
| 23 00 00 00 | Longitud de la ruta del objeto de grupo. |
| 2F 27 4D 65 61 73 75 72 65 64 20 54 68 72 6F 75 67 68 70 75 74 20 44 61 74 61 20 28 56 6F 6C 74 73 29 27 | Ruta del objeto (/'Measured Throughput Data (Volts)'). |
| FF FF FF FF | Índice de datos sin procesar (“FF FF FF FF” significa que no hay datos sin procesar asignados al objeto). |
| 00 00 00 00 | Número de propiedades para /'Measured Throughput Data (Volts)'. |
| 34 00 00 00 | Longitud de la ruta del objeto de canal. |
| 2F 27 4D 65 61 73 75 72 65 64 20 54 68 72 6F 75 67 68 70 75 74 20 44 61 74 61 20 28 56 6F 6C 74 73 29 27 2F 27 50 58 49 31 53 6C 6F 74 30 33 2d 61 69 30 27 69 12 00 00 | /'Measured Throughput Data (Volts)'/'PXI1Slot03-ai0' |
| 69 12 00 00 | Índice de datos sin procesar DAQmx y contiene el escalador de cambio de formato. |
| FF FF FF FF | Tipo de datos; datos sin procesar DAQmx. |
| 01 00 00 00 | Dimensión de datos |
| 00 00 00 00 00 00 00 00 | Número de valores; no hay valores en este segmento. |
| 01 00 00 00 | Tamaño del vector de escaladores de cambio de formato. |
| 05 00 00 00 | Tipo de datos DAQmx del primer escalador de cambio de formato. |
| 00 00 00 00 | Índice de búfer sin procesar del primer escalador de cambio de formato. |
| 00 00 00 00 | Desfase de bytes sin procesar dentro del intervalo. |
| 00 00 00 00 | Mapa de bits del formato de muestra. |
| 00 00 00 00 | ID de escala. |
| 01 00 00 00 | Tamaño del vector del ancho de datos sin procesar. |
| 08 00 00 00 | Primer elemento del vector del ancho de datos sin procesar. |
| 06 00 00 00 | Número de propiedades para /'Measured Throughput Data (Volts)'/'PXI1Slot03-ai0'. |
| 11 00 00 00 | Longitud del primer nombre de propiedad. |
| 4E 49 5F 53 63 61 6C 69 6E 67 5F 53 74 61 74 75 73 | Nombre de propiedad (“NI_Scaling_Status”). |
| 20 00 00 00 | Tipo de datos del valor de propiedad (tdsTypeString). |
| 08 00 00 00 | Longitud del valor de propiedad (solo para cadenas). |
| 75 6E 73 63 61 6C 65 64 | Valor de la propiedad prop (“no escalada”). |
| 13 00 00 00 | Longitud del segundo nombre de propiedad. |
| 4E 49 5F 4E 75 6D 62 65 72 5F 4F 66 5F 53 63 61 6C 65 73 | Nombre de propiedad (“NI_Number_Of_Scales”). |
| 07 00 00 00 | Tipo de datos del valor de propiedad (tdsTypeU32). |
| 02 00 00 00 | Valor de la propiedad (2). |
| 16 00 00 00 | Longitud del tercer nombre de propiedad. |
| 4E 49 5F 53 63 61 6C 65 5B 31 5D 5F 53 63 61 6C 65 5F 54 79 70 65 | Nombre de propiedad (“NI_Scale[1]_Scale_Type”). |
| 20 00 00 00 | Tipo de datos de la propiedad (tdsTypeString). |
| 06 00 00 00 | Longitud del valor de propiedad. |
| 4C 69 6E 65 61 72/span> | Valor de propiedad (“Linear”). |
| 18 00 00 00 | Longitud del cuarto nombre de propiedad. |
| 4E 49 5F 53 63 61 6C 65 5B 31 5D 5F 4C 69 6E 65 61 72 5F 53 6C 6F 70 65 | Nombre de propiedad (“NI_Scale[1]_Linear_Slope”). |
| 0A 00 00 00 | Tipo de datos de la propiedad (tdsTypeDoubleFloat). |
| 04 E9 47 DD CB 17 1D 3E | Valor de propiedad (1.693433E-9). |
| 1E 00 00 00 | Longitud del quinto nombre de propiedad. |
| 4E 49 5F 53 63 61 6C 65 5B 31 5D 5F 4C 69 6E 65 61 72 5F 59 5F 49 6E 74 65 72 63 65 70 74 | Nombre de propiedad (“NI_Scale[1]_Linear_Y_Intercept”) |
| 0A 00 00 00 | Tipo de datos de la propiedad (tdsTypeDoubleFloat). |
| 00 00 00 00 00 00 00 00 | Valor de propiedad (0). |
| 1F 00 00 00 | Longitud del sexto nombre de propiedad. |
