Host Memory Buffer Overview
Contents
- Background
- Host Memory Buffer Interface
- Application: High Speed Control Loops
- Application: Random Access Shared Memory
- Comparison with other Data Transfer Mechanisms
- Control Loop Performance
- Best Practices
- Feedback Appreciated
Host Memory Buffer (HMB) is a low-level shared memory interface that can enable high performance applications such as small payload control loops and large random access buffers. In CompactRIO's 17.0 release, we are debuting this feature with initial support on the cRIO-9068, sbRIO-9607, sbRIO-9627, sbRIO-9637, sbRIO-9651 (SOM). We plan to support more targets in future releases.
Background
To understand how this feature fits into the RIO architecture, it's important to understand the basic architecture:
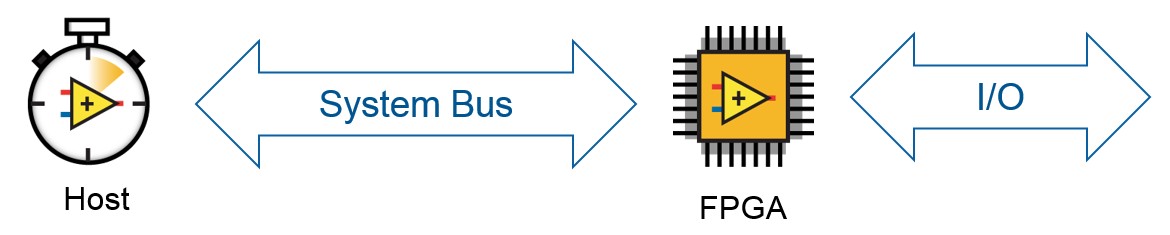
A recently released, typical CompactRIO target has a host that is running Linux RT that is connected to an FPGA via a system bus. The FPGA is what communicates with the I/O, either through C Series modules, FAMs, or onboard IO.
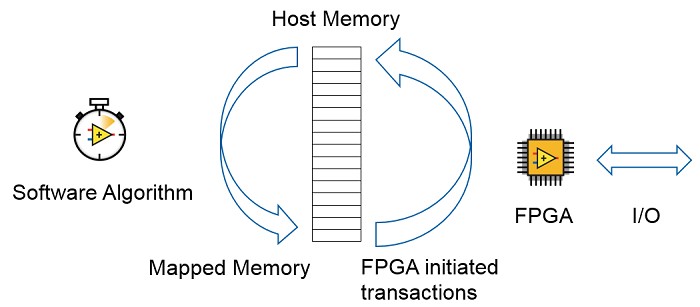
To transfer data between the FPGA and Host, the RIO driver provides two low-level channels that all other data transfer mechanisms are based off of: Controls/Indicators and DMA FIFOs. Control and Indicator transactions are host-initiated and are single point transfers, whereas DMA FIFOs are stream-based.

Another important piece of background is the RIO memory architecture:
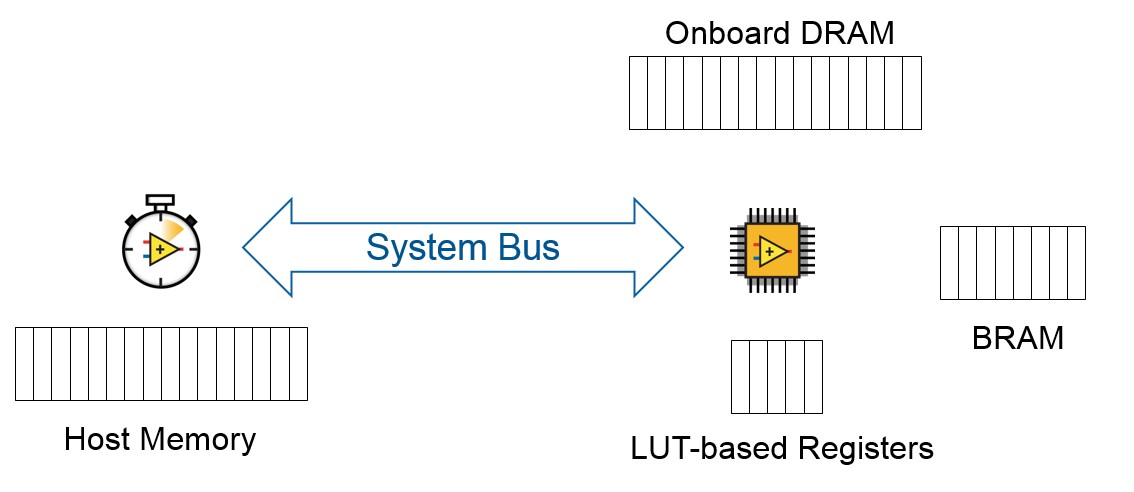
The FPGA application can create memory blocks implemented with LUTs, BRAM, or onboard DRAM (if the target supports it). However, the largest block of memory on the controller is used by the host.
