Der LabVIEW-Compiler von NI: So funktioniert er
Überblick
Inhalt
- Kompilierung vs. Interpretation
- Die Entwicklungsgeschichte des LabVIEW-Compilers
- Der heutige Kompilierprozess
- DFIR und LLVM arbeiten Hand in Hand
Im vorliegenden Dokument wird die Entwicklung des LabVIEW-Compilers vorgestellt, von seinen Anfängen im Jahr 1986 mit LabVIEW 1.0 bis zu seiner heutigen Form. Darüber hinaus werden aktuelle Compiler-Innovationen besprochen und die Vorteile dieser Neuerungen für die LabVIEW-Architektur und für Sie hervorgehoben.
Kompilierung vs. Interpretation
LabVIEW ist eine kompilierte Sprache. Das mag überraschen, denn bei der typischen Entwicklung mit G gibt es keinen expliziten Kompilierschritt. Stattdessen wird eine Änderung am eigenen VI vorgenommen und auf die Schaltfläche „Ausführen“ geklickt. Bei der Kompilierung wird der in G geschriebene Code in nativen Maschinencode übersetzt und dann direkt vom Host-Computer ausgeführt. Eine Alternative zu diesem Ansatz ist die Interpretation von Daten. Dabei werden Programme indirekt durch ein anderes Softwareprogramm (den so genannten Interpreter) statt direkt durch den Computer ausgeführt.
Die LabVIEW-Sprache erfordert weder explizit eine Kompilierung noch eine Interpretation. Tatsächlich verwendete die erste LabVIEW-Version einen Interpreter. In späteren Versionen wurde dieser durch den Compiler ersetzt, um die Ausführungsgeschwindigkeit von VIs zu verbessern. Dies ist ein wesentlicher Vorteil von Compilern gegenüber Interpretern. Interpreter sind in der Regel einfacher zu schreiben und zu warten, bieten aber eine schlechtere Ausführungsleistung. Compiler sind dagegen komplexer zu implementieren, sorgen aber für eine schnellere Ausführung. Einer der größten Vorteile des LabVIEW-Compilers besteht darin, dass am Compiler vorgenommene Verbesserungen auf alle VIs übertragen werden, ohne dass Änderungen notwendig sind. Tatsächlich lag einer der Schwerpunkte von LabVIEW 2010 auf der Optimierung des Compilers, um die Ausführungsdauer von VIs zu verkürzen.
Die Entwicklungsgeschichte des LabVIEW-Compilers
Bevor der heutige Compiler ausführlich besprochen wird, lohnt sich ein Blick auf die Entwicklung des Compilers seit seinen Anfängen vor mehr als 20 Jahren. Auf einige der hier vorgestellten Algorithmen wie Type Propagation, Clumping und Inplaceness wird im Abschnitt zum modernen LabVIEW-Compiler näher eingegangen.
LabVIEW 1.0 wurde im Jahr 1986 veröffentlicht. Wie bereits erwähnt, verwendete LabVIEW in seiner ersten Version einen Interpreter und war nur für den Motorola 68000 gedacht. Die LabVIEW-Sprache war damals noch viel einfacher, wodurch auch die Anforderungen an den Compiler (damals noch Interpreter) geringer waren. So gab es keine Polymorphie und der einzige numerische Typ war die Fließkommazahl (erweitert). Mit LabVIEW 1.1 wurde der Inplaceness-Algorithmus oder „Inplacer“ eingeführt. Dieser Algorithmus erkennt Datenzuweisungen, die während der Ausführung wiederverwendet werden können. Dadurch lassen sich unnötige Datenkopien vermeiden, was wiederum die Ausführungsleistung deutlich verbessert.
In LabVIEW 2.0 wurde der Interpreter durch einen echten Compiler ersetzt. LabVIEW war weiterhin ausschließlich für den Einsatz mit dem Motorola 68000 ausgelegt, konnte nun aber nativen Maschinencode generieren. Mit der Version 2.0 wurde zudem der Type-Propagation-Algorithmus eingeführt, der unter anderem für die Syntaxprüfung und die Typauflösung für die wachsende LabVIEW-Sprache zuständig ist. Eine weitere große Innovation von LabVIEW 2.0 war die Einführung des Clumpers. Der Clumping-Algorithmus erkennt Parallelitäten im LabVIEW-Diagramm und gruppiert Knoten in Datenklumpen, die parallel ausgeführt werden können. Die Type-Propagation-, Inplaceness- und Clumping-Algorithmen sind auch heute wichtige Bestandteile des modernen LabVIEW-Compilers und haben im Laufe der Zeit zahlreiche Verbesserungen erfahren. Die neue Compiler-Infrastruktur in LabVIEW 2.5 bot Unterstützung für mehrere Backends, insbesondere Intel x86 und Sparc. In LabVIEW 2.5 wurde außerdem der Linker eingeführt, der Abhängigkeiten zwischen VIs verwaltet, um nachzuverfolgen, wann diese neu kompiliert werden müssen.