| 4E 49 5F 53 63 61 6C 65 5B 31 5D 5F 4C 69 6E 65 61 72 5F 59 6E 70 75 74 5F 53 6F 75 72 63 65 | Nombre de propiedad (“NI_Scale[1]_Linear_Input_Source”). |
| 07 00 00 00 | Tipo de datos de la propiedad (tdsTypeU32). |
| 00 00 00 00 | Valor de propiedad (0). |
En la tabla anterior, el canal "/'Measured Throughput Data (Volts)'/'PXI1Slot03-ai0" contiene dos escaladores. Un escalador es Cambio de formato [Format Changing], donde la información del escalador de cambio de formato se almacena en el índice de datos sin procesar DAQmx. El otro escalador es un escalador lineal [Linear scaler], donde la información se almacena como propiedades TDMS. El escalador de cambio de formato se puede identificar donde la pendiente del escalador lineal es 1,693433E-9, la intercepción es 0 y el ID de la fuente de entrada es 0.
La metainformación que coincide con la metainformación en los segmentos anteriores se puede omitir en los siguientes segmentos. Esto es opcional, pero la omisión de metainformación redundante acelera significativamente la lectura del archivo. Si elige escribir información redundante, después puede eliminarla usando la función Desfragmentar TDMS [TDMS Defragment function] en LabVIEW, LabWindows/CVI, MeasurementStudio, etc.
- Escribir un nuevo objeto en el siguiente segmento implicará que el segmento contiene todos los objetos del segmento anterior, más los objetos nuevos descritos aquí. Si el segmento nuevo no contiene ningún canal del segmento anterior, o si el orden de los canales en el segmento cambia, el nuevo segmento debe contener una lista nueva de todos los objetos. Consulte la sección Optimización de este artículo para obtener más información.
- Al rscribir una nueva propiedad en un objeto que ya existe en el segmento anterior, esta propiedad se añadirá al objeto.
- Escribir una propiedad que ya existe en un objeto sobrescribirá el valor anterior de esa propiedad.
Nota: En el formato de archivo TDMS versión 2.0, al especificar un valor para la propiedad de nombre de un objeto existente cambiará el nombre de ese objeto.
El ejemplo siguiente muestra la huella binaria para la sección de metadatos de un segmento que sigue directamente al segmento descrito anteriormente. La única metainformación escrita en el nuevo segmento es el nuevo valor de la propiedad.
| Diseño binario (hexadecimal) | Descripción |
| 01 00 00 00 | Número de objetos nuevos/modificados. |
| 08 00 00 00 | Longitud de la ruta del objeto. |
| 2F 27 47 72 6F 75 70 27 | Ruta de objeto (/'Group'). |
| FF FF FF FF | Índice de datos sin procesar (no hay datos sin procesar asignados al objeto). |
| 01 00 00 00 | Número de propiedades nuevas/modificadas. |
| 03 00 00 00 | Longitud del nombre de propiedad. |
| 6E 75 6D | Nombre de propiedad (num). |
| 03 00 00 00 | Tipo de datos del valor de propiedad (tdsTypeI32). |
| 07 00 00 00 | Nuevo valor para la propiedad num (7). |
Datos sin procesar
Por último, el segmento contiene los datos sin procesar asociados con cada canal. Las matrices de datos para todos los canales se concatenan en el orden exacto en el que aparecen los canales en la parte de metainformación del segmento. Los datos numéricos deben formatearse de acuerdo con el indicador little-endian/big-endian de la introducción. Tenga en cuenta que los canales no pueden cambiar su tipo de datos o formato endian una vez que se ha escrito en ellos por primera vez.
