Optimizing LabVIEW Embedded Applications
Overview
When developing an embedded application, system constraints such as memory limitations and time-critical code requirements can play a crucial role in your programming approach. You can't afford the software implementation to have any bottlenecks. This document outlines good programming practices that you can use to optimize your embedded application. The techniques described are applicable for any ARM, Blackfin, or embedded target.
Contents
- Memory Allocation
- Data Placement
- Numeric Conversion
- Functions and Data Types to Avoid
- Using the Inline C Node
- Optimal Build Settings
- Conclusion
Memory Allocation
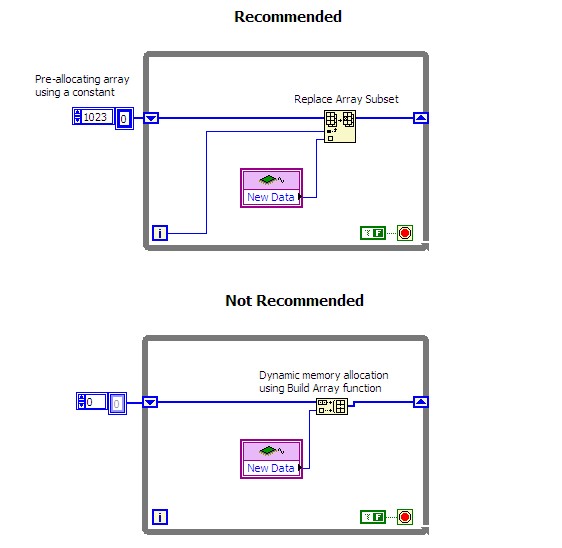
Avoid dynamic memory allocation. Dynamic memory allocation is very expensive in time-critical code. In LabVIEW embedded applications, dynamic memory allocation can occur when you use the Build Array and Concatenate Strings functions. Alternatively, you can use the Replace Array Subset function instead of a Build Array function to replace elements in a preallocated array. You should use an array constant or the Initialize Array function to create the preallocated array outside of the loop. The following figure contrasts the different implementations.
Data Placement
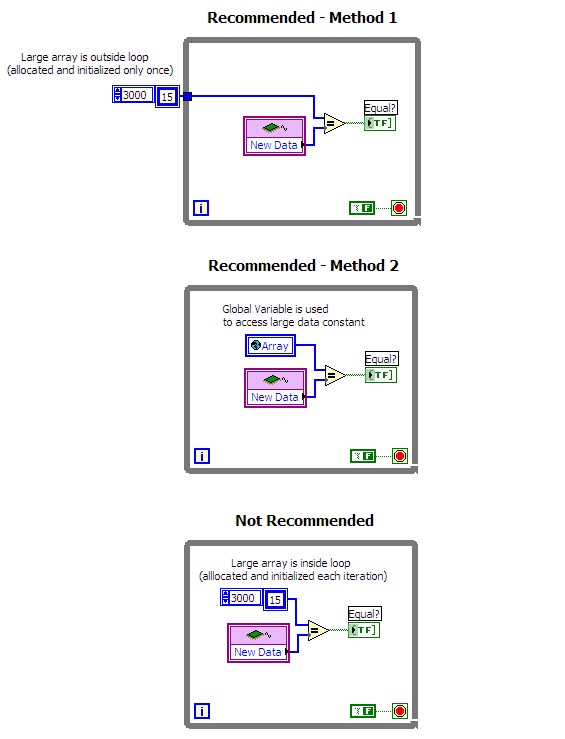
Avoid placing large constants inside loops. When you place a large constant inside a loop, LabVIEW allocates memory and initializes the array at the beginning of each iteration of the loop. This can be an expensive operation in time-critical code. Instead, place the array outside of the loop and wire it to through a loop tunnel or use a global variable to access the data. The following figure demonstrates the recommended methods.
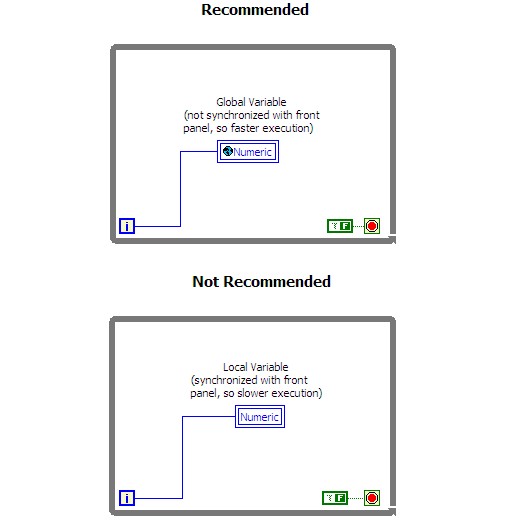
Use global variables instead of local variables. Every time a local variable is accessed, extra code is executed to synchronize it with the front panel. You can often improve code performance by using a global variable instead of a local variable. The global variable has no extra front panel synchronization code and as a result, executes slightly faster than a local variable. The following figure contrasts the different implementations.
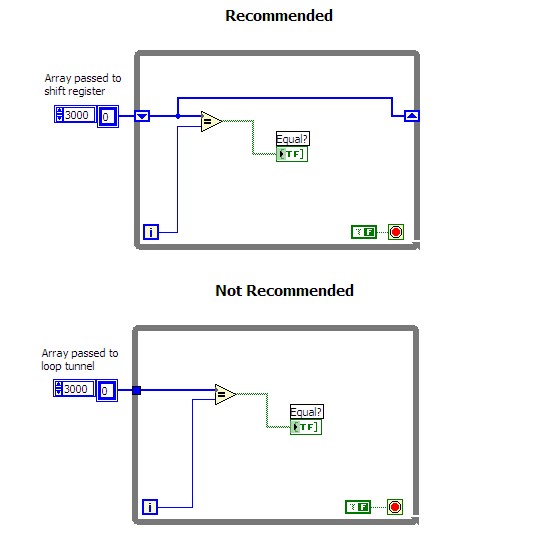
Use shift registers instead of loop tunnels for large arrays. When passing a large array through a loop tunnel, the original value must be copied into the array location at the beginning of each iteration, which can be expensive. The shift register does not perform this copy operation. You must wire the left shift register to the right shift register if you don’t want the data values to change. The following figure contrasts the different implementations.
