Arquitectura avanzada de pruebas de motores de cohetes para mayor independencia y mantenimiento del sistema
Información general
Esta nota técnica proporciona una guía completa para diseñar e implementar instalaciones de pruebas de motores de cohetes. Cubre el proceso de pruebas de motores de cohetes, los elementos clave de una arquitectura de pruebas de cohetes y consideraciones críticas para el diseño de pruebas, como la latencia del sistema, la temporización y la redundancia. El documento detalla los pasos de implementación, incluyendo la identificación del sistema, la selección de la tecnología y la validación del rendimiento del sistema. También destaca las tecnologías emergentes, como gRPC e iDDS, que mejoran la comunicación y la administración de datos en los sistemas de pruebas.
Contenido
- ¿Cómo se prueban los motores de cohetes?
- ¿Qué es un banco de pruebas de motores de cohetes?
- Arquitectura de pruebas de cohetes
- Consideraciones para el diseño de la arquitectura de pruebas
- Pasos de implementación
- Tecnologías emergentes para pruebas de motores de cohetes
- Soluciones de NI personalizadas para pruebas avanzadas de motores de cohetes
- Próximos pasos
- Notas al pie y referencias
¿Cómo se prueban los motores de cohetes?
Se realizaron más intentos orbitales en 2021 que en cualquier año anterior en la historia.1 Las compañías y los gobiernos de todo el mundo intentaron 146 vuelos, con 135 órbitas exitosas. 2021 rompió el récord anterior de 139 intentos establecido en el apogeo de la carrera espacial en 1967, cuando la URSS y EE. UU. competían fuertemente para llegar al espacio y más allá. La carrera espacial de la década de 2020 incluye más de dos países. Los lanzamientos ahora representan a EE. UU., Reino Unido, Europa, Rusia, China, India, Turquía, Irán, Israel y otros; solo en los primeros seis meses de 2022, la tendencia continuó con 72 vuelos exitosos. Y la carrera ya no es un proyecto del gobierno; muchas compañías espaciales privadas están compitiendo, trayendo grandes cantidades de dinero de los inversionistas al mercado.
Las nuevas tecnologías de cohetes están permitiendo este aumento en los lanzamientos espaciales. SpaceX lanzó 31 misiones Falcon 9 en 2021, todas ellas con éxito. Su nuevo enfoque para el diseño de cohetes les permitió lanzar todas estas misiones utilizando núcleos de cohetes usados anteriormente; solo se introdujeron dos nuevas primeras etapas del Falcon 9 para respaldar estos lanzamientos. A medida que las compañías y los países continúan invirtiendo para hacer que los lanzamientos espaciales sean más confiables, reutilizables y asequibles, la cantidad de lanzamientos y el alcance de esos lanzamientos seguirán aumentando.
La infraestructura para soportar estos lanzamientos también está aumentando. Hay 35 puertos espaciales activos e instalaciones de lanzamiento que pueden soportar misiones suborbitales, orbitales y extraorbitales. La lista de ubicaciones abarca todo el mundo, incluyendo todos los continentes y más de 13 países,2 con otros países construyendo nuevas instalaciones ahora. Y se utilizan sitios adicionales para probar los cohetes que se lanzan desde esas instalaciones. Es un momento emocionante para ser parte de la industria espacial.
La FAA regula los lanzamientos de cohetes para cualquier lanzamiento en suelo estadounidense, o fuera de los EE. UU. para cualquier lanzamiento por parte de un ciudadano o entidad estadounidense.3 Otros países tienen regulaciones y organismos reguladores similares; una compañía no puede lanzarse al espacio sin seguir los pasos de ingeniería adecuados. Uno de esos pasos críticos es probar el vehículo cohete y demostrar que tiene una alta probabilidad de éxito.
Probar un cohete comienza probando los diversos componentes del cohete. Los equipos de ingeniería prueban por separado los materiales y componentes que conformarán la estructura, los combustibles y la electrónica. Luego, esos componentes se ensamblan y prueban como subsistemas, y finalmente se ensamblan completamente en una prueba de aceptación a nivel de etapa completa.
Los productos de NI se utilizan en todos los aspectos del vehículo. La plataforma de pruebas estructurales estáticas y de fatiga es ideal para probar la resistencia del tanque de combustible para sobrevivir al estrés de un vuelo. Los instrumentos modulares basados en PXI de NI y el software de pruebas automatizadas proporcionan una poderosa plataforma para probar los circuitos de aviónica. La arquitectura de pruebas LRU HIL de NI es ideal para generar una variedad de casos de prueba para probar controladores de aviónica.
Este documento se enfoca en probar el motor de cohete, pero muchos de los elementos también se aplicarán a la prueba final del vehículo completo.
Las pruebas de motores de cohetes son una parte vital de las pruebas de todos los tipos de motores de cohetes; esta prueba es necesaria para cumplir con las regulaciones de la FAA. Pero las pruebas proporcionan valor más allá de cumplir con las regulaciones. Un informe de la NASA demostró que había una correlación positiva entre la cantidad de tiempo dedicado a probar los motores de cohetes y la fiabilidad de esos motores.4 Cada fabricante de motores debe decidir cómo equilibrar la inversión y el costo de las pruebas adicionales y el beneficio esperado de esas pruebas.
¿Qué es un banco de pruebas de motores de cohetes?
Un banco de pruebas de motores de cohetes es una estructura diseñada para sostener y probar motores de cohetes, proporcionando los sistemas de control y soporte necesarios, incluyendo estructuras de empuje, equipo de soporte en tierra para propulsores, sistemas de enfriamiento, desvío de gases de escape y automatización para seguridad y gestión operativa durante pruebas. Para probar un motor de cohete, el motor se monta en un banco de pruebas y se enciende durante un período de tiempo limitado. El banco de pruebas del motor de cohete debe proporcionar una estructura de empuje necesaria, equipo de soporte en tierra para propulsores, enfriamiento, desvío y escape, así como un sistema de control para automatizar la prueba y mantener la seguridad durante las operaciones y las pruebas. Los ingenieros deben decidir si el cohete se montará vertical u horizontalmente; hay ventajas para cualquier orientación. Es más fácil correlacionar las medidas con un motor montado verticalmente porque las fuerzas se parecen más a las fuerzas experimentadas durante el vuelo. Pero un motor montado verticalmente presenta el problema de desviar el escape del cohete durante la prueba, que generalmente se realiza con un desviador de flama.