Los canales de tipo cadena se preprocesan para un acceso aleatorio rápido. Todas las cadenas se concatenan en una pieza de memoria contigua. El desfase del primer carácter de cada cadena de esta pieza de memoria contigua se almacena en una matriz de enteros sin signo de 32 bits. Esta matriz de valores de desfase se almacena primero, seguida de los valores de cadena concatenados. Este diseño permite que las aplicaciones de cliente accedan a cualquier valor de cadena desde cualquier parte del archivo al reposicionar el puntero del archivo un máximo de tres veces y sin leer ningún dato que el cliente no necesite.
Si la metainformación entre segmentos no cambia, las partes de introducción y metainformación se pueden omitir por completo y los datos sin procesar se pueden agregar al final del archivo. Cada fragmento de datos sin procesar siguiente tiene el mismo diseño binario, y el número de fragmentos se puede calcular a partir de la introducción y de la metainformación mediante los siguientes pasos:
- Calcular el tamaño de los datos sin procesar de un canal. Cada canal tiene un Tipo de datos, Dimensión de matriz y Número de valores en la metainformación. Consulte la sección Metadatos de este artículo para obtener más información. Cada Tipo de datos está asociado con un tamaño de tipo. Puede obtener el tamaño de datos sin procesar del canal por: tipo de tamaño de Tipo de datos × Dimensión de matriz × Número de valores. Si el Tamaño total en bytes es válido, el tamaño de datos sin procesar del canal es este valor.
- Calcular el tamaño de datos sin procesar de un fragmento acumulando el tamaño de datos sin procesar de todos los canales.
- Calcular el tamaño de los datos sin procesar de fragmentos totales por: Desfase del segmento siguiente - Desfase de datos sin procesar. Si el valor de Desfase del segmento siguiente es -1, el tamaño de los datos sin procesar de los fragmentos totales es igual al tamaño del archivo menos la posición de inicio absoluta de los datos sin procesar.
- Calcular el número de fragmentos por: Tamaño de datos sin procesar de los fragmentos totales ÷ Tamaño de datos sin procesar de un fragmento.
Los datos sin procesar se pueden organizar en dos tipos de diseño: intercalados y no intercalados. La máscara de bits de ToC en la introducción del segmento declara si los datos del segmento están intercalados o no. Por ejemplo: almacenar valores enteros de 32 bits en el canal 1 (1,2,3) y el canal 2 (4,5,6) da como resultado los siguientes diseños:
| Diseño de datos | Huella binaria (hexadecimal) |
| No intercalado | 01 00 00 00 02 00 00 00 03 00 00 00 04 00 00 00 05 00 00 00 06 00 00 00 |
| Intercalado | 01 00 00 00 04 00 00 00 02 00 00 00 05 00 00 00 03 00 00 00 06 00 00 00 |
Valores de tipo de datos
El siguiente tipo de enumeración describe el tipo de datos de una propiedad o canal en un archivo TDMS. Para las propiedades, el valor del tipo de datos se almacenará entre el nombre y el valor binario. Para los canales, el tipo de datos formará parte del índice de datos sin procesar.
typedef enum {
tdsTypeVoid,
tdsTypeI8,
tdsTypeI16,
tdsTypeI32,
tdsTypeI64,
tdsTypeU8,
tdsTypeU16,
tdsTypeU32,
tdsTypeU64,
tdsTypeSingleFloat,
tdsTypeDoubleFloat,
tdsTypeExtendedFloat,
tdsTypeSingleFloatWithUnit=0x19,
tdsTypeDoubleFloatWithUnit,
tdsTypeExtendedFloatWithUnit,
tdsTypeString=0x20,
tdsTypeBoolean=0x21,
tdsTypeTimeStamp=0x44,
tdsTypeFixedPoint=0x4F,
tdsTypeComplexSingleFloat=0x08000c,
tdsTypeComplexDoubleFloat=0x10000d,
tdsTypeDAQmxRawData=0xFFFFFFFFhttps://forums.ni.com/t5/Example-Code/VI-Based-API-for-Writing-TDMS-Files/ta-p/4101006
} tdsDataType;
Notas:
- Consulte el artículo de Registro de tiempo de LabVIEW para obtener más información sobre el uso de tdsTypeTimeStamp en LabVIEW.6471
- Los tipos de punto flotante de LabVIEW con unidad se traducen en un canal de punto flotante con una propiedad llamada unit_string que contiene la unidad como una cadena.
Consulte el artículo API basada en VI para escribir archivos TDMS para obtener más información sobre las capacidades de escritura de TDMS.
