Optimizar aplicaciones de pruebas automatizadas para procesadores multinúcleo con NI LabVIEW
Información general
Serie de notas técnicas sobre fundamentos de programación multinúcleo

Serie de notas técnicas sobre fundamentos de programación multinúcleo
LabVIEW proporciona un entorno de programación gráfica único y fácil de usar para aplicaciones de pruebas automatizadas. Sin embargo, es su capacidad para asignar código dinámicamente a varios núcleos de CPU lo que mejora las velocidades de ejecución en los procesadores multinúcleo. Aprenda cómo se pueden optimizar las aplicaciones de LabVIEW para aprovechar las técnicas de programación paralela.
Contenido
- El desafío de la programación de hilos múltiples
- Implementar algoritmos de pruebas en paralelo
- Configurar algoritmos personalizados de pruebas en paralelo
- Optimizar aplicaciones de hardware-in-the-loop
- Conclusión
- Más recursos sobre programación multinúcleo
El desafío de la programación de hilos múltiples
Hasta hace poco, las innovaciones en la tecnología de procesadores han dado como resultado PCs con CPUs que operan a velocidades de reloj más altas. Sin embargo, a medida que las velocidades de reloj se acercan a sus límites físicos teóricos, las compañías están desarrollando nuevos procesadores con múltiples núcleos de procesamiento. Con estos nuevos procesadores multinúcleo, los ingenieros que desarrollan aplicaciones de pruebas automatizadas pueden lograr el mejor rendimiento y el más alto rendimiento utilizando técnicas de programación paralela. Dr. Edward Lee, profesor de ingeniería eléctrica y cómputo en la Universidad de California - Berkeley, describe los beneficios del procesamiento paralelo.
"Muchos tecnólogos predicen que el fin de la Ley de Moore se responderá con arquitecturas de cómputo cada vez más paralelas. Si esperamos continuar obteniendo ganancias de rendimiento en el cómputo, los programas deben poder explotar este paralelismo".
Además, los expertos de la industria reconocen que es un desafío importante para las aplicaciones de programación aprovechar los procesadores multinúcleo. Bill Gates, fundador de Microsoft, Inc., explica.
"Para aprovechar al máximo la potencia de los procesadores que funcionan en paralelo... el software debe abordar el problema de la concurrencia. Pero como cualquier desarrollador que haya escrito código de hilos múltiples puede decirle, esta es una de las tareas más difíciles en la programación".
Afortunadamente, el software NI LabVIEW ofrece un entorno de programación de procesador multinúcleo ideal con una API intuitiva para crear algoritmos paralelos que pueden asignar dinámicamente múltiples hilos a una aplicación determinada. De hecho, usted puede optimizar las aplicaciones de pruebas automatizadas utilizando procesadores multinúcleo para lograr el mejor rendimiento.
Además, los instrumentos modulares PXI Express mejoran este beneficio porque aprovechan las altas velocidades de transferencia de datos que son posibles con el bus PCI Express. Dos aplicaciones específicas que se benefician de los procesadores multinúcleo y los instrumentos PXI Express son el análisis de señales multicanal y el procesamiento en línea (hardware in the loop). Esta nota técnica evalúa varias técnicas de programación paralela y caracteriza los beneficios de rendimiento que produce cada técnica.
Implementar algoritmos de pruebas en paralelo
Una aplicación común de pruebas automatizadas que se beneficia del procesamiento paralelo es el análisis de señales multicanal. Debido a que el análisis de frecuencia es una operación que requiere un uso intensivo del procesador, usted puede mejorar la velocidad de ejecución ejecutando el código de prueba en paralelo para que el procesamiento de la señal de cada canal se pueda distribuir a varios núcleos del procesador. Desde la perspectiva de un programador, el único cambio que debe realizar para obtener este beneficio es una reestructuración menor del algoritmo de prueba.
Para ilustrar, compare los tiempos de ejecución de dos algoritmos para análisis de frecuencia multicanal (transformada rápida de Fourier o FFT) en dos canales de un digitalizador de alta velocidad. El digitalizador de alta velocidad NI PXIe-5122 de 14 bits utiliza dos canales para adquirir señales a la máxima velocidad de muestreo (100 MS/s). Primero, examine el modelo de programación secuencial tradicional para esta operación en LabVIEW.