LabVIEW 3.1 wurde um zwei neue Backends, PowerPC und HP PA-RISC, sowie die Konstantenfaltung erweitert. LabVIEW 5.0 und 6.0 wiesen einen überarbeiteten Codegenerator auf und die GenAPI wurde hinzugefügt, eine gemeinsame Schnittstelle für verschiedene Backends. Die GenAPI ermöglicht eine Cross-Kompilierung, welche für die Echtzeitentwicklung wichtig ist. Echtzeitentwickler schreiben VIs in der Regel auf einem Host-PC, verteilen diese jedoch auf (und kompilieren sie für) ein Echtzeit-Zielsystem. Darüber hinaus umfasste diese Version eine eingeschränkte Form der Loop Invariant Code Motion. Schließlich wurde das LabVIEW-Multitasking-Ausführungssystem dahingehend erweitert, dass es mehrere Threads unterstützt.
LabVIEW 8.0 baute auf der in Version 5.0 eingeführten GenAPI-Infrastruktur auf und führte einen Algorithmus für die Registerzuteilung ein. Vor der Einführung der GenAPI waren die Register für jeden Knoten fest in den erzeugten Code programmiert. Eingeschränkte Formen von Unreachable Code und Dead Code Elimination (Eliminierung von nicht erreichbarem bzw. totem Code) wurden ebenfalls eingeführt. LabVIEW 2009 umfasste eine 64-bit-LabVIEW-Version und Dataflow Intermediate Representation (DFIR). DFIR kam sofort zum Einsatz, um anspruchsvolle Formen von Loop Invariant Code Motion, Konstantenfaltung sowie Dead Code Elimination und Unreachable Code Elimination zu erstellen. Neue Sprachfunktionen, die 2009 eingeführt wurden, wie die parallele For-Schleife, basieren auf der DFIR.
In LabVIEW 2010 ermöglicht die DFIR neue Compiler-Optimierungen wie algebraische Neuzuordnung, Eliminierung gemeinsamer Unterausdrücke, Auflösung von Schleifen und SubVI-Inlining. Bei dieser Version wurde außerdem eine Low-Level Virtual Machine (LLVM) in die LabVIEW-Compiler-Kette integriert. LLVM ist eine Open-Source-Compiler-Infrastruktur, die in der Industrie weit verbreitet ist. LLVM ermöglicht neue Optimierungen, beispielsweise Instruction Scheduling, Loop Unswitching, Instruction Combining, Conditional Propagation und eine weiterentwickelte Registerzuteilung.
Der heutige Kompilierprozess
Mit diesem grundlegenden Wissen über die Entwicklung des LabVIEW-Compilers können wir uns nun dem Kompilierprozess im modernen LabVIEW widmen. Sie erhalten zunächst einen Überblick über die verschiedenen Schritte der Kompilierung, die anschließend näher erläutert werden.
Der erste Schritt bei der Kompilierung eines VIs ist der Type-Propagation-Algorithmus. Dieser komplexe Schritt dient der Auflösung implizierter Typen für Anschlüsse, die an Typen angepasst werden können, und der Erkennung von Syntaxfehlern. Während des Type-Propagation Algorithmus werden alle möglichen Syntaxfehler in der Programmiersprache G erkannt. Wenn der Algorithmus feststellt, dass das VI gültig ist, wird die Kompilierung fortgesetzt.
Nach der Type Propagation wird das VI von dem vom Blockdiagramm-Editor verwendeten Modell in das vom Compiler verwendete DFIR-Modell konvertiert. Nach der DFIR-Konvertierung führt der Compiler mehrere Transformationen auf dem DFIR-Graphen aus, um das VI zu zerlegen, zu optimieren und für die Programmcode-Erzeugung vorzubereiten. Viele der Compiler-Optimierungen – beispielsweise Inplacer und Clumper – werden als Transformationen implementiert und in diesem Schritt ausgeführt.
Der optimierte und vereinfachte DFIR-Graph wird in eine LLVM-Zwischendarstellung übertragen. Die Zwischendarstellung wird einer Reihe von LLVM-Durchläufen unterzogen, um sie weiter zu optimieren und schließlich in Maschinencode umzuwandeln.
Type Propagation
Wie bereits erwähnt, löst der Type-Propagation-Algorithmus Typen auf und erkennt Programmierfehler. Tatsächlich hat dieser Algorithmus mehrere Aufgaben, unter anderem:
- Auflösen impliziter Typen für Anschlüsse, die sich an verschiedene Typen anpassen lassen
- Auflösen von SubVI-Aufrufen und Bestimmen ihrer Gültigkeit
- Berechnung der Verbindungsrichtung
- Prüfen auf Zyklen im VI
- Erkennen und Melden von Syntaxfehlern
Dieser Algorithmus wird nach jeder Änderung am VI ausgeführt, um festzustellen, ob das VI noch ausführbar ist. Ob dieser Schritt wirklich Teil der „Kompilierung“ ist, ist daher diskutabel. Dieser Schritt in der LabVIEW-Kompilierkette entspricht jedoch am ehesten der lexikalischen, Formel- und semantischen Analyse in einem traditionellen Compiler.
Ein einfaches Beispiel für einen Anschluss, der an Typen angepasst werden kann, ist die Funktion „Addieren“ in LabVIEW. Wenn zwei Integer addiert werden, ist das Ergebnis ein Integer. Werden jedoch zwei Fließkommazahlen addiert, ist das Ergebnis eine Fließkommazahl. Ähnliche Muster gelten für zusammengesetzte Datentypen wie Arrays und Cluster. Es gibt auch andere Sprachenkonstrukte wie Schieberegister, die komplexeren Typisierungsregeln unterliegen. Bei der Funktion „Addieren“ wird der Ausgabetyp durch den Eingangstypen bestimmt, und der Typ wird durch das Diagramm „weitergegeben“ (propagate), daher der Name des Algorithmus.