Propiedades predefinidas
Las formas de onda de LabVIEW se representan en archivos TDMS como canales numéricos, donde los atributos de forma de onda se agregan al canal como propiedades.
- wf_start_time: propiedad que representa el momento en que se ha adquirido o generado la forma de onda. Esta propiedad puede ser cero si la información de tiempo es relativa o si la forma de onda no es del dominio del tiempo, sino, por ejemplo, del dominio de la frecuencia.
- wf_start_offset: propiedad que se usa para el tipo de datos dinámicos de LabVIEW Express. Los datos del dominio de la frecuencia y los resultados del histograma utilizarán este valor como el primer valor en el eje x.
- wf_increment: propiedad que representa el incremento entre dos muestras consecutivas en el eje x.
- wf_samples: propiedad que representa el número de muestras en la forma de onda.
Optimización
La aplicación de la definición de formato, como se describe en las secciones anteriores, crea archivos TDMS perfectamente válidos. Sin embargo, TDMS permite una variedad de optimizaciones que suele utilizarlas el software de NI, como LabVIEW, LabWindows/CVI, MeasurementStudio, etc. Las aplicaciones que intentan leer datos escritos por el software de NI deben admitir los mecanismos de optimización descritos en este párrafo.
Ejemplo de metainformación incremental
La metainformación, como las rutas de objetos, las propiedades y los índices sin procesar, se agrega a un segmento solo si este cambia. La metainformación incremental se explica en el siguiente ejemplo.
En la primera iteración de escritura, se escriben el canal 1 y el canal 2. Cada canal tiene tres valores enteros de 32 bits (1,2,3 y 4,5,6) y varias propiedades descriptivas. La parte de metainformación del primer segmento contiene rutas, propiedades e índices de datos sin procesar para el canal 1 y el canal 2. Se establecen los indicadores kTocMetaData, kTocNewObjList y kTocRawData del campo de bits de ToC. La primera iteración de escritura crea un segmento de datos. La tabla siguiente describe la huella binaria del primer segmento.
| Parte | Huella binaria (hexadecimal) |
| Introducción | 54 44 53 6D 0E 00 00 00 69 12 00 00 8F 00 00 00 00 00 00 00 77 00 00 00 00 00 00 00 |
| Número de objetos. | 02 00 00 00 |
| Objeto de metainformación 1 | 13 00 00 00 2F 27 67 72 6F 75 70 27 2F 27 63 68 61 6E 6E 65 6C 31 27 14 00 00 00 03 00 00 00 01 00 00 00 03 00 00 00 00 00 00 00 01 00 00 00 04 00 00 00 70 72 6F 70 20 00 00 00 05 00 00 00 76 61 6C 69 64 |
| Objeto de metainformación 2 | 13 00 00 00 2F 27 67 72 6F 75 70 27 2F 27 63 68 61 6E 6E 65 6C 32 27 14 00 00 00 03 00 00 00 01 00 00 00 03 00 00 00 00 00 00 00 00 00 00 00 |
| Canal de datos sin procesar 1 | 01 00 00 00 02 00 00 00 03 00 00 00 |
| Canal de datos sin procesar 2 | 04 00 00 00 05 00 00 00 06 00 00 00 |
En la segunda iteración de escritura, ninguna de las propiedades ha cambiado, el canal 1 y el canal 2 todavía tienen tres valores cada uno, y no se escriben canales adicionales. Por lo tanto, esta iteración no escribirá ningún metadato. Los metadatos del segmento anterior aún se consideran válidos. Esta iteración no creará un segmento nuevo; en su lugar, esta iteración solo agrega los datos sin procesar al segmento existente y, a continuación, actualiza el Desfase del segmento siguiente [Next Segment Offset] en la sección Introducción [Lead]. La tabla siguiente describe la huella binaria del segmento actualizado.