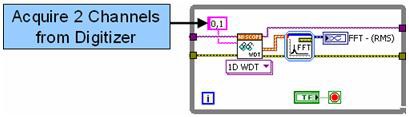
Figura 1. El código de LabVIEW utiliza ejecución secuencial.
En la Figura 1, el análisis de frecuencia de ambos canales se realiza en un FFT Express VI, que analiza cada canal en serie. Si bien el algoritmo que se muestra arriba aún se puede ejecutar de manera eficiente en procesadores multinúcleo, usted puede mejorar el rendimiento del algoritmo procesando cada canal en paralelo.
Si perfila el algoritmo, observa que la FFT tarda considerablemente más tiempo en completarse que la adquisición del digitalizador de alta velocidad. Al obtener cada canal uno a la vez y realizar dos FFTs en paralelo, usted puede reducir significativamente el tiempo de procesamiento. Vea la Figura 2 para un nuevo diagrama de bloques de LabVIEW que usa el enfoque paralelo.
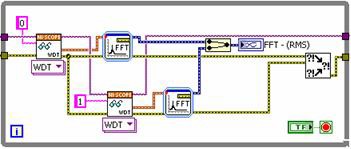
Figura 2. El código de LabVIEW utiliza ejecución paralela.
Cada canal se obtiene del digitalizador secuencialmente. Tenga en cuenta que podría realizar estas operaciones completamente en paralelo si ambas recuperaciones fueran de instrumentos únicos. Sin embargo, debido a que una FFT requiere un uso intensivo del procesador, usted aún puede mejorar el rendimiento simplemente ejecutando el procesamiento de la señal en paralelo. Como resultado, se reduce el tiempo total de ejecución. La Figura 3 muestra el tiempo de ejecución de ambas implementaciones.
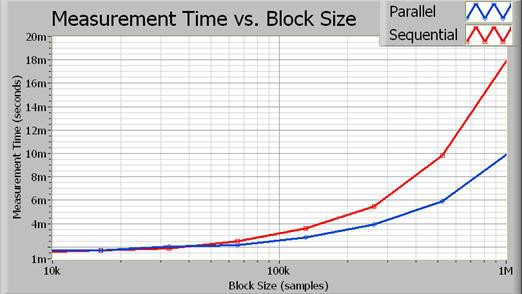
Figura 3. A medida que aumenta el tamaño del bloque, el tiempo de procesamiento ahorrado a través de la ejecución en paralelo se vuelve más obvio.
De hecho, el algoritmo paralelo se acerca a una mejora del doble del rendimiento para tamaños de bloque más grandes. La Figura 4 ilustra el aumento porcentual exacto en el rendimiento en función del tamaño de adquisición (en muestreos).
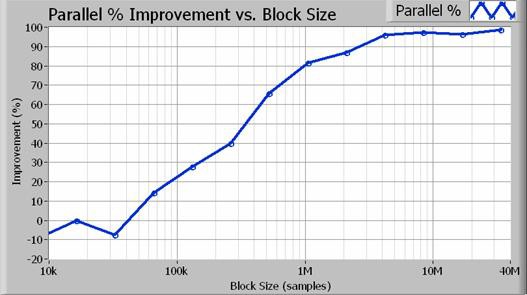
Figura 4. Para tamaños de bloque superiores a 1 millón de muestreos (ancho de banda de resolución de 100 Hz), el enfoque paralelo da como resultado un aumento del rendimiento del 80% o más.
Aumentar el rendimiento de las aplicaciones de pruebas automatizadas es fácil de lograr en los procesadores multinúcleo porque usted asigna cada hilo dinámicamente usando LabVIEW. De hecho, no es necesario crear un código especial para habilitar multithreading. En cambio, las aplicaciones de pruebas paralelas se benefician de los procesadores multinúcleo con ajustes mínimos de programación.
Configurar algoritmos personalizados de pruebas en paralelo
Los algoritmos de procesamiento de señales en paralelo ayudan a LabVIEW a dividir el uso del procesador entre múltiples núcleos. La Figura 5 ilustra el orden en el que la CPU procesa cada parte del algoritmo.