Host Memory Buffer Interface
The Host Memory Buffer provides random access to a block of host memory, which gives access to all elements in the buffer at any time. On the FPGA side, the transfer mechanism optimizes latency instead of throughput: it transfers data across the system bus as quickly as possible instead of attempting to optimize bus bandwidth. On the host side, the interface provides low overhead access to memory, which allows high-performance access to the physical memory.
From the FPGA programming perspective, HMB uses the same API as onboard DRAMs. DRAM is an implementation option for FPGA memory in the LabVIEW project. One of the DRAM bank options on targets that support HMB is "Host Memory Buffer":
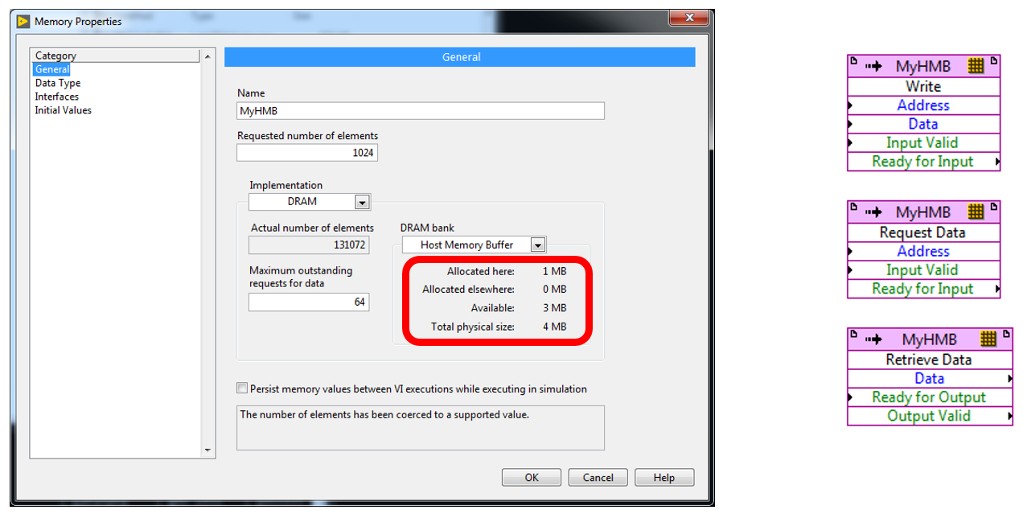
To access this block, use the three existing DRAM memory methods: Write, Request Data, and Retrieve Data. DRAM methods are used only in Single Cycle Timed Loops, so they implement the handshake interface that is common to other LabVIEW FPGA APIs.
Host Memory Buffers can be configured to up to 4MB of total size, and each memory block is coerced up to the nearest MB.
To access the HMB in LabVIEW Real-Time, we leverage a low-overhead mechanism called a data value reference (DVR). A DVR is similar to a pointer in text-based programming languages. There is a class of DVRs that are "External". Because Host Memory Buffer memory isn't managed by LabVIEW, it is an External Data Value Reference (EDVR). You can access the underlying data values through an In Place Element Structure. While executing inside of this structure, your application is directly operating on the memory.