Dieses Beispiel demonstriert auch die Syntaxprüfung durch den Type-Propagation-Algorithmus. Angenommen, ein Integer und ein String werden mit der Funktion „Addieren“ verbunden. Was sollte passieren? In diesem Fall ist das Addieren dieser beiden Werte kein sinnvoller Schritt. Der Type-Propagation-Algorithmus meldet dies daher als Fehler und markiert das VI als „fehlerhaft“, wodurch der Ausführungspfeil unterbrochen wird.
Zwischendarstellungen – was sind sie und wozu gibt es sie?
Nachdem der Type-Propagation-Algorithmus festgestellt hat, dass ein VI gültig ist, wird die Kompilierung fortgesetzt und das VI in die DFIR übersetzt. Bevor die DFIR im Detail beschrieben wird, sollten Zwischendarstellungen (intermediate representations, IRs) im Allgemeinen betrachtet werden.
Eine IR ist eine Darstellung des Benutzerprogramms, das während der verschiedenen Phasen der Kompilierung verändert wird. Zwischendarstellung ist in der Literatur zu modernen Compilern ein gängiger Begriff und kann auf jede beliebige Programmiersprache angewendet werden.
Nachfolgend finden Sie einige Beispiele. Es gibt heute eine Vielzahl verbreiteter IRs. Zwei gängige Beispiele sind abstrakte Syntaxbäume (AST) und Drei-Address-Codes.
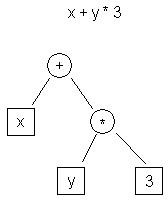 | t0 <- y t1 <- 3 t2 <- t0 * t1 t3 <- x t4 <- t3 + t2 |
| Abbildung 1: Beispiel für einen AST | Tabelle 1: Beispiel für einen Drei-Address-Code |
Abbildung 1 zeigt die AST-Darstellung des Ausdrucks „x + y * 3“, während Tabelle 1 die Drei-Address-Code-Darstellung zeigt.
Ein offensichtlicher Unterschied zwischen diesen beiden Darstellungen besteht darin, dass der AST eine High-Level-Darstellung ist. Sie liegt näher an der Quelldarstellung des Programms (C) als an der Zieldarstellung (Maschinencode). Der Drei-Address-Code ist im Gegensatz dazu eine Low-Level-Darstellung und ähnelt einer Assembly.
Sowohl High- als auch Low-Level-Darstellungen haben ihre Vorteile. Beispielsweise sind Analysen wie Abhängigkeitsanalysen mit einer High-Level-Darstellung wie dem AST einfacher durchzuführen als mit einer Low-Level-Darstellung wie dem Drei-Address-Code. Andere Optimierungen, z. B. die Registerzuteilung oder das Instruction Scheduling, werden in der Regel mit einer Low-Level-Darstellung wie dem Drei-Address-Code durchgeführt.
Da jede IR unterschiedliche Stärken und Schwächen hat, verwenden viele Compiler (einschließlich LabVIEW) mehrere IRs. Im Fall von LabVIEW wird die DFIR als High-Level-Zwischendarstellung genutzt, während die LLVM-IR als Low-Level-Zwischendarstellung verwendet wird.
DFIR
In LabVIEW wird als High-Level-Darstellung die DFIR verwendet, welche hierarchisch und graphenbasiert ist und dem G-Code selbst ähnelt. Wie G besteht auch die DFIR aus verschiedenen Knoten, die jeweils alle über Anschlüsse verfügen. Anschlüsse können mit anderen Anschlüssen verbunden werden. Einige Knoten wie Schleifen enthalten Diagramme, die wiederum weitere Knoten enthalten können.
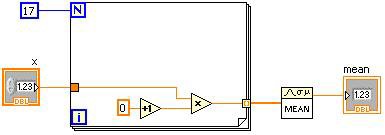
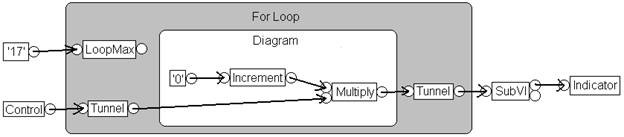
Abbildung 2: LabVIEW-G-Code und ein entsprechender DFIR-Graph
Abbildung 2 zeigt ein einfaches VI mit der anfänglichen DFIR-Darstellung. Bei der Erstellung eines DFIR-Graphen für ein VI handelt es sich um eine direkte Übersetzung des G-Codes, und die Knoten im DFIR-Graphen entsprechen in der Regel direkt den Knoten im G-Code. Im Verlauf der Kompilierung können DFIR-Knoten verschoben oder gespalten oder neue DFIR-Knoten hinzugefügt werden. Einer der Hauptvorteile der DFIR besteht darin, dass Merkmale wie die dem G-Code inhärente Parallelität aufrechterhalten werden. Im Gegensatz dazu ist die Parallelität im Drei-Address-Code viel schwieriger zu erkennen.