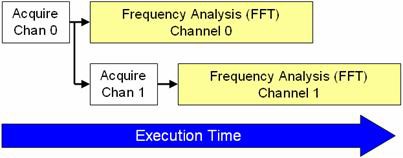
Figura 5. LabVIEW puede procesar gran parte de los datos adquiridos en paralelo, ahorrando tiempo de ejecución.
El procesamiento paralelo requiere que LabVIEW haga una copia (o clon) de cada subrutina de procesamiento de señales. De manera predeterminada, muchos algoritmos de procesamiento de señales de LabVIEW están configurados para tener "ejecución reentrante". Esto significa que LabVIEW asigna dinámicamente una instancia única de cada subrutina, incluyendo hilos separados y espacio de memoria. Como resultado, usted debe configurar subrutinas personalizadas para operar de manera reentrante. Puede hacer esto con un simple paso de configuración en LabVIEW. Para establecer esta propiedad, seleccione File >> VI Properties y elija la categoría Execution. Luego, seleccione el indicador de ejecución reentrante como se muestra en la Figura 6.
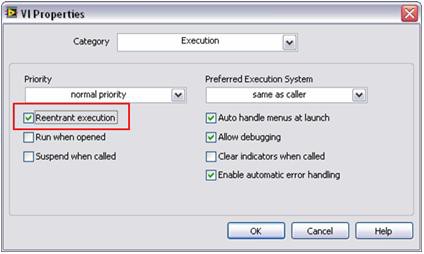
Figura 6. Con este simple paso, usted puede ejecutar múltiples subrutinas personalizadas en paralelo, al igual que las funciones de análisis estándares de LabVIEW.
Como resultado, puede lograr un rendimiento mejorado en sus aplicaciones de pruebas automatizadas en procesadores multinúcleo utilizando técnicas de programación simples.
Optimizar aplicaciones de hardware-in-the-loop
Una segunda aplicación que se beneficia de las técnicas de procesamiento de señales en paralelo es el uso de múltiples instrumentos para entrada y salida simultáneas. En general, se conocen como aplicaciones de procesamiento en línea o hardware-in-the-loop (HIL). En este escenario, puede usar un digitalizador de alta velocidad o un módulo de E/S digital de alta velocidad para adquirir una señal. En su software, usted realiza un algoritmo de procesamiento de señales digitales. Finalmente, el resultado es generado por otro instrumento modular. En la Figura 7 se ilustra un diagrama de bloques típico.

Figura 7. Este diagrama muestra los pasos en una aplicación típica de hardware-in-the-loop (HIL).
Las aplicaciones comunes de HIL incluyen procesamiento de señales digitales en línea (como filtrado e interpolación), simulación de sensores y emulación de componentes personalizados. Puede utilizar varias técnicas para lograr el mejor rendimiento para aplicaciones de procesamiento de señales digitales en línea.
En general, puede usar dos estructuras de programación básicas: la estructura de un solo ciclo y la estructura de múltiples ciclos segmentados con colas. La estructura de un solo ciclo es fácil de implementar y ofrece baja latencia para tamaños de bloque pequeños. Por el contrario, las arquitecturas de múltiples ciclos son capaces de un rendimiento mucho mayor porque utilizan mejor los procesadores multinúcleo.
Al usar el enfoque tradicional de un solo ciclo, usted coloca una función de lectura del digitalizador de alta velocidad, un algoritmo de procesamiento de señales y una función de escritura de E/S digitales de alta velocidad en orden secuencial. Como lo ilustra el diagrama de bloques en la Figura 8, cada una de estas subrutinas debe ejecutarse en una serie, según lo determinado por el modelo de programación de LabVIEW .
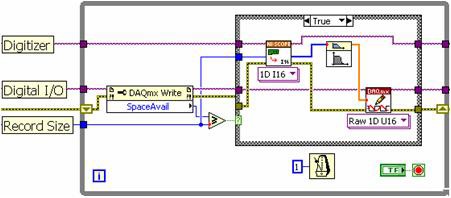
Figura 8. Con el enfoque de un solo ciclo de LabVIEW , cada subrutina debe ejecutarse en serie.