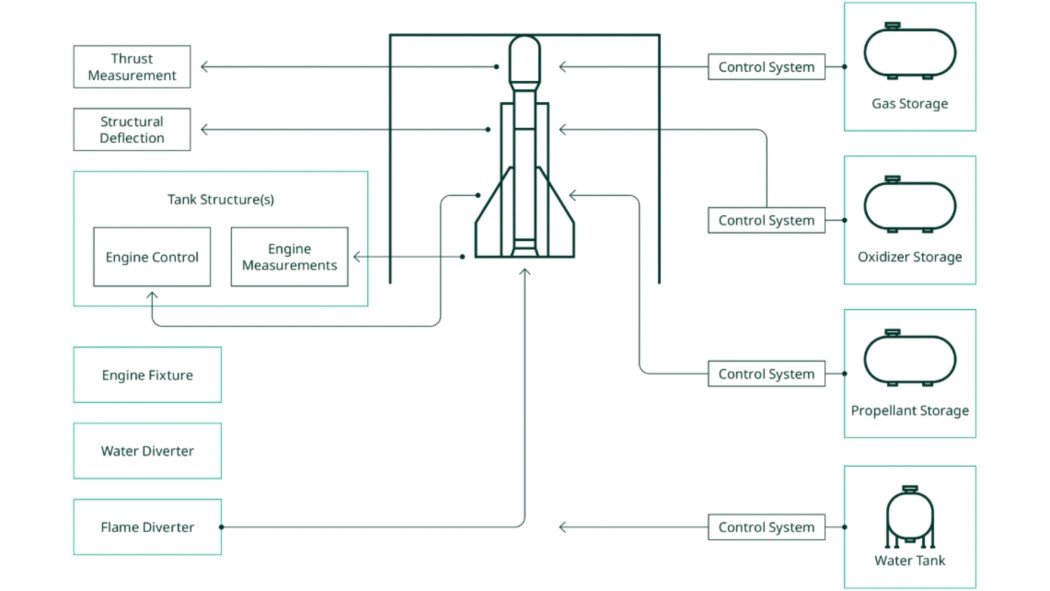
Figura 1. Elementos de un banco de pruebas de motores de cohetes
El escape plantea varios desafíos para las instalaciones de pruebas. Además del calor, el escape es ruidoso y sucio. Agregar un diluvio de agua al escape puede proporcionar un colchón para alejar el calor del motor y un escudo para amortiguar el ruido y los contaminantes del entorno circundante.
Hay muchas variaciones en una prueba de motor de cohete. Una prueba estándar a nivel del mar se puede realizar en un banco de pruebas sin mucho equipo adicional, pero otras pruebas pueden requerir entornos de prueba especializados. Por ejemplo, para probar un propulsor de cohete para el control de actitud en un satélite en el espacio, el banco de pruebas requiere una cámara de vacío para reproducir las condiciones de funcionamiento previstas del motor. Otras pruebas pueden requerir una cámara de vacío térmico o dispositivos mecánicos adicionales para probar el cardán del motor.
Las estaciones de prueba también varían según la etapa de desarrollo del motor. Una prueba del motor de desarrollo inicial puede incluir muchos sensores adicionales a medida que los ingenieros intentan capturar más dinámicas del rendimiento del motor. Un banco de pruebas que realiza pruebas de calificación o aceptación antes del servicio de vuelo puede probar un conjunto más pequeño de señales que verifican el funcionamiento adecuado.
Un equipo de ingeniería encargado de diseñar una prueba de cohetes debe considerar todas estas necesidades potenciales al diseñar un nuevo banco de pruebas. Con la tecnología de cohetes evolucionando tan rápido como ahora, los ingenieros también deben planificar las pruebas que podrían ser necesarias en el futuro. El diseño de la prueba debe ser lo suficientemente potente para satisfacer las necesidades conocidas, así como lo suficientemente flexible para satisfacer las necesidades a medida que evolucionan con el tiempo.
Los ingenieros de NI han trabajado en estrecha colaboración con ingenieros que diseñan sistemas de pruebas de cohetes durante más de 30 años. Durante este tiempo, las arquitecturas han madurado con la introducción de nuevas tecnologías y técnicas de software. Las mejores prácticas de aplicaciones relacionadas (pruebas de motores de jet, túneles de viento y otras grandes instalaciones de pruebas) han influido en el diseño de los sistemas utilizados para probar motores de cohetes. Algunos principios clave han surgido como fundamentales para el éxito de un diseño arquitectónico para probar motores de cohetes.
Una instalación de pruebas de cohetes puede soportar un solo banco de pruebas o múltiples bancos de pruebas. Cada banco de pruebas requiere soporte de varios subsistemas o pads, que pueden estar dedicados a un banco o pueden compartirse entre varios bancos o sitios dentro de las instalaciones de prueba. Un supervisor del sistema de control en tierra en toda la instalación reúne todas las plataformas y bancos de pruebas para una gestión operativa coordinada de los recursos de la instalación.

Figura 2. Subsistemas de instalaciones de pruebas de cohetes
Los sistemas de control de panel de soporte deben proporcionar fiabilidad para el control, así como capacidades de medidas para rastrear y mejorar el rendimiento.