Die DFIR bietet zwei wesentliche Vorteile für den LabVIEW-Compiler. Zum einen entkoppelt die DFIR den Editor von der Compiler-Darstellung des VIs. Zweitens dient die DFIR als gemeinsamer Hub für den Compiler, der über mehrere Front- und Backends verfügt. Betrachten wir die einzelnen Vorteile im Detail.
Der DFIR-Graph entkoppelt den Editor von der Compiler-Darstellung
Vor der Einführung von DFIR verfügte LabVIEW nur über eine Darstellung des VIs, die sowohl vom Editor als auch vom Compiler genutzt wurde. Dadurch konnte der Compiler während der Kompilierung keine Änderungen an der Darstellung vornehmen, was wiederum die Durchführung von Compiler-Optimierungen erschwerte.

Abbildung 3: DFIR bietet einen Rahmen für die Codeoptimierung durch den Compiler
Abbildung 3 zeigt einen DFIR-Graphen für das zuvor vorgestellte VI. Dieser Graph zeigt einen weit fortgeschrittenen Kompilierprozess, nachdem der Code durch mehrere Transformationen zerlegt und optimiert wurde. Wie Sie sehen, unterscheidet sich dieser Graph wesentlich vom vorherigen Graphen. Zum Beispiel:
- Zerlegungstransformationen haben die Steuerungs-, Anzeige- und SubVI-Knoten entfernt und durch neue Knoten ersetzt – UIAccessor, UIUpdater, FunctionResolver und FunctionCall.
- Durch Loop Invariant Code Motion wurden die Inkrementier- und Multiplizierknoten außerhalb des Schleifenkörpers verschoben.
- Der Clumper hat einen Knoten des Typs „YieldIfNeeded“ in die For-Schleife integriert, wodurch der ausführende Thread die Ausführung mit anderen konkurrierenden Arbeitsobjekten teilt.
Transformationen werden in einem späteren Abschnitt ausführlicher behandelt.
Die DFIR-Zwischendarstellung dient als gemeinsamer Hub für mehrere Compiler-Frontends und -Backends
LabVIEW eignet sich für verschiedene Zielsysteme, die sich grundlegend voneinander unterscheiden können, z. B. ein x86-Desktop-PC und ein Xilinx-FPGA. In ähnlicher Weise stellt LabVIEW dem Benutzer verschiedene Berechnungsmodelle zur Verfügung. Neben der grafischen Programmierung in G bietet LabVIEW beispielsweise auch textbasierte Mathematik in MathScript. So entsteht eine Sammlung von Front- und Backends, die alle mit dem LabVIEW-Compiler funktionieren müssen. Die Verwendung der DFIR als gemeinsame Zwischendarstellung, die alle Frontends erzeugen und alle Backends nutzen, erleichtert die Wiederverwendung bei verschiedenen Kombinationen. So kann beispielsweise die Implementierung einer Optimierung für die Konstantenfaltung, die auf einem DFIR-Graphen ausgeführt wird, einmal geschrieben und auf Desktop-, Echtzeit-, FPGA- und Embedded-Zielsysteme angewendet werden.
DFIR-Zerlegungen
Nach der Übersetzung in DFIR durchläuft das VI zunächst eine Reihe von Zerlegungstransformationen. Das Ziel von Zerlegungstransformationen ist die Reduzierung oder Normalisierung des DFIR-Graphen. Die Zerlegung für unverbundene Ausgangstunnel beispielsweise findet Ausgangstunnel an Case- und Ereignisstrukturen, die nicht verbunden und als „Standard verwenden, wenn nicht verbunden“ konfiguriert sind. Die Transformation legt für diese Anschlüsse eine Konstante mit dem Standardwert ab und verbindet sie mit dem Anschluss, wodurch die Funktionsweise „Standard verwenden, wenn nicht verbunden“ im DFIR-Graphen explizit festgelegt wird. Bei nachfolgenden Compiler-Durchläufen werden dann alle Anschlüsse gleich behandelt und es wird davon ausgegangen, dass alle über verbundene Eingänge verfügen. In diesem Fall wurde die Eigenschaft „Standard verwenden, wenn nicht verbunden“ der Sprache durch die Reduzierung der Darstellung auf eine grundlegendere Form „wegkompiliert“.
Dieses Prinzip lässt sich auch auf komplexere Sprachfunktionen anwenden. So wird beispielsweise mithilfe der Zerlegungstransformation der Rückkopplungsknoten in Schieberegister auf einer While-Schleife reduziert. Bei einer anderen Zerlegung werden die parallelen For-Schleifen in Form mehrerer aufeinanderfolgender For-Schleifen mit zusätzlicher Logik implementiert, um Eingänge für die sequenziellen Schleifen in parallel ausführbare Teile aufzuteilen und die Teile anschließend wieder zusammenzufügen.
Eine neue Funktion in LabVIEW 2010, das SubVI-Inlining, wird ebenfalls als DFIR-Zerlegung implementiert. Während dieser Kompilierungsphase wird der DFIR-Graph der als „Inline“ gekennzeichneten SubVIs direkt in den DFIR-Graphen des Aufrufers integriert. Zusätzlich zur Vermeidung des Overheads eines SubVI-Aufrufs eröffnet das Inlining zusätzliche Optimierungsmöglichkeiten, indem Aufrufer und aufgerufenes Objekt in einem einzigen DFIR-Graphen zusammengefasst werden. Ein Beispiel hierfür ist dieses einfache VI, das das TrimWhitespace.vi von vi.lib aufruft.