La estructura de un solo ciclo está sujeta a varias limitaciones. Debido a que cada etapa se realiza en una serie, el procesador no puede realizar E/S de instrumentos mientras procesa los datos. Con este enfoque, no puede usar de manera eficiente una CPU multinúcleo porque el procesador solo ejecuta una función a la vez. Si bien la estructura de un solo ciclo es suficiente para velocidades de adquisición más bajas, se requiere un enfoque de múltiples ciclos para un mayor rendimiento de datos.
La arquitectura de múltiples ciclos utiliza estructuras de cola para pasar datos entre cada ciclo While. La Figura 9 ilustra esta programación entre ciclos While con una estructura de cola.
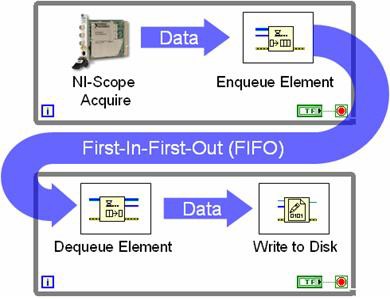
Figura 9. Con estructuras de cola, múltiples ciclos pueden compartir datos.
La Figura 9 representa lo que normalmente se conoce como una estructura de ciclo productor-consumidor. En este caso, un digitalizador de alta velocidad adquiere datos en un ciclo y pasa un nuevo conjunto de datos al FIFO durante cada iteración. El ciclo del consumidor simplemente monitorea el estado de la cola y escribe cada conjunto de datos en el disco cuando está disponible. El valor de usar colas es que ambos ciclos se ejecutan independientemente uno del otro. En el ejemplo anterior, el digitalizador de alta velocidad continúa adquiriendo datos incluso si hay un retraso al escribirlos en el disco. Mientras tanto, los muestreos adicionales simplemente se almacenan en el FIFO. En general, el enfoque de canalización productor-consumidor proporciona un mayor rendimiento de datos con una utilización más eficiente del procesador. Esta ventaja es aún más evidente en los procesadores multinúcleo porque LabVIEW asigna dinámicamente hilos de procesador a cada núcleo.
Para una aplicación de procesamiento de señales en línea, puede usar tres ciclos While independientes y dos estructuras de cola para pasar datos entre ellos. En este escenario, un ciclo adquiere datos de un instrumento, uno realiza un procesamiento de señal dedicado y el tercero escribe datos en un segundo instrumento.
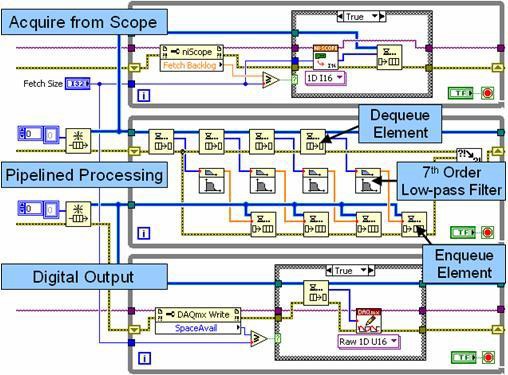
Figura 10. Este diagrama de bloques ilustra el procesamiento de señales segmentadas con múltiples ciclos y estructuras de cola.
En la Figura 10, el ciclo superior es un ciclo productor que adquiere datos de un digitalizador de alta velocidad y los pasa a la primera estructura de cola (FIFO). El ciclo medio funciona como productor y como consumidor. Durante cada iteración, descarga (consume) varios conjuntos de datos de la estructura de la cola y los procesa de forma independiente de manera segmentada. Este enfoque segmentado mejora el rendimiento en los procesadores multinúcleo al procesar hasta cuatro conjuntos de datos de forma independiente. Tenga en cuenta que el ciclo medio también funciona como productor al pasar los datos procesados a la segunda estructura de cola. Finalmente, el ciclo inferior escribe los datos procesados en un módulo de E/S digital de alta velocidad.
Los algoritmos de procesamiento paralelo mejoran la utilización del procesador en CPUs multinúcleo. De hecho, el rendimiento total depende de dos factores: la utilización del procesador y las velocidades de transferencia del bus. En general, la CPU y el bus de datos funcionan de manera más eficiente cuando se procesan grandes bloques de datos. Además, puede reducir aún más los tiempos de transferencia de datos utilizando instrumentos PXI Express, que ofrecen tiempos de transferencia más rápidos.