La implementación exitosa de un sitio de pruebas de cohetes requiere una cuidadosa coordinación entre estos sistemas. A lo largo de los años, se ha desarrollado un esquema de control en las principales instalaciones espaciales que proporciona un patrón de diseño con la flexibilidad para cumplir con la comunicación entre estos sistemas y la variabilidad de los sistemas entre pruebas. En las compañías espaciales que administran las instalaciones de pruebas y lanzamiento, muchos de los componentes del patrón se comparten para reducir las diferencias entre lo que se prueba y cómo se lanza.
Arquitectura de pruebas de cohetes
Esta arquitectura utiliza un patrón de diseño del sistema común entre todos los bancos de pruebas y plataformas. El patrón proporciona el control local que necesita cada sistema y comparte información entre sistemas para garantizar la sincronización de las operaciones de prueba.

Figura 3. Patrón de diseño del sistema de control general
En este patrón, los sistemas de control leen las entradas de los procesos de comunicación que se describen más adelante en este documento.
Un proceso de escala convierte estas unidades sin procesar en unidades científicas apropiadas para el subsistema. Un proceso de escala también puede combinar múltiples canales en un solo canal calculado, por ejemplo, sumando todas las celdas de carga de empuje para proporcionar un solo valor de empuje. Un proceso de escala también aplica calibraciones reconfigurables, ya que la instrumentación puede cambiar entre pruebas o durante las operaciones.
Un proceso de alarma evalúa la salida de los puntos de datos del proceso de escalado para identificar alarmas. Las alarmas se pueden clasificar en varias categorías, como alertas para cancelar una prueba de inmediato o para notificar a un operador sobre un posible problema. Un proceso de alarma puede administrar el apagado exitoso de una secuencia de prueba o puede enviar comandos a otros sistemas para administrar esas acciones. Los operadores de pruebas pueden diseñar para una parada de emergencia o un apagado ordenado utilizando esta arquitectura.
Cuando no hay alarmas para evitar el progreso de la prueba, un proceso lógico analiza los valores de los procesos de lectura, escala y alarma para determinar las siguientes acciones. Por ejemplo, un proceso lógico puede determinar que la temperatura de un colector de fluido ha alcanzado el punto en el que es hora de abrir una válvula para permitir que un fluido fluya a través de la tubería (es decir, enfriándose en un colector Lox), por lo que emitirá un comando a otro subsistema remoto, o pasará un comando al proceso de secuencia para abrir la válvula localmente.
Luego, un proceso de secuencia ejecuta las acciones determinadas por eventos ordenados y cronometrados con condiciones (límites, límites y líneas rojas) desarrolladas por los operadores de pruebas y definidas por los requisitos de vuelo (control de vuelo simulado) o los requisitos de lanzamiento/instalaciones (lanzamiento simulado u operaciones de prueba nominales) . Las acciones simples pueden ejecutarse inmediatamente; las acciones complejas pueden derivar en un proceso paralelo para manejar la ejecución secuencial. Un proceso de secuencia utiliza valores de los procesos de lectura, lógica y alarma como entradas y actualiza las salidas del proceso de secuencia paralela según sea necesario.
La Figura 3 muestra estas funciones como una serie de pasos; pero en la aplicación, este patrón permite módulos paralelos separados que ejecutan su propio hilo pero se sincronizan con el hilo principal de orquestación operativa. Esto permite que el hilo principal se ejecute a una velocidad constante sin detenerse para esperar a que se complete una acción. Un ciclo del sistema de control generalmente opera entre 1 Hz y 400 Hz, dependiendo del sistema que se esté controlando.
Este patrón de diseño general se puede aplicar a cualquier sistema de control, pero en sistemas simples, algunos elementos pueden ser opcionales o manejarse en un sistema diferente. Por ejemplo, un controlador de motor simple puede no tener un proceso de alarma; en cambio, las condiciones de alarma pueden ser manejadas por otro sistema en base a la salida del sistema que controla el motor. Es posible que un sistema simple no tenga un proceso de secuencia, sino que esté controlado directamente por el proceso lógico para sistemas de control muy básicos o el proceso de secuencia de otro sistema de control a través de iDDS o gRPC, por ejemplo.
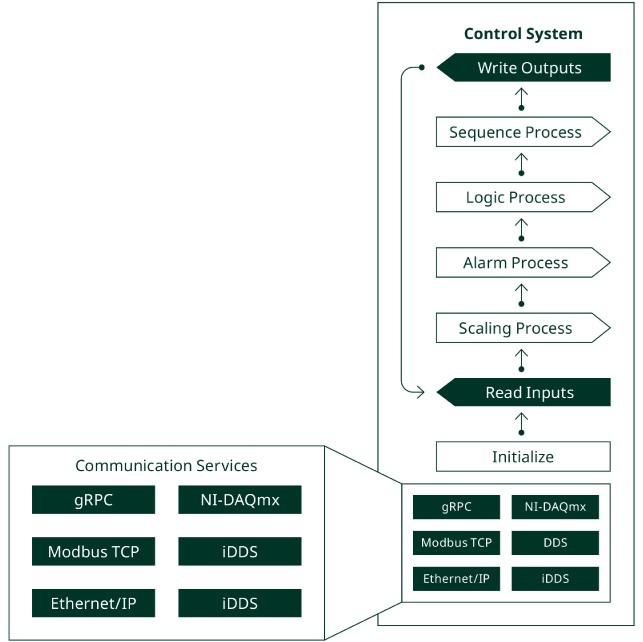
Figura 4. Servicios de comunicación
Un sistema de control lee y escribe comandos remotos y telemetría a través de servicios de comunicación (es decir, ordenar que una válvula se abra o iniciar una secuencia en otro sistema de control remoto que controla una plataforma de soporte). Estos servicios son demonios o microservicios que se ejecutan en segundo plano, en lugar de ejecutarse directamente dentro de la aplicación principal. Usar un servicio para comunicarse, en lugar de confiar en la función de lectura de entradas en sí, permite que la aplicación principal monitoree las métricas del microservicio para que cualquier problema no afecte la ejecución de la aplicación principal. Esto abstrae la comunicación del ciclo de control principal, lo que facilita la actualización de equipos y configuraciones a medida que aparecen nuevos dispositivos con nuevas interfaces de comunicación.