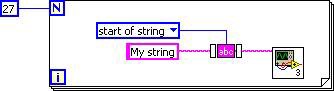
Abbildung 4: Beispiel eines einfachen VIs zur Demonstration von DFIR-Optimierungen
Das TrimWhitespace.vi wird in vi.lib folgendermaßen definiert:
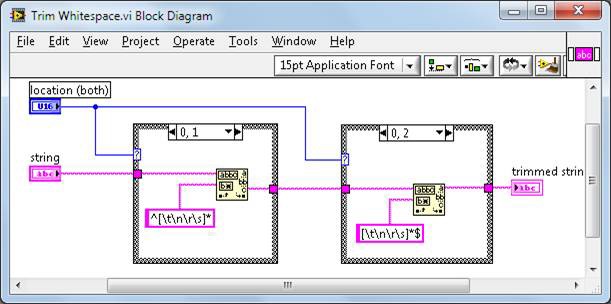
Abbildung 5: Blockdiagramm für TrimWhitespace.vi
Das SubVI wird inline in den Aufrufer eingefügt, wodurch ein DFIR-Graph entsteht, der dem folgenden G-Code entspricht.
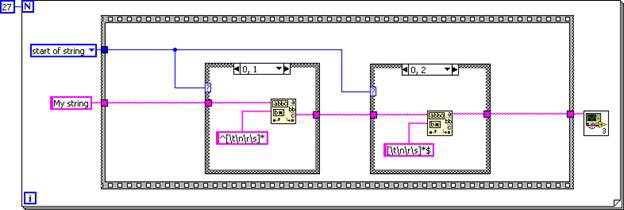
Abbildung 6: G-Code-Entsprechung für den DFIR-Graphen des inline eingefügten TrimWhitespace.vi
Nachdem das SubVI-Diagramm inline in das Aufruferdiagramm eingefügt wurde, kann der Code durch die Unreachable Code Elimination und Dead Code Elimination vereinfacht werden. Die erste Case-Struktur wird immer ausgeführt, während die zweite Case-Struktur nie ausgeführt wird.
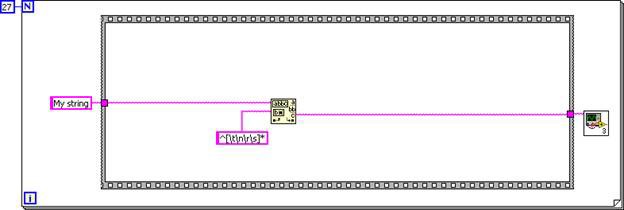
Abbildung 7: Die Case-Strukturen können entfernt werden, da die Eingangslogik konstant ist.
In ähnlicher Weise wird bei der Loop Invariant Code Motion die Funktion „Muster suchen“ aus der Schleife entfernt. Der endgültige DFIR-Graph entspricht dem folgenden G-Code.
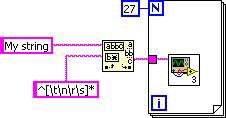
Abbildung 8: G-Code-Entsprechung für den endgültigen DFIR-Graphen
Da das TrimWhitespace.vi in LabVIEW 2010 per Standardeinstellung als „inline“ markiert ist, profitieren alle Clients dieses VIs automatisch von diesen Vorteilen.
DFIR-Optimierungen
Nachdem der DFIR-Graph sorgfältig zerlegt wurde, beginnen die DFIR-Optimierungsdurchläufe. Weitere Optimierungen werden später während der LLVM-Kompilierung durchgeführt. In diesem Abschnitt werden nur einige der vielen Optimierungen behandelt. Jede dieser Transformationen ist eine gängige Compiler-Optimierung, daher sollten weitere Informationen zu einer bestimmten Optimierung leicht zu finden sein.
Unreachable Code Elimination
Programmcode, der niemals ausgeführt werden kann, ist nicht erreichbar. Das Entfernen von nicht erreichbarem Programmcode verkürzt die Ausführungsdauer nicht direkt, es verkleinert jedoch den Code und verkürzt die Kompilierzeit, da der entfernte Code in nachfolgenden Kompilierdurchläufen nicht mehr kompiliert wird.
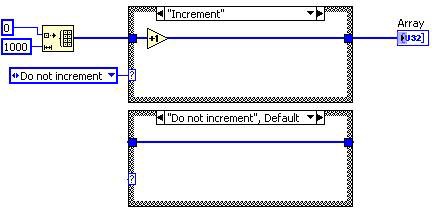
Vor der Unreachable Code Elimination

Nach der Unreachable Code Elimination
Abbildung 9: G-Code-Entsprechung für die DFIR-Zerlegung Unreachable Code Elimination
In diesem Fall wird das „Inkrement“-Diagramm der Case-Struktur nie ausgeführt, sodass die Transformation diesen Case entfernt. Da die Case-Struktur nur noch einen Case hat, wird sie durch eine Sequenzstruktur ersetzt. Durch die Dead Code Elimination werden später der Frame und die Enum-Konstante entfernt.