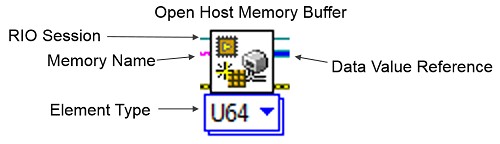
There is a new polymorphic VI on the FPGA interface palette called Open Host Memory Buffer. Its input terminals are the RIO Session, the memory block's name, and error terminals. The memory block's name is the name from the Memory Properties window from your LabVIEW project. For the best results, configure the polymorphic drop-down to the same data type as your memory block in your LabVIEW project.
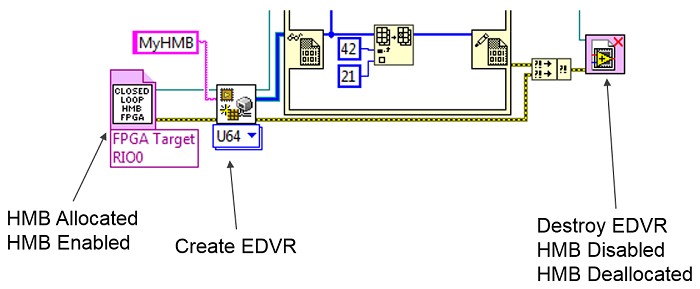
The memory that the HMB uses is allocated when a FPGA Interface session is opened. At that point, the FPGA's interface will be enabled. Multiple EDVRs can be opened and closed, and it will not affect the FPGA interface. The FPGA interface is normally disabled, and the memory is deallocated when the last session to the FPGA bitfile is closed.
Like onboard DRAM, Host Memory Buffer uses a request FIFO of a configurable depth, so if there is no FPGA Interface session open, the requests will be queued up until the FIFO is saturated. At that point, the Ready For Input terminals of Request Data and Write Data will stay deasserted (false) until a session is opened. You might encounter this behavior if you download a bitfile to flash, for example.
C API
Attached to this document is hmb_c_api_extension.zip, which contains the additional files needed to use Host Memory Buffer in conjunction with the FPGA Interface C API. This ZIP folder also contains a small example showing how to access Host Memory Buffer from RT in C.
Application: High Speed Control Loops
One of the motivations for this feature is high-speed control loops. A typical control application will have real-world inputs arriving at the FPGA and some algorithm that processes those inputs to determine the outputs. The highest performance loops are completely within the FPGA, but for many applications the control algorithm needs to happen on the RT processor.
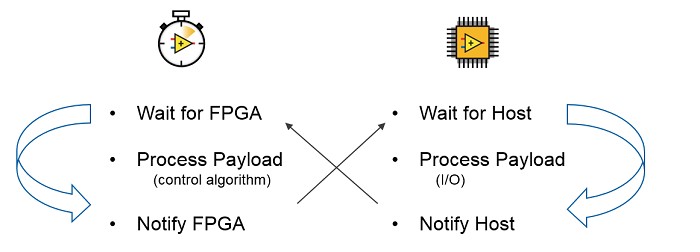
A key metric of the performance of these applications is how quickly the round trip from input to output takes. Common problems for these types of applications include:
- The average loop rate isn't fast enough
- The worst case loop rate isn't fast enough (too much jitter)
- FIFO methods have too much latency
- Controls/Indicators have too much latency and/or consume too much FPGA resources
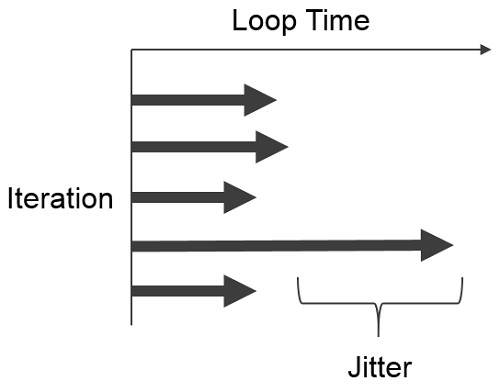
Reducing jitter is a common part of developing in RT. Jitter is the difference between the desired loop rate (or the average loop rate) and the worst case loop rate. There are many sources of jitter on an RT system, and there are many ways to reduce the jitter of your application. These include:
- Elevating the priority of time-critical loops on your time loops and timed sequences
- Setting the core affinity on your timed loops and timed sequences
- Set the system CPU pool
- Avoiding sleeps, interrupts, and driver calls inside the performance sensitive parts of your application
HMB provides an API that can be leveraged for very high performance control loops. Accessing the Host Memory Buffer doesn't invoke any driver calls, which avoids significant overhead. A drawback of this approach is that the user application is responsible for handling all timing, locking, copying, and buffering. If there is a bug in your application, you may introduce silent data corruption errors that can be difficult to find.