En la Figura 4 se enumeran algunos ejemplos de servicios de comunicación, pero hay muchas opciones para las comunicaciones. El equipo de diseño de la instalación puede establecer un protocolo de comunicación personalizado para la instalación o puede seleccionar protocolos estándares que respalden el equipo utilizado en toda la instalación.
Al comprar nuevos equipos, un factor clave será el soporte para los servicios de comunicación existentes en la instalación. Controlar la cantidad de protocolos de comunicación en el sitio simplifica el desarrollo y el mantenimiento del software. El uso de servicios mejora el proceso cuando se permite un nuevo protocolo de comunicación.

Figura 5. Patrón de diseño del servicio de comunicación
Cada servicio de comunicación deberá diseñarse para cumplir con las necesidades de un dispositivo y protocolo.
Un servicio de comunicación típico tiene algunos elementos comunes. En el núcleo de un servicio hay una máquina de estado, que rastrea el estado actual del hardware y determina el siguiente estado deseado. Por ejemplo, es posible que sea necesario inicializar un dispositivo antes de que se pueda enviar un comando; la máquina de estado rastrea el estado de inicialización del dispositivo, solicita la inicialización y luego solicita que se envíe el comando. El servicio proporciona métricas que pueden ser monitoreadas por otras aplicaciones de red, como cuando un paso expira o se pierde la comunicación con un dispositivo. Estos pueden provocar acciones en otros sistemas.
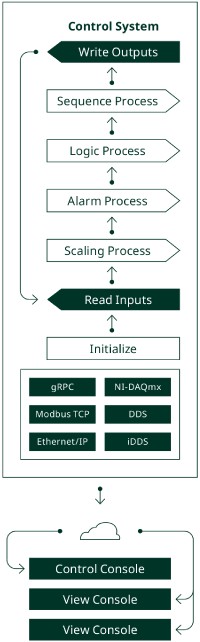
Figura 6. Consolas del operador
Una interfaz de hardware se comunica con el hardware utilizando la API del proveedor.
Una interfaz de comunicación empaqueta los datos para el protocolo, que puede incluir formato específico, metadatos, cifrado o compresión. Algunos protocolos requieren handshaking o administración de configuración, que se pasa a la máquina de estado para su administración.
Para proporcionar acceso al operador, cada sistema de control puede tener una consola de operador o varias consolas. Para evitar confusiones en el sistema de control, normalmente solo hay una consola de control activa. Esto podría ser una consola de control dedicada o una consola con arbitraje de control, lo que permite a un operador solicitar el control.
Una característica de diseño a considerar es la reconfigurabilidad en las consolas. Debido a las cambiantes necesidades de las pruebas entre pruebas, o incluso durante una prueba, los ingenieros de pruebas a menudo necesitan acceso a datos adicionales en estas consolas. Dado que la mayoría de los datos que podrían necesitar están disponibles en los servicios de comunicación, es posible crear consolas que permitan a los usuarios suscribirse a nuevos puntos de datos sin cambios en el código de software real. Esto proporciona flexibilidad a los ingenieros que necesitan los datos y protege el resto del sistema de los cambios realizados en el software. Por ejemplo, la consola puede suscribirse a todos los canales de datos en los servicios de comunicación y permitir que el usuario de la consola seleccione qué señales ver. NI usó este patrón de diseño al crear el Static Data Viewer usando el G Web Development Software
De manera similar, los diseñadores deben considerar si exponer las señales de comando a las consolas del operador de manera configurable. Esto permite a los ingenieros de pruebas cambiar las capacidades de control sin necesidad de actualizaciones del software, lo que aumenta la productividad en el entorno de pruebas de cohetes a ritmo acelerado. Esta capacidad debe diseñarse en el servicio de comunicación que pasa los datos al sistema de control durante el paso de lectura de entradas.
Una consola puede ser un dispositivo o pantalla dedicada para un sistema de control específico o puede combinarse con otras consolas en una estación de operador. Una estación del operador proporciona visualización y control desde una sola ubicación en todo el banco de pruebas.
Al combinar esto, surge una arquitectura completa.
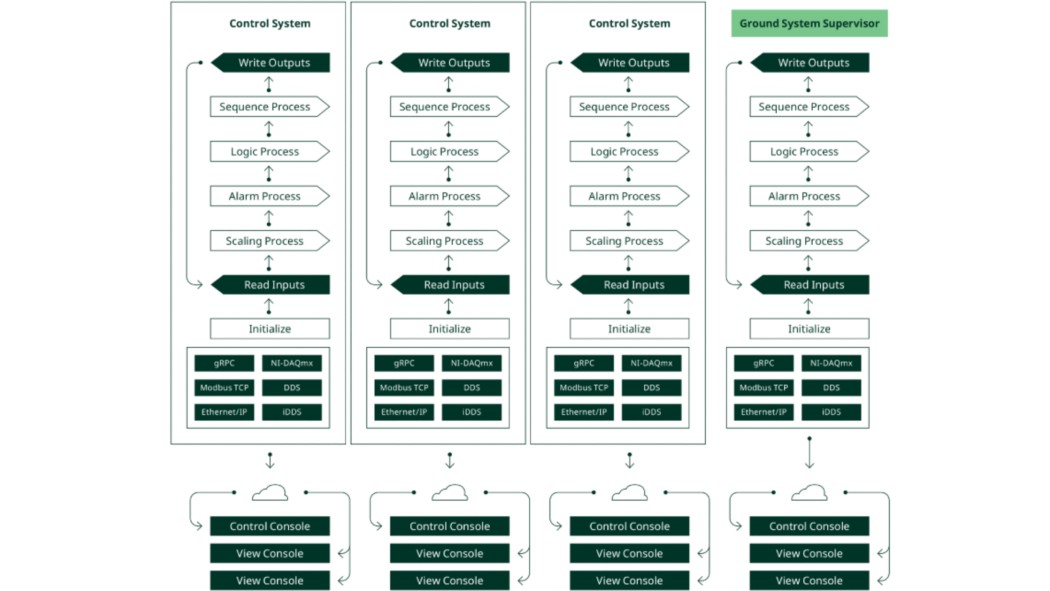
Figura 7. Arquitectura de las instalaciones de pruebas de cohetes
Esta arquitectura presenta estos beneficios:
- Cada sistema se ejecuta independientemente de otros sistemas, lo que evita demoras por esperar a que otro sistema responda.