Loop Invariant Code Motion
Bei der Loop Invariant Code Motion wird Programmcode innerhalb des Schleifenkörpers identifiziert, der dann bedenkenlos aus der Schleife verschoben werden kann. Da der verschobene Code weniger oft ausgeführt wird, verbessert sich die Gesamtausführungsgeschwindigkeit.
Vor der Transformation Loop Invariant Code Motion | Nach der Transformation Loop Invariant Code Motion |
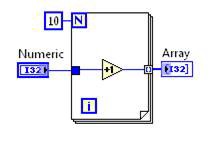
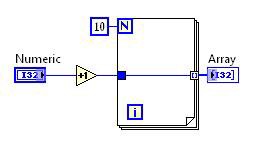
Abbildung 10: G-Code-Entsprechung für die DFIR-Zerlegung Loop Invariant Code Motion
In diesem Fall wird die Inkrementierung außerhalb der Schleife verschoben. Der Schleifenkörper bleibt bestehen, sodass das Array erstellt werden kann, die Berechnung aber nicht in jeder Iteration wiederholt werden muss.
Common Subexpression Elimination
Durch die Common Subexpression Elimination werden wiederholte Berechnungen erkannt, die Berechnung wird nur einmal durchgeführt und die Ergebnisse werden wiederverwendet.
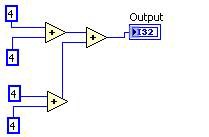
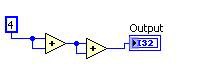
Vorher Nachher
Abbildung 11: G-Code-Entsprechung für die DFIR-Zerlegung Common Subexpression Elimination
Konstantenfaltung
Bei der Konstantenfaltung werden Teile eines Diagramms identifiziert, die während der Ausführung konstant sind und daher frühzeitig bestimmt werden können.
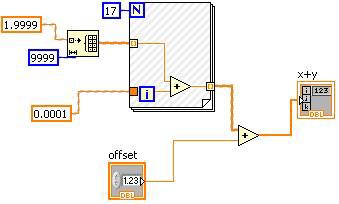
Abbildung 12: Die Konstantenfaltung kann im LabVIEW-Blockdiagramm dargestellt werden.
Die Hash-Markierungen im VI in Abbildung 12 zeigen den Bereich, der einer Konstantenfaltung unterzogen wurde. In diesem Fall kann die „Offset“-Steuerung keiner Konstantenfaltung unterzogen werden, der andere Operand der Plus-Funktion, einschließlich der For-Schleife, hat aber einen konstanten Wert.
Auflösung von Schleifen
Beim Auflösen einer Schleife wird der Schleifen-Overhead reduziert, indem der Schleifenkörper im erzeugten Programmcode mehrmals wiederholt wird und die Gesamtanzahl der Iterationen um den gleichen Faktor reduziert wird. Dadurch wird der Schleifen-Overhead reduziert und es ergeben sich Möglichkeiten für weitere Optimierungen, jedoch nimmt die Codegröße zu.
Dead Code Elimination
Toter Code ist Programmcode, der nicht benötigt wird. Das Entfernen von totem Programmcode beschleunigt die Ausführungsdauer, da der entfernte Code nicht mehr ausgeführt wird.
Toter Code wird in der Regel durch die Veränderung des DFIR-Graphen mithilfe von Transformationen erzeugt, die nicht direkt geschrieben wurden. Zum Beispiel: Bei der Unreachable Code Elimination wird festgestellt, dass die Case-Struktur entfernt werden kann. Dadurch wird toter Code „erzeugt“, der durch die Transformation Dead Code Elimination entfernt wird.
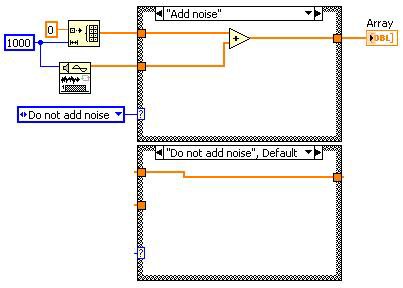
Vorher
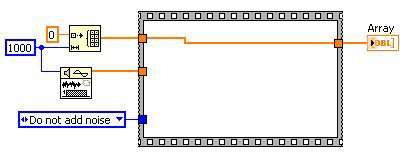
Nach der Unreachable Code Elimination
Nach der Dead Code Elimination
Abbildung 13: Durch die Dead Code Elimination kann die Menge des zu kompilierenden Codes reduziert werden.
Die meisten der in diesem Abschnitt behandelten Transformationen weisen solche Wechselbeziehungen auf. Bei Ausführung der einen Transformation ergeben sich unter Umständen Möglichkeiten für andere Transformationen.
DFIR-Backend-Transformationen
Nachdem der DFIR-Graph zerlegt und optimiert wurde, werden einige Backend-Transformationen ausgeführt. Bei diesen Transformationen wird der DFIR-Graph als Vorbereitung für die letztliche Reduzierung des DFIR-Graphen auf die LLVM-Zwischendarstellung evaluiert und annotiert.