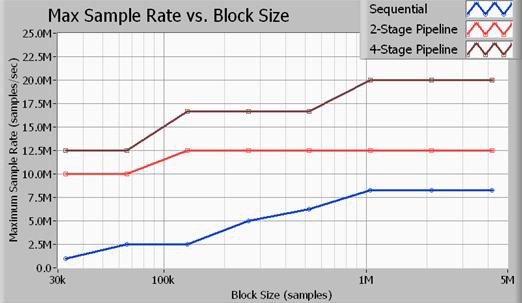
Figura 11. El rendimiento de las estructuras de múltiples ciclos es mucho más rápido que el de las estructuras de un solo ciclo.
La Figura 11 ilustra el rendimiento máximo en términos de velocidad de muestreo, de acuerdo con el tamaño de adquisición en muestreos. Todos los puntos de referencia ilustrados aquí se realizaron en muestreos de 16 bits. Además, el algoritmo de procesamiento de señales utilizado fue un filtro de paso bajo Butterworth de séptimo orden con un corte de 0.45 veces en la velocidad de muestreo. Como lo ilustran los datos, usted logra el mayor rendimiento de datos con el enfoque de canalización de cuatro etapas (varios ciclos). Tenga en cuenta que un enfoque de procesamiento de señales de dos etapas produce un mejor rendimiento que el método de un solo ciclo (secuencial), pero no utiliza el procesador de manera tan eficiente como el método de cuatro etapas. Las velocidades de muestreo enumeradas anteriormente son las velocidades de muestreo máximas de entrada y salida para un digitalizador de alta velocidad NI PXIe-5122 y un módulo de E/S digital de alta velocidad NI PXIe-6537. Tenga en cuenta que a 20 MS/s, el bus de aplicación transfiere datos a velocidades de 40 MB/s para entrada y 40 MB/s para salida para un ancho de banda total del bus de 80 MB/s.
También es importante tener en cuenta que el enfoque de procesamiento segmentado introduce latencia entre la entrada y la salida. La latencia depende de varios factores, incluyendo el tamaño del bloque y la velocidad de muestreo. Las Tablas 1 y 2 a continuación comparan la latencia medida de acuerdo con el tamaño del bloque y la velocidad de muestreo máxima para las arquitecturas de un solo ciclo y de múltiples ciclos de cuatro etapas.
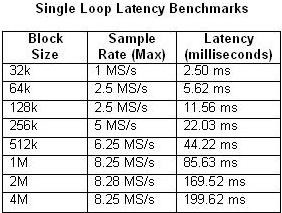
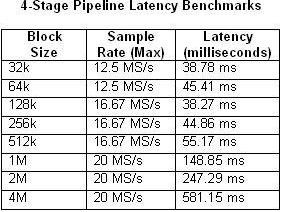
Tablas 1 y 2. Estas tablas ilustran la latencia de los parámetros de canalización de un solo ciclo y cuatro etapas.
Como es de esperar, la latencia aumenta a medida que el uso de la CPU se acerca al 100% de utilización. Esto es particularmente evidente en el ejemplo de pipeline de cuatro etapas con una velocidad de muestreo de 20 MS/s. Por el contrario, el uso de la CPU apenas supera el 50% en cualquiera de los ejemplos de un solo ciclo.
Conclusión
La instrumentación basada en PC, como los instrumentos modulares PXI y PXI Express, se beneficia enormemente de los avances en la tecnología de procesadores multinúcleo y de mejores velocidades del bus de datos. A medida que las nuevas CPUs mejoran el rendimiento al agregar múltiples núcleos de procesamiento, las estructuras de procesamiento en paralelo o en canal son necesarias para maximizar la eficiencia de la CPU. Afortunadamente, LabVIEW resuelve este desafío de programación asignando dinámicamente tareas de procesamiento a núcleos de procesamiento individuales. Como se ilustra, usted puede lograr mejoras significativas en el rendimiento estructurando los algoritmos de LabVIEW para aprovechar el procesamiento paralelo.