- Como sistemas independientes, cada sistema puede usar la tecnología más apropiada sin afectar las decisiones sobre las tecnologías en otros sistemas.
- El patrón de diseño común en todos los sistemas simplifica el desarrollo y el mantenimiento para los equipos de hardware y software.
- La arquitectura puede crecer a medida que crecen las instalaciones, soportando cualquier número de bancos de pruebas y sistemas de soporte.
- La arquitectura soporta componentes de cualquier proveedor y se puede actualizar cuando hay nuevas tecnologías disponibles.
Finalmente, completamente ensamblada, una instalación de prueba de cohetes puede verse como la imagen en la Figura 8:
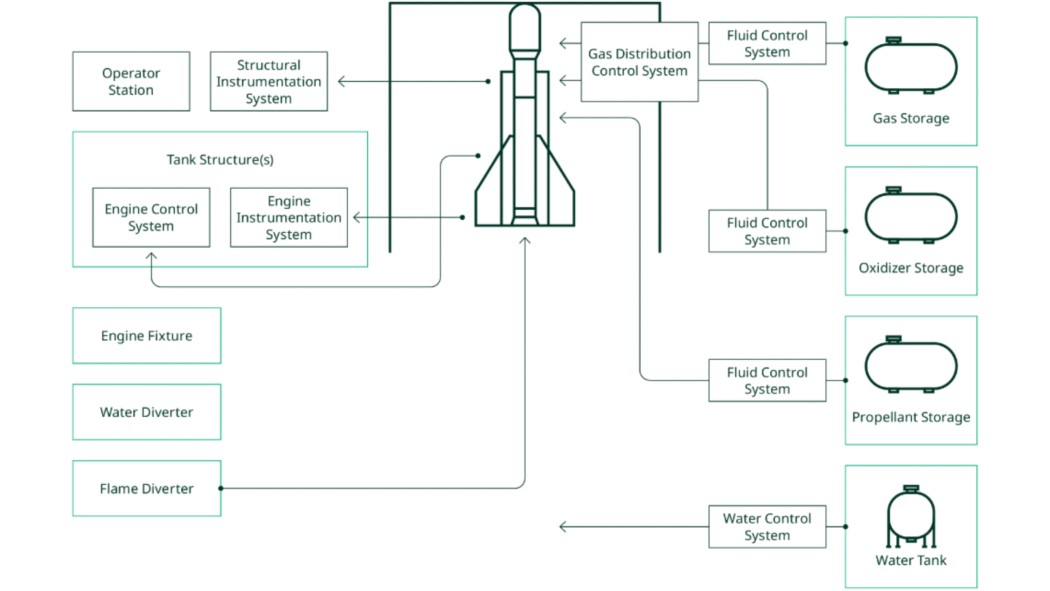
Figura 8. Instalación de pruebas de cohetes
Consideraciones para el diseño de la arquitectura de pruebas
La arquitectura descrita en este documento proporciona un patrón de diseño para el diseño de un sistema de pruebas de cohetes. Hay que tomar muchas decisiones de ingeniería para implementar esta arquitectura. El objetivo de este documento es guiar a un equipo a través de los aspectos de la arquitectura para garantizar que los aspectos más críticos se consideren al inicio del proceso de diseño.
Al tomar decisiones sobre cómo implementar la arquitectura, los siguientes temas han demostrado ser algunos de los más críticos para considerar lo antes posible en el proceso.
Latencia del sistema
Dentro de cada subsistema y en toda la instalación de pruebas, ¿cuál es el peor retraso posible que se puede tolerar para mantener el control y la seguridad en el área de pruebas?
La latencia en todo el sistema es el resultado de varias decisiones de diseño. Los ciclos más rápidos aumentarán la velocidad de comunicación de un componente en un sistema a otro componente en otro sistema. Pero los ingenieros también deben considerar la cantidad de saltos entre sistemas; si los datos deben pasar entre varios sistemas para alcanzar el objetivo final, los retrasos acumulativos serán mayores que si los datos se pueden pasar más directamente entre los sistemas de control. Al tomar decisiones de diseño, considere cómo los datos se ponen a disposición de otros sistemas, directamente o copiándolos varias veces entre los sistemas.
Temporización
Los sistemas repartidos por la instalación tendrán diferentes relojes de tiempo. ¿Qué cantidad de desfase de tiempo puede tolerar en sus medidas?
La mayoría de los sistemas etiquetan las medidas con el reloj del sistema desde el dispositivo local. Al analizar datos entre sistemas, es útil poder correlacionar los datos entre estos sistemas. Una solución común es proporcionar un tiempo absoluto en todos los sistemas, utilizando IEEE-1588 o un protocolo similar. El tiempo puede ser proporcionado por el sistema supervisor de la instalación, o los sistemas pueden depender de una señal GPS para la base de tiempo.
Una consideración relacionada es cómo correlacionar los datos entre la PC de proceso y el sistema de tierra. En una prueba de cohete, esto es bastante sencillo, pero en una situación de lanzamiento esto se vuelve más complicado porque cualquier enlace entre el sistema de tierra y el cohete se perderá en el lanzamiento. Dado que los sistemas de pruebas replican las condiciones de lanzamiento, esto debe tenerse en cuenta al diseñar el banco de pruebas.