Clumper
Der Clumping-Algorithmus erkennt Parallelitäten im DFIR-Graphen und gruppiert Knoten in Datenklumpen, die parallel ausgeführt werden können. Dieser Algorithmus ist eng mit dem LabVIEW-Ausführungssystem verknüpft, das kooperatives Multithread-Multitasking verwendet. Jeder der vom Clumper erzeugten Datenklumpen wird als einzelner Task im Ausführungssystem geplant. Knoten in Datenklumpen werden in einer festen, seriellen Reihenfolge ausgeführt. Durch die festgelegte Ausführungsreihenfolge jedes Datenklumpens kann der Inplacer Datenzuordnungen aufteilen, wodurch sich die Leistung erheblich verbessert. Der Clumper ist auch dafür verantwortlich, Yields in längere Operationen wie Schleifen oder I/O einzufügen, sodass diese Datenklumpen mit anderen Klumpen kooperativ Multitasking ausführen können.
Inplacer
Der Inplacer analysiert den DFIR-Graphen und erkennt, in welchen Fällen Datenzuordnungen wiederverwendet werden können und in welchen Fällen eine Kopie erstellt werden muss. Eine Verbindung in LabVIEW kann ein einfacher 32-Bit-Skalar oder ein 32-MB-Array sein. In einer Datenflusssprache wie LabVIEW ist es von entscheidender Bedeutung, Daten so oft wie möglich wiederzuverwenden.
Betrachten wir das folgende Beispiel (beachten Sie, dass die Fehlersuche des VIs deaktiviert ist, um die bestmögliche Leistung und einen geringeren Speicherbedarf zu erzielen).
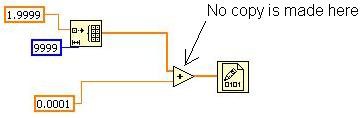
Abbildung 14: Einfaches Beispiel für den Inplaceness-Algorithmus
Dieses VI initialisiert ein Array, fügt jedem Element einen skalaren Wert hinzu und schreibt dieses in eine Binärdatei. Wie viele Kopien des Arrays sollten vorhanden sein? LabVIEW muss zunächst das Array erstellen, der Addiervorgang kann aber nur an diesem Array durchgeführt werden. Daher wird nur eine Kopie des Arrays benötigt, statt einer Zuordnung pro Verbindung. Bei einem großen Array kann das einen erheblichen Unterschied hinsichtlich Speicherbedarf und Ausführungsdauer bedeuten. In diesem VI erkennt der Inplacer diese Möglichkeit, „in place“ zu arbeiten, und konfiguriert den Addier-Knoten entsprechend.
Diese Funktionsweise von VIs lässt sich mithilfe des Tools „Pufferzuweisungen anzeigen“ unter „Tools»Profil“ prüfen. Das Tool zeigt keine Zuweisung für die Addierfunktion an, was bedeutet, dass keine Datenkopie erstellt wird und der Addiervorgang „in place“ stattfindet.
Dies ist möglich, weil kein anderer Knoten das ursprüngliche Array benötigt. Wenn das VI wie in Abbildung 15 dargestellt verändert wird, muss der Inplacer eine Kopie für die Addierfunktion erstellen. Das liegt daran, dass die zweite Funktion „In Binärdatei schreiben“ das ursprüngliche Array benötigt und nach der ersten Funktion „In Binärdatei schreiben“ ausgeführt werden muss. Mit dieser Änderung zeigt das Tool „Pufferzuweisungen anzeigen“ eine Zuweisung für die Addierfunktion an.
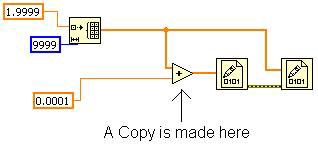
Abbildung 15: Beim Verzweigen der ursprünglichen Array-Verbindung wird eine Kopie im Speicher erstellt.
Zuteiler
Nachdem mithilfe des Inplacers ermittelt wurde, welche Knoten Speicherbereiche mit anderen Knoten gemeinsam nutzen können, wird die Zuteilung ausgeführt, um die für die Ausführung des VIs benötigten Zuteilungen zu erstellen. Dies wird an jedem Knoten und Anschluss implementiert. Anschlüsse, die direkt mit anderen Anschlüssen verbunden sind, verwenden Zuteilungen wieder, anstatt neue zu erstellen.
Codegenerator
Der Codegenerator ist die Komponente des Compilers, die den DFIR-Graphen in ausführbare Maschinenanweisungen für den Zielprozessor umwandelt. LabVIEW durchläuft jeden Knoten im DFIR-Graphen in Datenflussreihenfolge, und jeder Knoten ruft eine als GenAPI bezeichnete Schnittstelle auf, mit deren Hilfe der DFIR-Graph in eine sequenzielle Zwischensprache (intermediate language, IL) umgewandelt wird, die die Funktionalität des Knotens beschreibt. Die Zwischensprache bietet eine plattformunabhängige Möglichkeit, das Low-Level-Verhalten des Knotens zu beschreiben. Verschiedene Anweisungen in der Zwischensprache werden verwendet, um unter anderem arithmetische Operationen, das Lesen und Schreiben des Speichers sowie das Durchführen von Vergleichen und bedingten Verzweigungen zu implementieren. IL-Anweisungen können entweder auf den Arbeitsspeicher oder auf Werte in virtuellen Registern, die zum Speichern von Zwischenwerten dienen, angewendet werden. Beispiele für IL-Anweisungen sind GenAdd, GenMul, GenIf, GenLabel und GenMove.