| Parte | Huella binaria (hexadecimal) |
| Introducción | 54 44 53 6D 0E 00 00 00 69 12 00 00 A7 00 00 00 00 00 00 00 77 00 00 00 00 00 00 00 |
| Número de objetos. | 02 00 00 00 |
| Objeto de metainformación 1 | 13 00 00 00 2F 27 67 72 6F 75 70 27 2F 27 63 68 61 6E 6E 65 6C 31 27 14 00 00 00 03 00 00 00 01 00 00 00 03 00 00 00 00 00 00 00 01 00 00 00 04 00 00 00 70 72 6F 70 20 00 00 00 05 00 00 00 76 61 6C 69 64 |
| Objeto de metainformación 2 | 13 00 00 00 2F 27 67 72 6F 75 70 27 2F 27 63 68 61 6E 6E 65 6C 32 27 14 00 00 00 03 00 00 00 01 00 00 00 03 00 00 00 00 00 00 00 00 00 00 00 |
| Canal de datos sin procesar 1 | 01 00 00 00 02 00 00 00 03 00 00 00 |
| Canal de datos sin procesar 2 | 04 00 00 00 05 00 00 00 06 00 00 00 |
| Canal de datos sin procesar 1 | 01 00 00 00 02 00 00 00 03 00 00 00 |
| Canal de datos sin procesar 2 | 04 00 00 00 05 00 00 00 06 00 00 00 |
En la tabla anterior, las dos últimas filas contienen datos agregados al primer segmento durante la segunda iteración de escritura.
La tercera iteración de escritura agrega otros tres valores a cada canal. En el canal 1, el estado de la propiedad se ha establecido como válido en el primer segmento, pero ahora debe establecerse en error. Esta iteración creará un nuevo segmento, y la sección de metadatos de este segmento ahora contiene la ruta del objeto para el canal, el nombre, el tipo y el valor de esta propiedad. En futuras lecturas de archivos, el valor de error anulará el valor válido previamente escrito. Sin embargo, el valor válido anterior permanece en el archivo, a menos que esté desfragmentado. La tabla siguiente describe la huella binaria del segundo segmento.
| Parte | Huella binaria (hexadecimal) |
| Introducción | 54 44 53 6D 0A 00 00 00 69 12 00 00 50 00 00 00 00 00 00 00 38 00 00 00 00 00 00 00 |
| Número de objetos. | 01 00 00 00 |
| Objeto de metainformación 1 | 13 00 00 00 2F 27 67 72 6F 75 70 27 2F 27 63 68 61 6E 6E 65 6C 31 27 00 00 00 00 01 00 00 00 04 00 00 00 70 72 6F 70 20 00 00 00 05 00 00 00 65 72 72 6F 72 |
| Canal de datos sin procesar 1 | 01 00 00 00 02 00 00 00 03 00 00 00 |
| Canal de datos sin procesar 2 | 04 00 00 00 05 00 00 00 06 00 00 00 |
La cuarta iteración de escritura agrega un canal adicional, voltaje, que contiene cinco valores (7,8,9,10,11). Esta iteración creará un nuevo segmento, el tercero, en el archivo TDMS. Como todos los demás metadatos del segmento anterior siguen siendo válidos, la sección de metadatos del cuarto segmento incluye la ruta del objeto, las propiedades y la información del índice solo para el voltaje del canal. La sección de datos sin procesar contiene tres valores para el canal 1, tres valores para el canal 2 y cinco valores para el voltaje del canal. La tabla siguiente describe la huella binaria del tercer segmento.
| Parte | Huella binaria (hexadecimal) |
| Introducción | 54 44 53 6D 0A 00 00 00 69 12 00 00 5E 00 00 00 00 00 00 00 32 00 00 00 00 00 00 00 |
| Número de objetos. | 01 00 00 00 |
| Objeto de metainformación 3 | 12 00 00 00 2F 27 67 72 6F 75 70 27 2F 27 76 6F 6C 74 61 67 65 27 14 00 00 00 03 00 00 00 01 00 00 00 05 00 00 00 00 00 00 00 00 00 00 00 |
| Canal de datos sin procesar 1 | 01 00 00 00 02 00 00 00 03 00 00 00 |
| Canal de datos sin procesar 2 | 04 00 00 00 05 00 00 00 06 00 00 00 |
| Canal de datos sin procesar 3 | 07 00 00 00 08 00 00 00 09 00 00 00 0A 00 00 00 0B 00 00 00 |
En el cuarto segmento, el canal 2 ahora tiene 27 valores. Todos los demás canales permanecen sin cambios. La sección de metadatos ahora contiene la ruta del objeto para el canal 2, el nuevo índice de datos sin procesar para el canal 2 y ninguna propiedad para el canal 2. La tabla siguiente describe la huella binaria del cuarto segmento.