Distribución de recursos compartidos
¿Qué subsistemas se compartirán entre los bancos de pruebas y qué subsistemas se dedicarán a un banco de pruebas específico?
Hay dos costos a equilibrar al considerar los recursos compartidos: los costos de duplicar recursos y los costos de compartir recursos. Existe un costo significativo para configurar un sistema de tanque criogénico. Pero ejecutar fluidos criogénicos en dos bancos de pruebas separados también implica un costo y una complejidad significativos. Compartir recursos también puede limitar la capacidad de ejecutar dos actividades en paralelo si ambas requieren que el recurso se ejecute.
Administrar condiciones de carrera
¿Cómo se protegerán los recursos compartidos de las instrucciones en competencia de los sistemas de control?
Cualquier sistema de control que pueda ser controlado por múltiples sistemas de comando corre el riesgo de realizar una acción no deseada debido a la falta de disciplina en el sistema de comunicación. Por ejemplo, una válvula puede iniciar una operación en base a una solicitud de un banco de pruebas, pero si un segundo banco de pruebas sobrescribe el punto de ajuste, el resultado será una falla catastrófica en ambos bancos.
El equipo de diseño debe revisar cuidadosamente el sistema en busca de posibles condiciones de carrera para garantizar que exista un procedimiento de bloqueo adecuado para cualquier señal de comando en el sistema.
Las condiciones de carrera también pueden afectar los datos de medidas si los datos se sobrescriben antes de que un sistema de almacenamiento los recupere; los datos que se recuperan pueden no ser los datos previstos.
Redundancia
¿Qué sistemas deben tener controles redundantes? ¿Qué nivel de redundancia habrá?
La redundancia se puede aplicar en muchos lugares dentro de un sistema; puede haber sensores, cableado, dispositivos de adquisición, procesadores, algoritmos o fuentes de alimentación redundantes. Algunas compañías espaciales requieren triple redundancia en todo el sistema para máxima seguridad. Otros identifican los puntos de falla de mayor riesgo y enfocan los esfuerzos de redundancia en esos puntos de falla.
Hay varios modelos de redundancia que el equipo de diseño puede elegir para cada punto del sistema. En la redundancia en espera, una unidad secundaria idéntica respalda a la unidad primaria. En un sistema de espera en frío, la unidad secundaria está inactiva y opera solo cuando un watchdog identifica que la unidad primaria ha fallado. En un sistema de espera en caliente, la unidad secundaria se enciende y monitorea activamente el sistema, pero sus salidas no se utilizan hasta que un watchdog le cambia el control. Esto puede acortar el tiempo de inactividad en caso de falla, pero no preserva la fiabilidad de la unidad secundaria, ya que está en funcionamiento activo.
La redundancia modular es similar al enfoque de reserva activa, pero ambos sistemas se ejecutan en paralelo y ambos generan salidas para el sistema. Un sistema de votación, a veces llamado subastador o votante, decide qué salidas deben usarse. Esto proporciona transferencias sin interrupciones en caso de una falla de uno de los controladores. Este modelo se puede extender más allá de dos controladores a múltiples controladores. Estos y otros ejemplos se discuten en la nota técnica de NI sobre conceptos básicos del sistema redundante.
Requisitos ambientales
¿A qué entornos estará sujeto el equipo de medidas? ¿Qué infraestructura adicional necesitamos para proteger el equipo de medidas y control?
Durante una prueba de propulsión, el equipo en o cerca del stand estará sujeto a condiciones ambientales extremas. Estos pueden incluir golpes repentinos, vibración continua y altas temperaturas.
Entre pruebas, el equipo también estará sujeto a condiciones ambientales extremas. Las temperaturas calientes o frías, la humedad y la niebla salina son amenazas específicas para la disponibilidad del equipo para una prueba.
Los ingenieros deben conocer las condiciones ambientales del banco de pruebas. Con esa información, deben seleccionar o diseñar equipos que excedan los requisitos potenciales del sistema. Esto puede requerir que compren equipos robustos, agreguen protección como capa de conformación o protejan el equipo en un gabinete o en un anexo con control ambiental.
Topología de la red
¿Qué tecnologías de red proporcionarán el rendimiento óptimo para la transferencia de datos en la red, incluyendo la redundancia en caso de falla de un componente?
Hay muchas opciones disponibles al diseñar una topología de red. Una topología de instalación exitosa requerirá conversaciones detalladas entre el equipo de infraestructura de TI y los equipos de ingeniería de pruebas. Los equipos de pruebas deberán describir las necesidades de ancho de banda de datos, latencia y tecnología. El equipo de TI deberá comprender el cifrado, el diseño y la redundancia para planificar el diseño de la red.
Entre las decisiones al diseñar la red, el equipo de diseño debe decidir sobre un modelo de redundancia, que puede incluir tender cables de red redundantes en toda la instalación, usar el protocolo de árbol de expansión rápida (RSTP) y usar múltiples conmutadores de distribución.
Cobertura de E/S
¿Qué señales necesitamos medir o controlar?
Una de las primeras tareas que enfrenta el equipo de ingeniería es recopilar una lista de las señales que deben medirse o controlarse en el banco de pruebas. Al documentar las señales, deben enumerar el tipo de señal, la ubicación, la resolución, la velocidad de datos, las necesidades de excitación, las necesidades de seguridad y los niveles de voltaje y corriente.
Con esta información, los ingenieros pueden recopilar las señales en bancos de medidas y luego seleccionar el hardware adecuado para proporcionar acceso a todas las señales.
Ancho de banda de datos
¿Puede la topología de red manejar la cantidad de datos esperados durante una prueba?
El diseño de la red, incluidos los dispositivos de cómputo, el hardware del conmutador y la arquitectura de la subred, establece el límite de la cantidad de datos que se pueden mover a través de la red. El equipo de diseño debe revisar cuidadosamente los componentes de la red, buscando cuellos de botella en el sistema.