Control Loop Notification
There are two types of notifications that are necessary in a control loop such as this one. One is that the FPGA needs to notify the RT application that there is a new block of input data to process. The other is that the RT application needs to notify the FPGA that there is a new block of output data to send.
FPGA to Host notification can be accomplished through:
- FPGA IRQ
- This is great for minimizing CPU usage
- The context switch takes time
- Polling an FPGA Indicator
- This will consume a lot of CPU
- The response time is better
- Polling a HMB value
- This will consume a lot of CPU
- The response time is the best
If your goal is purely minimizing response time, then having RT poll memory will be the best option.
Host to FPGA notification can be accomplished through:
- Writing to FPGA Controls
- The associated driver calls can introduce latency
- FPGA polling a HMB value
- This is highly deterministic but consumes DMA bandwidth
- FPGA timed wait with HMB read
- The FPGA waits for fixed tick count while RT completes its algorithm
- The FPGA reads the HMB to verify the host has completed the algorithm by the deadline
Use FPGA polling if you want to execute as fast as possible; use FPGA timed wait if your application needs a more constant control period.
Application: Random Access Shared Memory
Another area that can benefit from utilizing HMB are random access FPGA memory applications. A problem that some RIO customers face is that they need FPGA memory space to store data for processing. Sometimes they don't have enough BRAM space on their target or they don't have access to onboard DRAM. One option would be to store their data on the host using a DMA FIFO, but the customer can't afford the extra CPU usage.
One area that these types of problems occur in are vision applications. The frame buffer the FPGA needs to process can be quite large and transferring it back and forth between the RT application and FPGA can be computationally expensive.
HMB addresses this problem by allowing the FPGA application to access host memory for storing data. Conveniently, it uses exactly the same interface as onboard DRAM, which simplifies porting applications. FPGA interactions with the HMB requires zero CPU cycles, so it doesn't increase CPU loading.
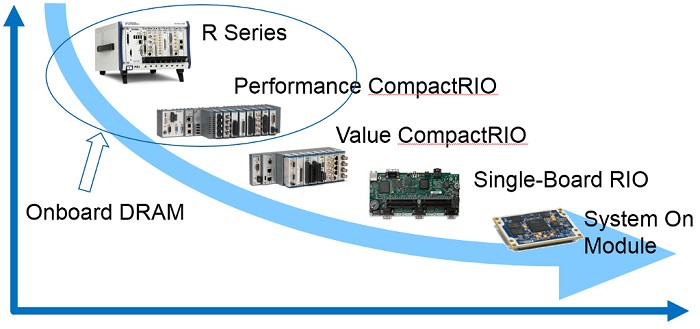
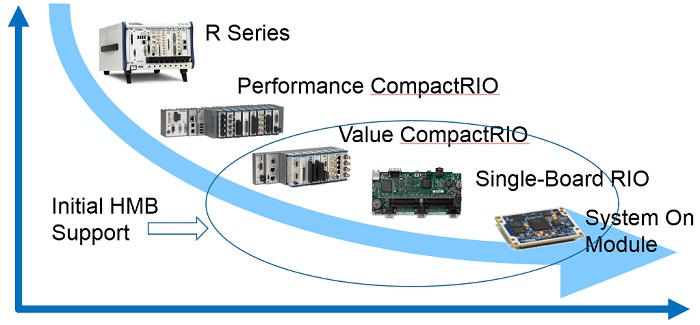
The CompactRIO product spectrum ranges from high-performance R Series and CompactRIO down to the very configurable single-board RIOs and SOMs. Often an application will be initially developed using hardware from the high performance part of this spectrum and will be migrated to the value and configurability side of the spectrum for deployment. Applications that are leveraging onboard DRAM are difficult to port to the value and configurability side of the spectrum because only the high performance products have DRAM.