Numeric Conversion
Use integer operations instead of floating point operations. If your processor does not have a floating point unit, converting to floating point to perform an operation and then converting back to an integer data type can be very expensive. The following figure demonstrates how using a Quotient & Remainder function is faster than a normal Divide function, and how using a Logical Shift function is faster than a Scale by Power of 2 function.

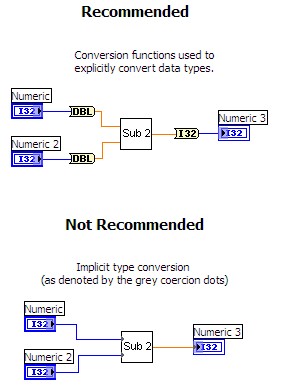
Avoid automatic numeric conversions. Another technique for improving code performance is to remove all implicit type conversions (coercion dots). Use the Conversion functions to explicitly convert data types because it avoids a copy operation and a data type determination. The following figure contrasts the different implementations.
Functions and Data Types to Avoid
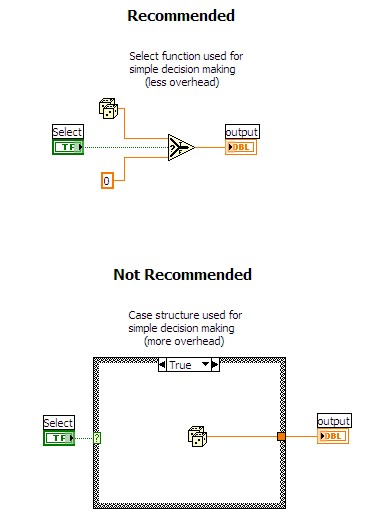
Avoid Case structures for simple decision making. For simple decision making in LabVIEW, it is often faster to use the Select function rather than a Case structure. Because each case in a Case structure can contain its own block diagram, there is significantly more overhead associated with this structure when compared with a Select function. However, it is sometimes more optimal to use a Case structure if one case executes a large amount of code and the other cases execute very little code. The decision to use a Select function versus a Case structure should be made on a case-by-case basis. The following figure contrasts the different implementations.
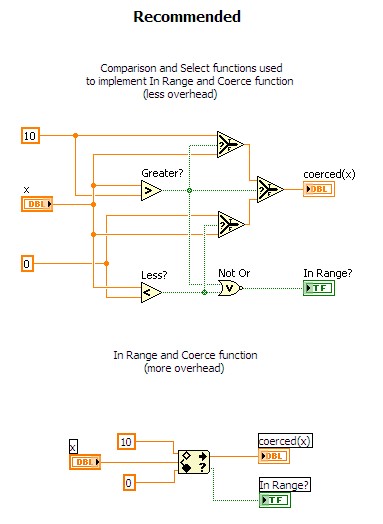
Avoid the In Range and Coerce function in time-critical code. The In Range and Coerce function has significant overhead associated with it due to special user configurable features and extra data type determination operations. You should re-implement this function with Comparison and Select functions if it is used in time-critical code. The following figure contrasts the different implementations.
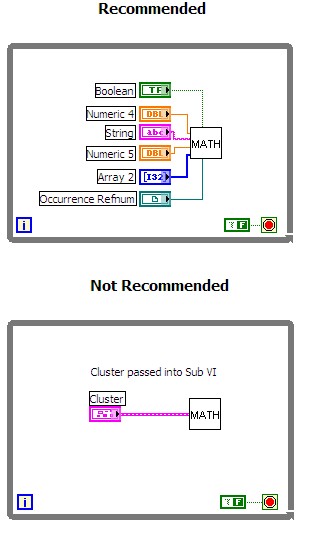
Avoid clusters in time-critical code. Clusters passed into subVIs result in unnecessary data type information being passed as well. To speed up your code, avoid using clusters in time-critical areas of your block diagram. The following figure contrasts the different implementations.
Using the Inline C Node
Often you can obtain the best results by using a hybrid of LabVIEW and C code. The Inline C Node and Call Library Function Node allow you to use C code directly within your LabVIEW block diagram. Refer to the LabVIEW Help (linked below) for more information on the Inline C Node and Call Library Function Node.
The best cases for using C-based algorithms within your LabVIEW code are:
1) You already have existing C algorithms that you’d like to reuse.
2) There is a small numeric or array algorithm that can be coded more optimally in C.
Optimal Build Settings
Code typically executes in the fastest time if you use the following build settings:
| Build Setting | Purpose |
|---|---|
| Generate Serial Only = TRUE | Increases performance in code with parallel operations. |
| Generate Debug Info = FALSE | Removes calls to debug code. |
| Generate Guard Code = FALSE | Removes extra protective code from math and array routines. |
| Generate Integer Only = TRUE | Improves performance on targets without a floating point unit. |
| Use Stack Variables = TRUE | Uses stack space rather than statically allocated memory locations. |
| Generate C Function Calls = TRUE | Generates more efficient code when calling subVIs; however, you must wire all inputs to all subVIs. |
Conclusion
By following good embedded programming practices, you can better optimize your code to meet the constraints of your embedded application. Implementing one or two these techniques might noticeably improve the performance of your application, but the best approach is to incorporate a combination of all these techniques.