Un cálculo teórico puede proporcionar una guía para el diseño de un sistema, pero las aplicaciones de red nunca alcanzan velocidades de datos teóricas completas. La sobrecarga de datos y las latencias afectan el rendimiento total de la red. Al diseñar una red, es recomendable mantener las velocidades de datos significativamente por debajo del límite teórico.
Seguridad
¿Qué sistemas de seguridad se requerirá que estén implementados?
Una instalación de cohetes tiene muchas condiciones peligrosas. Un error en el diseño, implementación u operación de los sistemas puede resultar en un accidente catastrófico. El equipo de diseño debe conocer los protocolos de seguridad requeridos por las leyes federales y locales. El equipo de diseño también debe considerar cómo proteger al personal, el equipo y el área asociada con la estación de pruebas de maneras que no están cubiertas por las leyes.
Algunas de las áreas en una instalación de cohetes son zonas peligrosas debido a los gases utilizados para impulsar el motor del cohete. Algunos de estos gases no se pueden contener por completo, creando una zona donde cualquier chispa eléctrica puede provocar un incendio o una explosión. Para evitar esta situación, cualquier equipo en el área peligrosa debe ser intrínsecamente seguro, es decir, incapaz de generar una chispa. Esto se puede manejar moviendo el equipo eléctrico fuera de la zona peligrosa. Una válvula controlada eléctricamente se puede colocar fuera de la zona, de modo que el único equipo en la zona sea la tubería que se aleja de la válvula.
Si un dispositivo debe ubicarse dentro de la zona peligrosa, el proveedor del equipo debe certificar que el equipo es intrínsecamente seguro. En los EE. UU., esto significa certificación Clase 1 Div 1. En Europa, esto significa la certificación ATEX basada en el tipo de gas.
Si un dispositivo está fuera de la zona peligrosa, pero ejecuta una señal en él, el dispositivo debe tener una barrera intrínseca para evitar que una chispa generada en el dispositivo pase a la zona. Incluso los dispositivos de bajo nivel, como los instrumentos de medidas de termopares, requieren una barrera intrínseca para evitar que la energía del dispositivo (como una fuente de alimentación conectada) pase a la zona. Se puede conectar una barrera intrínseca en la ruta de la señal entre el dispositivo y la zona peligrosa y proporciona protección contra picos de voltaje y corriente. Tenga en cuenta que las barreras intrínsecas varían según el tipo de señal, por lo que una barrera diseñada para un termopar no sería apropiada para un controlador de válvula.
Certificaciones
¿Qué certificaciones deben cumplir las instalaciones, los sistemas de soporte y el banco de pruebas?
Se requieren diferentes certificaciones para diferentes áreas según la población, el propósito de la instalación, las leyes locales y el propósito del equipo del cohete. Por ejemplo, una prueba de cohete realizada en una base de la fuerza aérea de los E.E. U.U. puede requerir la certificación AFSPCMAN 91-7108 antes de cualquier actividad de cohetes.
Además de las certificaciones requeridas para realizar la prueba, las certificaciones afectan el objetivo de la prueba. Si el propósito de la prueba es certificar el motor cohete para su uso, el diseño del banco de pruebas debe cumplir con las demandas de esa certificación. Por ejemplo, MIL-STD-8109 garantiza que el dispositivo que se está probando cumple con las condiciones esperadas de uso del producto. MIL-STD-20210 garantiza que los componentes de menos de 300 lbs cumplen con los requisitos eléctricos y ambientales de una aplicación exigente. Estos pueden ser necesarios si el departamento de defensa de los E.E. U.U. es un cliente previsto de la tecnología que se está probando.
Pasos de implementación
Diseñar una instalación de pruebas de cohetes, con el banco de pruebas y los sistemas de soporte, es un proyecto grande y orientado a los detalles. El propósito de este documento es proporcionar un patrón de diseño general y un enfoque para el proceso de diseño. Está fuera del alcance de este documento describir cada paso del proceso, pero el proceso de diseño seguirá estos pasos básicos. Si este proceso está más allá de las capacidades de su equipo de diseño, consulte la siguiente sección de servicios para obtener información sobre cómo involucrar a NI y a los socios de NI en el proceso de diseño.
Identificar sistemas
Salida: Diagrama de bloques de sistemas y subsistemas que se diseñarán en la instalación
Comience por diseñar los sistemas de las instalaciones. Utilizando las necesidades actuales y futuras de la instalación, planifique el banco de pruebas y las ubicaciones del sistema de soporte. Plan para la transferencia entre los sistemas y las conexiones entre ellos. Decida qué sistemas de soporte se compartirán y cuáles se dedicarán al banco de pruebas.
Cree requisitos del sistema
Salida: Requisitos detallados para cada sistema y subsistema que se diseñará en la instalación
Para cada uno de los sistemas identificados, documente los requisitos. Enumere las entradas y salidas esperadas, incluyendo velocidades de actualización y protocolo de comunicación. Documente la funcionalidad esperada del sistema, incluyendo el rendimiento requerido. Decida qué equipo funcional de la compañía será responsable de diseñar cada uno de los sistemas.
Identifique los requisitos de toda la instalación
Salida: Requisitos detallados de los sistemas y la infraestructura que unirán la instalación
Usando los requisitos del sistema, identifique el rendimiento requerido del sistema de la instalación para soportar esos sistemas. Documente la velocidad de actualización necesaria para cumplir con los requisitos de latencia de todos los sistemas y componentes. Trabaje con el equipo de TI para delinear los requisitos de infraestructura de red para cumplir con las necesidades de los sistemas. Calcule las velocidades de datos de los peores escenarios en el sistema.
Seleccione tecnologías
Salida: Lista de tecnologías que cubren los requisitos del sistema y las instalaciones
Utilizando los requisitos del sistema y de las instalaciones, identifique las tecnologías específicas que se adquirirán o desarrollarán para cumplir con las necesidades documentadas. Reúnase con los proveedores para identificar las tecnologías comerciales que se pueden utilizar. Trabaje con los equipos de ingeniería para identificar un enfoque de ingeniería personalizado para las brechas restantes en los sistemas. Siempre que sea posible, pruebe el rendimiento de los sistemas para garantizar que cumplan con los requisitos.