| Parte | Huella binaria (hexadecimal) |
| Introducción | 54 44 53 6D 0A 00 00 00 69 12 00 00 BF 00 00 00 00 00 00 00 33 00 00 00 00 00 00 00 |
| Número de objetos. | 01 00 00 00 |
| Objeto de metainformación 2 | 13 00 00 00 2F 27 67 72 6F 75 70 27 2F 27 63 68 61 6E 6E 65 6C 32 27 14 00 00 00 03 00 00 00 01 00 00 00 1B 00 00 00 00 00 00 00 00 00 00 00 |
| Canal de datos sin procesar 1 | 01 00 00 00 02 00 00 00 03 00 00 00 |
| Canal de datos sin procesar 2 | 01 00 00 00 02 00 00 00 03 00 00 00 04 00 00 00 05 00 00 00 06 00 00 00 07 00 00 00 08 00 00 00 09 00 00 00 0A 00 00 00 0B 00 00 00 0C 00 00 00 0D 00 00 00 0E 00 00 00 0F 00 00 00 10 00 00 00 11 00 00 00 12 00 00 00 13 00 00 00 14 00 00 00 15 00 00 00 16 00 00 00 17 00 00 00 18 00 00 00 19 00 00 00 1A 00 00 00 1B 00 00 00 |
| Canal de datos sin procesar 3 | 07 00 00 00 08 00 00 00 09 00 00 00 0A 00 00 00 0B 00 00 00 |
En el quinto segmento, la aplicación deja de escribir en el canal 2. La aplicación continúa escribiendo en el canal 1 y el voltaje del canal. Esto constituye un cambio en el orden de los canales, que requiere que escriba una nueva lista de las rutas de los canales. Debe establecer el bit de ToC kTocNewObjList. La sección de metadatos del nuevo segmento debe contener una lista completa de todas las rutas de objetos, pero no propiedades ni índices de datos sin procesar, a menos que también cambien. La tabla siguiente describe la huella binaria del quinto segmento.
| Parte | Huella binaria (hexadecimal) |
| Introducción | 54 44 53 6D 0E 00 00 00 69 12 00 00 61 00 00 00 00 00 00 00 41 00 00 00 00 00 00 00 |
| Número de objetos. | 02 00 00 00 |
| Objeto de metainformación 1 | 13 00 00 00 2F 27 67 72 6F 75 70 27 2F 27 63 68 61 6E 6E 65 6C 31 27 00 00 00 00 00 00 00 00 |
| Objeto de metainformación 2 | 12 00 00 00 2F 27 67 72 6F 75 70 27 2F 27 76 6F 6C 74 61 67 65 27 00 00 00 00 00 00 00 00 |
| Canal de datos sin procesar 1 | 01 00 00 00 02 00 00 00 03 00 00 00 |
| Canal de datos sin procesar 3 | 07 00 00 00 08 00 00 00 09 00 00 00 0A 00 00 00 0B 00 00 00 |
Archivos de índice
Todos los datos escritos en un archivo TDMS se almacenan en un archivo con la extensión *.tdms. Los archivos TDMS pueden ir acompañados de un archivo de índice opcional *.tdms_index. El archivo de índice se utiliza para acelerar la lectura del archivo *.tdms. Si una aplicación de NI abre un archivo TDMS sin un archivo de índice, la aplicación crea automáticamente el archivo de índice. Si una aplicación de NI, como LabVIEW o LabWindows/CVI, escribe un archivo TDMS, la aplicación crea el archivo de índice y el archivo principal al mismo tiempo.
El archivo de índice es una copia exacta del archivo *.tdms, excepto que no contiene datos sin procesar y cada segmento empieza con una etiqueta TDSh en lugar de una etiqueta TDSm. El archivo de índice contiene toda la información para localizar con precisión cualquier valor de cualquier canal dentro del archivo *.tdms.
Conclusión
En resumen, el formato de archivo TDMS está diseñado para escribir y leer datos medidos a muy alta velocidad, mientras se mantiene un sistema jerárquico de información descriptiva. Si bien el diseño binario en sí mismo es bastante simple, las optimizaciones habilitadas al escribir metadatos de forma incremental pueden conducir a configuraciones de archivo muy sofisticadas.
Recursos adicionales
La marca LabWindows se usa bajo una licencia de Microsoft Corporation. Windows is a registered trademark of Microsoft Corporation in the United States and other countries.