By utilizing the same memory interface as onboard DRAM, porting applications from the left side of this curve to the right side of this is a much smoother process.
Comparison with other Data Transfer Mechanisms
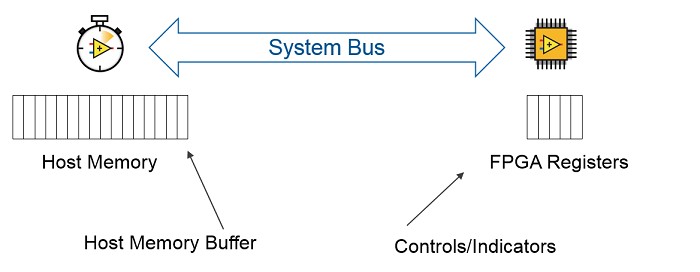
Controls / Indicators
Controls and Indicators can fill a similar use case to HMB. A key difference in their implementation is where the memory is stored. Controls and Indicators are stored in FPGA registers, which consumes FPGA space but allows for fast FPGA access to them. Host Memory Buffer is stored on the other side of the system bus—it doesn't consume FPGA resources, but it will take additional time to access it.
DMA FIFOs
A Host Memory Buffer can also fill a similar use case to DMA FIFOs. There are several important differences in the implementation. For instance, a DMA FIFO (FPGA to Host) allows the user to queue data into a buffer that is transferred to host memory at some point in the future (or when the FPGA invokes the flush method). The host is notified by some mechanism (possibly interrupt based or polling), and the host copies the sequential data out of the FIFO buffer into their application.
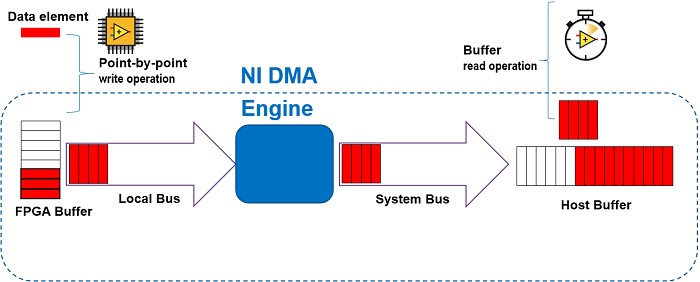
In contrast, in an HMB application, read and write requests get stored in a request FIFO where each individual element will immediately transfer to host memory. There is no attempt to coalesce requests; it will send each element as a single read or write to host memory. On the host side, the RT application may access whichever elements they choose though the EDVR interface.
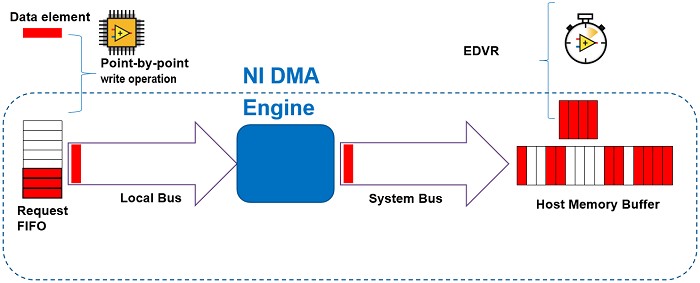
As a result of these implementation differences, FIFOs tend to perform better than HMB with respect to throughput because the system and local bus utilization is more efficient. On the other hand, HMB performs better than FIFOs with respect to latency because data can be transferred much quicker.