Servicios de comunicación de diseño
Salida: Documente los requisitos y la implementación de cada uno de los servicios de comunicación que se utilizarán para los sistemas y el equipo de la instalación
Con una buena comprensión de las tecnologías disponibles para los sistemas, documente las necesidades de cada uno de los servicios de comunicación. Identifique las entradas, salidas y procesamiento de cada uno de los servicios. Identifique la experiencia necesaria para implementar completamente los servicios.
Diseñe los controladores del sistema
Salida: Documentos de diseño para cada uno de los controladores del sistema en la instalación
Aplique los requisitos del sistema a las tecnologías seleccionadas para los sistemas y la instalación. Documente las entradas, salidas y funcionalidad deseadas con criterios de rendimiento específicos. Identifique la experiencia necesaria para implementar los controladores del sistema.
Implemente controladores del sistema y servicios de comunicación
Salida: Código que se ejecuta en cada uno de los controladores del sistema y entre sistemas
Desarrolle el código que se ejecuta en cada uno de los controladores del sistema y en cada servicio de comunicación. Documente cualquier cambio de los documentos de requisitos y verifique que los cambios no tengan impacto en otros sistemas. Aplique principios de ingeniería adecuados al desarrollo, incluyendo pruebas de unidades para verificar que cada componente cumpla con los requisitos documentados.
Conecte controladores del sistema
Salida: Actualizaciones de valores entre sistemas de control
Conecte los controladores del sistema y los servicios de comunicación. Verifique que los sistemas funcionen correctamente y dentro de los límites de rendimiento esperados. Continúe ejecutando pruebas de unidades en componentes, subsistemas y sistemas a medida que se conectan.
Valide el rendimiento del sistema
Salida: Validación del rendimiento de cada componente del sistema, sistema y sistemas interconectados
Con el sistema completo implementado, realice pruebas de validación completas de los sistemas y del sistema en general. Revise los requisitos para verificar que se cumplan todos los requisitos. Informe a los desarrolladores sobre cualquier comportamiento inesperado e itere hasta obtener el rendimiento deseado.
Cree estaciones de operador y visores
Salida: Pantallas del operador y estaciones para controlar y ver los sistemas
Las consolas del operador se desarrollarán junto con los sistemas; aplicar mejoras de usabilidad a las consolas y crear las consolas finales del operador.
Tecnologías emergentes para pruebas de motores de cohetes
Hay varios avances recientes en la tecnología disponible que se pueden utilizar en esta arquitectura de pruebas de cohetes.
gRPC
gRPC es un framework de código abierto y alto rendimiento que puede ejecutarse en cualquier entorno. Desarrollado por Google y basado en la llamada a procedimiento remoto (RPC), gRPC ha crecido rápidamente en popularidad en los últimos cinco años como una forma de pasar datos entre partes de un sistema. Al usar gRPC, una aplicación cliente puede llamar directamente a un método en una aplicación de servidor en una máquina diferente como si fuera un objeto local. Esto simplifica la creación de una arquitectura distribuida como la arquitectura de pruebas de cohetes. Las herramientas de software y hardware de NI funcionan con gRPC. Obtenga información sobre recursos de soporte y compatibilidad de gRPC.
iDDS
iDDS es un protocolo de abstracción de datos desarrollado para pruebas de motores de turbina de jet por Rolls Royce y MDS Aero. Proporciona un servicio de comunicación para recopilar datos de los nodos de instrumentos, que está disponible para los suscriptores en la red. iDDS se basa en la red principal del servicio de distribución de datos (DDS) y el estándar del grupo de administración de objetos (OMG). iDDS define el paquete de datos de instrumentación en la red DDS, incluyendo datos de medidas como metadatos del canal, estampa de tiempo, configuración y monitoreo de estado. Debido a que la comunicación entre dispositivos está estandarizada dentro del modelo iDDS, las características específicas del proveedor se abstraen, lo que facilita el intercambio de equipos cuando hay nueva tecnología disponible, incluso si es de un nuevo proveedor.
Soluciones de NI personalizadas para pruebas avanzadas de motores de cohetes
NI proporciona soluciones personalizadas de hardware y software para pruebas de motores de cohetes, integrando los cambiantes requisitos de seguridad, nuevos sensores y tecnologías demandadas por el mercado. Nuestro software proporciona herramientas para soluciones de pruebas personalizadas, visualización de datos en tiempo real, registro y secuencia de pruebas automatizadas. Estas soluciones de software mejoran el análisis de datos, la administración de instalaciones y la eficiencia general de las pruebas a través de plataformas potentes y adaptables.
Las plataformas de hardware, como NI PXI, NI CompactDAQ y NI CompactRIO, están diseñadas para soportar condiciones extremas y soportar una amplia variedad de señales, asegurando medidas y control confiables y precisos durante las pruebas de motores de cohetes. Estos sistemas robustos y modulares proporcionan medidas distribuidas y capacidades de procesamiento local, mejorando la precisión y flexibilidad de las pruebas. Explore nuestras soluciones para probar la propulsión de motores de cohetes para ver cómo probar más motores en un cronograma más corto que nunca.
Próximos pasos
Notas al pie y referencias
Notas al pie:
1 https://arstechnica.com/science/2022/01/thanks-to-china-and-spacex-the-world-set-an-orbital-launch-record-in-2021
2 https://www.go-astronomy.com/space-ports.php
3 https://www.ecfr.gov/current/title-14/chapter-III
4 https://ntrs.nasa.gov/api/citations/20050182932/downloads/20050182932.pdf
Referencias
Un partner de NI es una entidad comercial independiente de NI y no tiene agencia o relación de empresa conjunta con NI y no forma parte de ninguna asociación comercial con NI.