In LabVIEW 2009 und älteren Versionen wurde diese Form der Zwischensprache direkt in Maschinenanweisungen (z. B. 80X86 und PowerPC) für die Zielplattform umgewandelt. LabVIEW verwendete einen einfachen One-Pass-Registerzuteiler, um virtuelle Register physischen Maschinenregistern zuzuordnen. Jede Zwischensprachenanweisung gab einen fest kodierten Satz bestimmter Maschinenanweisungen aus, um ihn auf der jeweiligen unterstützten Zielplattform zu implementieren. Dies geschah zwar äußerst schnell, dafür aber ad-hoc, erzeugte mangelhaften Code und ließ wenig Raum für Optimierungen. Die DFIR als plattformunabhängige High-Level-Darstellung unterstützt nur eine begrenzte Auswahl an Codetransformationen. Um alle Code-Optimierungen, die ein moderner Compiler durchführen kann, zu unterstützen, integrierte LabVIEW vor Kurzem eine Open-Source-Technologie eines Drittanbieters namens LLVM.
LLVM
Die Low-Level Virtual Machine (LLVM) ist ein vielseitiges, leistungsstarkes Open-Source-Compiler-Framework, das ursprünglich als Forschungsprojekt an der University of Illinois entwickelt wurde. Die LLVM ist aufgrund ihrer flexiblen, sauberen API und liberalen Lizenzierung inzwischen sowohl in der Wissenschaft als auch in der Industrie weit verbreitet.
In LabVIEW 2010 wurde der LabVIEW-Codegenerator dahingehend überarbeitet, dass er mithilfe der LLVM Zielmaschinencode erzeugte. Die bestehende LabVIEW-Zwischensprachendarstellung bot dafür einen guten Startpunkt, da nur etwa 80 Zwischensprachenanweisungen neu geschrieben werden mussten, statt der viel größeren Anzahl an von LabVIEW unterstützten DFIR-Knoten und -Funktionen.
Nach der Erstellung des Zwischensprachencode-Streams aus dem DFIR-Graphen eines VIs geht LabVIEW jede Zwischensprachenanweisung durch und erstellt eine entsprechende LLVM-Assembly-Darstellung. Nach verschiedenen Optimierungsdurchläufen verwendet es dann das LLVM-Just-in-time-Framework (JIT), um ausführbare Maschinenanweisungen im Speicher zu erstellen. Die LLVM-Maschinenverlagerungsinformationen werden in eine LabVIEW-Darstellung konvertiert, sodass das VI, auch wenn es auf der Festplatte gespeichert und an eine andere Basisadresse geladen wird, am neuen Speicherort korrekt ausgeführt werden kann.
Einige der gängigen Compiler-Optimierungen, für die LabVIEW die LLVM nutzt, sind:
- Instruction Combining
- Jump Threading
- Scalar Replacement of Aggregates
- Conditional Propagation
- Tail Call Elimination
- Expression Reassociation
- Loop Invariant Code Motion
- Loop Unswitching und Index Splitting
- Induction Variable Simplification
- Auflösung von Schleifen
- Global Value Numbering
- Dead Store Elimination
- Aggressive Dead Code Elimination
- Sparse Conditional Constant Propagation
Eine vollständige Erläuterung dieser Optimierungen würde den Rahmen dieses Artikels sprengen. Im Internet und in den meisten Lehrbüchern zu Compilern findet sich jedoch eine Fülle von Informationen dazu.
Interne Benchmarks haben gezeigt, dass die Einführung der LLVM zu einer durchschnittlichen Verkürzung der VI-Ausführungsdauer um 20 Prozent geführt hat. Die einzelnen Ergebnisse hängen von der Art der vom VI durchgeführten Berechnungen ab. Bei manchen VIs ist die Leistungsverbesserung noch größer, bei anderen bleibt die Leistung unverändert. Bei VIs beispielsweise, die die erweiterte Analysebibliothek nutzen oder auf andere Weise stark von Programmcode abhängen, der bereits in optimiertem C umgesetzt wurde, sind die Leistungsunterschiede kaum merklich. LabVIEW 2010 ist die erste Version von LabVIEW, die mit der LLVM arbeitet, und bietet daher noch viel ungenutztes Potenzial für zukünftige Verbesserungen.
DFIR und LLVM arbeiten Hand in Hand
Sie haben vielleicht bemerkt, dass einige dieser Optimierungen, wie z. B. die Loop Invariant Code Motion und Dead Code Elimination, der DFIR zugeschrieben werden. Bei manchen Optimierungsdurchläufen kann es vorteilhaft sein, sie mehrmals und auf verschiedenen Ebenen des Compilers auszuführen, da der Code in anderen Durchläufen möglicherweise so verändert wurde, dass sich dadurch neue Optimierungsmöglichkeiten ergeben. Zusammenfassend lässt sich festhalten, dass die DFIR zwar eine High-Level-Zwischendarstellung und die LLVM eine Low-Level-Zwischendarstellung ist, diese beiden jedoch Hand in Hand arbeiten, um den LabVIEW-Code für die Ausführung auf der verwendeten Prozessorarchitektur zu optimieren.