Control Loop Performance
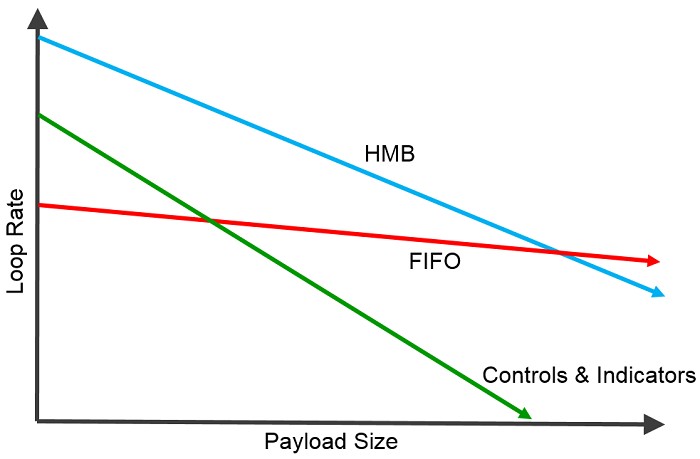
There are many factors that can affect overall control loop performance for specific instances. When you look at the data transfer mechanism in isolation, the best performance is largely determined by payload size. For small payload sizes, the latency and jitter of your transfer mechanism will be the dominating factor of your loop rate, so latency optimized transfer mechanisms will outperform throughput optimized transfer mechanisms. As the payload size increases to the neighborhood of 100-200 elements, DMA FIFOs will outperform an implementation using HMB.
Best Practices
Pipelining Memory Requests on FPGA
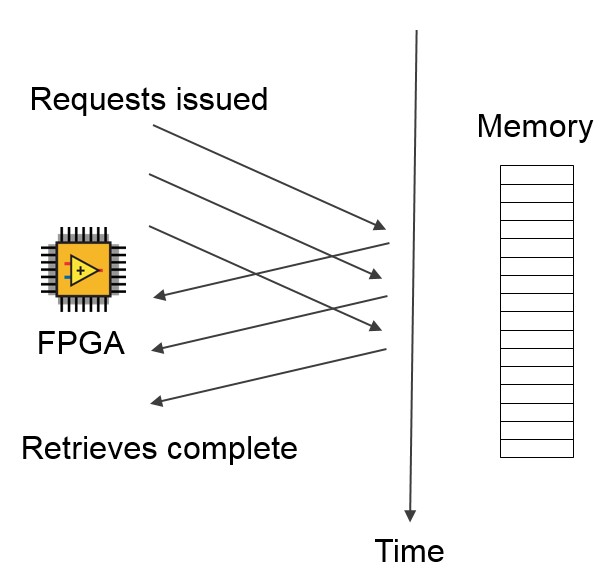
The FPGA is capable of issuing requests to memory very quickly, but it can take some time for those requests to complete. For maximum throughput, keep issuing memory access requests while your current request is in flight, instead of waiting to issue another request until the current request/retrieve pair completes.
Data Copies
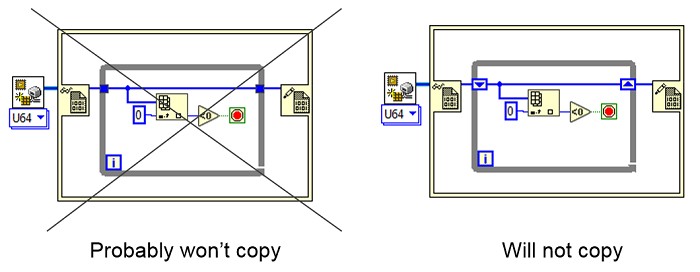
Whenever you are optimizing LabVIEW's performance, it's important to avoid memory copies to avoid the overhead of unnecessarily copying data. With EDVRs, it's not only inefficient, but you may accidentally introduce a situation where you are no longer working with the actual data: you will be working on a copy of the data. To avoid copies, avoid branching the data wire and use shift registers instead of loop tunnels:
Memory Barriers
One of the things that a driver will usually do for you is abstract away hardware peculiarities on your system. HMB doesn't have driver calls inside the In Place Element Structure, so as a result, you may be exposed to some confusing behavior. One confusing behavior you may encounter is that the processor on Zynq has a memory consistency model that allows the processor to speculatively execute case statements and reorder memory accesses. In many cases, this won't affect your application, but sometimes your algorithm will have specific ordering requirements.
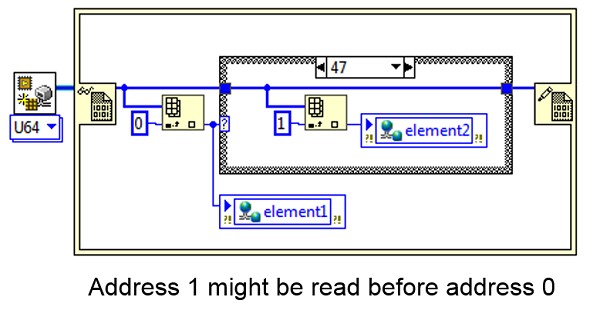
In the above example, the program clearly indicates that it wants address 0 to be read before it reads address 1. However, the processor is legally allowed to read them in the reversed order. This could create a very confusing intermittent data error.
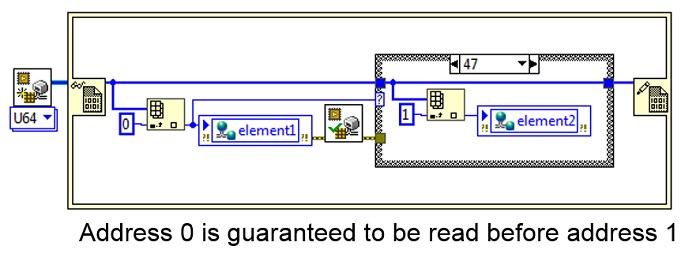
A solution to this problem is to execute a memory barrier. A memory barrier is an instruction to the processor that all memory accesses prior to the memory barrier must execute before memory accesses afterward. They can be used to dictate strict ordering requirements to your memory accesses.
Use Memory Barrier.vi whenever you have strict ordering requirements on your HMB memory accesses:
Bus Usage
The DMA interface is a shared resource between HMB, FIFOs, and the Scan Engine. To minimize performance impact on other DMA-based processes in your system, avoid unnecessary polling across the system bus. This means if one part of your application will poll something, that thing should be on the same side of the system bus in order to reduce bus utilization—for example, it's better for the FPGA to poll Controls and Indicators because they are implemented using registers.
Data Width
All onboard DRAM interfaces specify a "Maximum Data Width". This dictates the element stride in memory, which limits the data types that are valid to use as the element data type. Regardless of the width of the data type that you choose for onboard DRAM or Host Memory Buffer, this will not change the element stride.
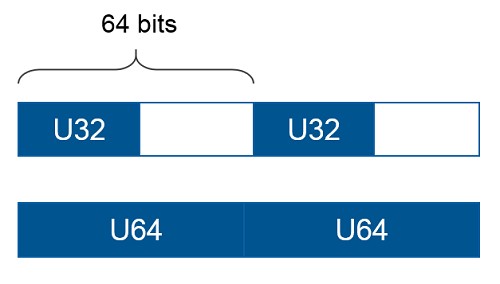
The Maximum Data Width for Host Memory Buffer is 64 bits, which means that the most efficient use of memory will be to always use 64 bit data types for HMB.
Out of Range Accesses
Reading or writing to addresses beyond the size of your memory block can have very confusing behavior. Always be mindful of how many elements are allocated to your memory block. By enabling error terminals on your memory methods, you can detect out of bounds memory accesses.
Feedback Appreciated
NI R&D has many competing demands. Host Memory Buffer was added as a CompactRIO 17.0 feature because of aggregated customer requests and feedback from specific customers. We hope you continue to help us improve our products by giving us valuable feedback of how we can better meet your needs as you are trying to solve your engineering challenges. There are always ways that a feature can be improved and your feedback will help us prioritize these improvements. To provide feedback, please contact customerservice@ni.com and reference this White Paper. Thank you.
Downloads

Requirements
Software
Driver: CompactRIO Device Drivers December 2017, FPGA Interface C API 17.0
Language(s): C
Hardware
Hardware Group: CompactRIO